吴恩达课程系列
1-3监督学习【监督学习的定义,监督学习的分类(回归与分类)】
1-4无监督学习【无监督学习的定义,无监督学习问题的分类(聚类/信号分离/降维)】
2-1模型描述【如何描述一个模型(用一些符号),单变量线性回归是什么?】
2-2~2-4代价函数【代价函数的数学定义、代价函数的直观理解】
2-6 梯度下降知识点总结
回顾2-5

其中\(\alpha\)是学习速率(learning rate,也可以叫学习率),它控制了“下山的步长”,即以多大的幅度去更新参数\(\theta_0,\theta_1\)
为了更加直观并且易于理解的解释,现在简化成:
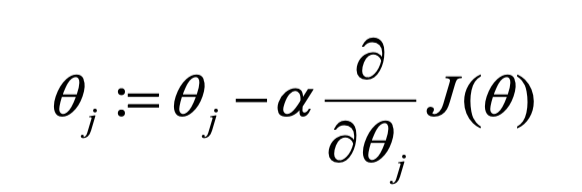
关于【导数项】的解释:
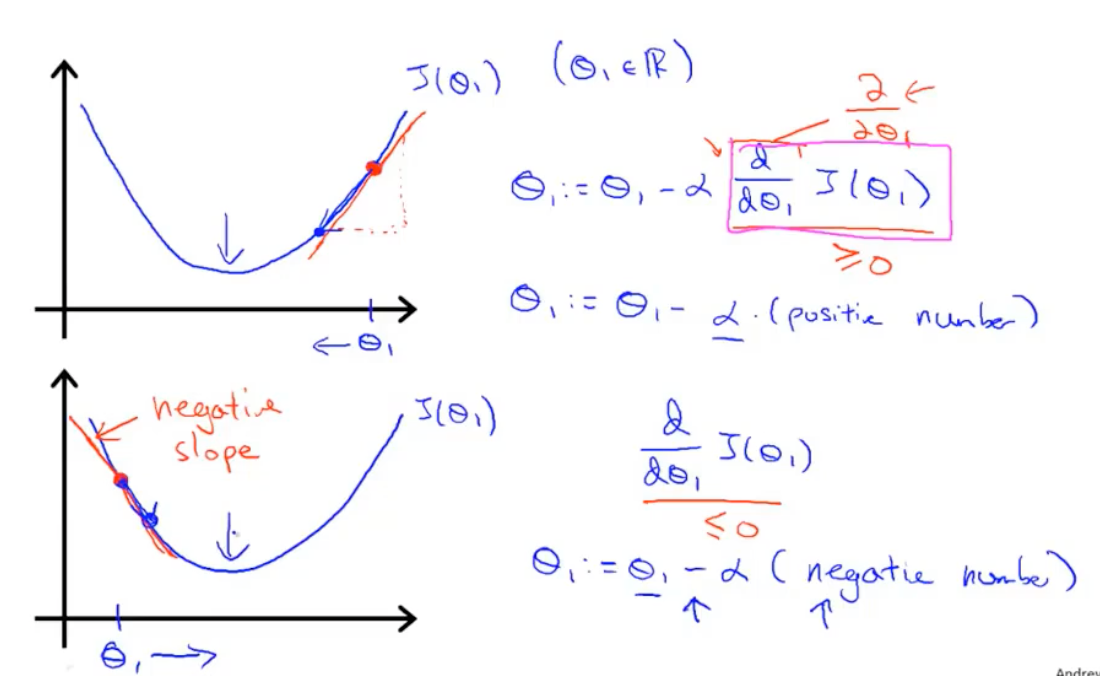
关于\(\alpha\)(学习率)的解释:
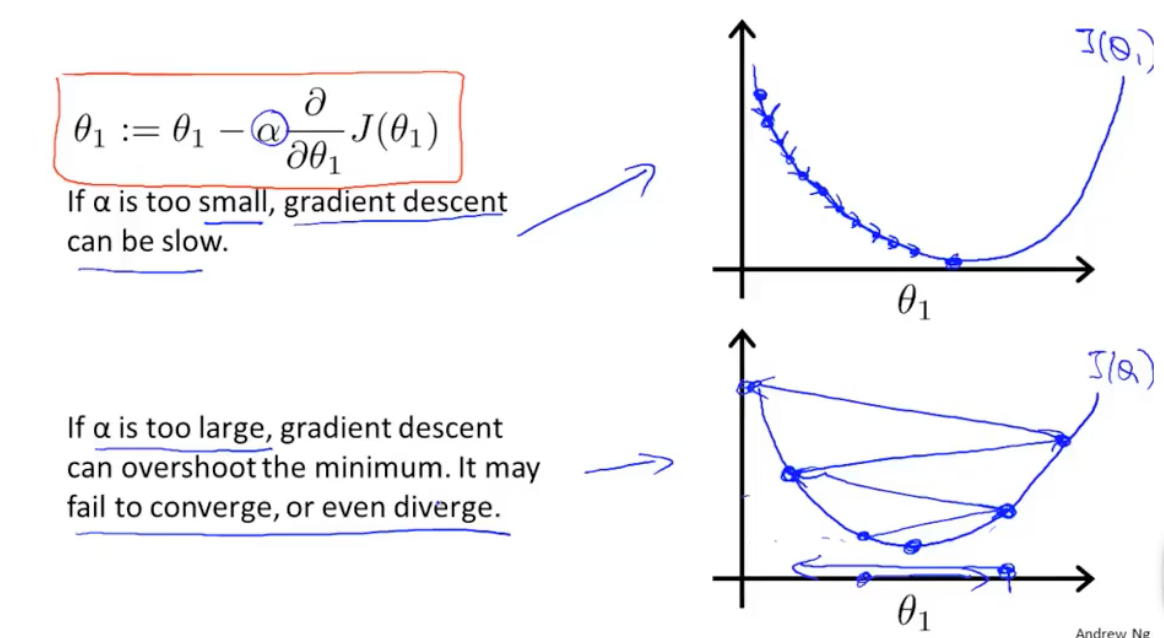
学习率太小会导致每次参数更新的幅度非常小,这意味着算法需要进行非常多次迭代才能达到最小值点。这会显著增加训练时间,使得算法效率低下。虽然学习率小有助于避免跳过全局最小值,但如果在目标函数表面存在平坦区域或狭窄的峡谷,算法可能会因为步长太小而难以逃脱这些区域,从而陷入局部最小值,无法找到更好的解。在接近最小值点时,由于每次更新都很小,算法可能会在最小值点附近来回振荡,难以精确收敛。
学习率太大可能导致每次更新的步长过大,直接越过最小值点,使得算法在最小值点附近来回跳跃,无法稳定收敛。更严重的情况下,目标函数的值可能会在每次迭代中不断增大,导致算法发散,根本找不到最小值。
如果刚开始选择的值比较接近局部最优解呢?(已经几乎达到收敛的状态,比如导数项接近等于0)?
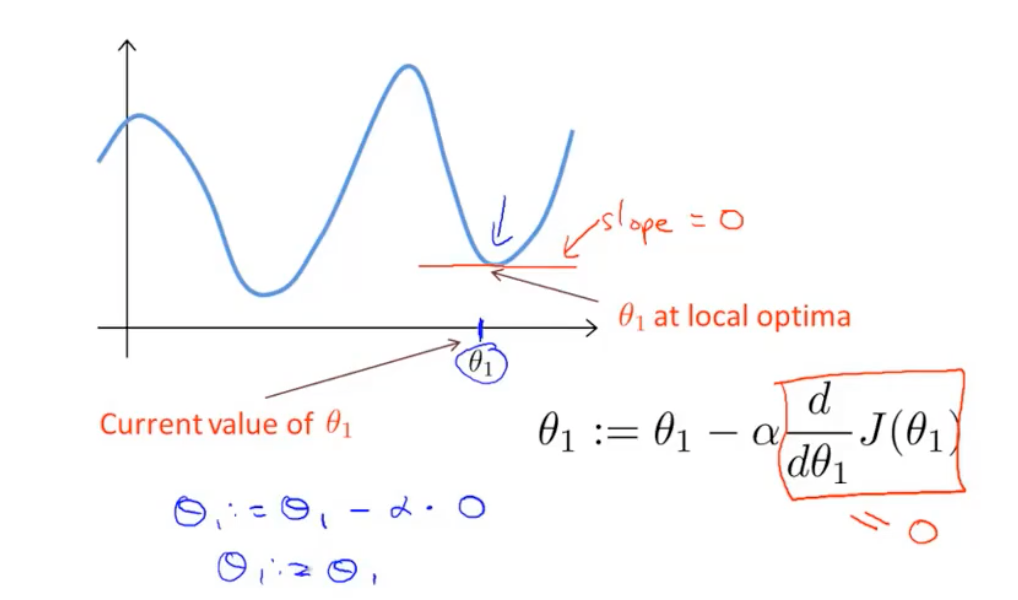
另外还要注意一点:当梯度下降接近局部最小值时,步长会自动变小,因此不需要随着时间的推移减少学习率。
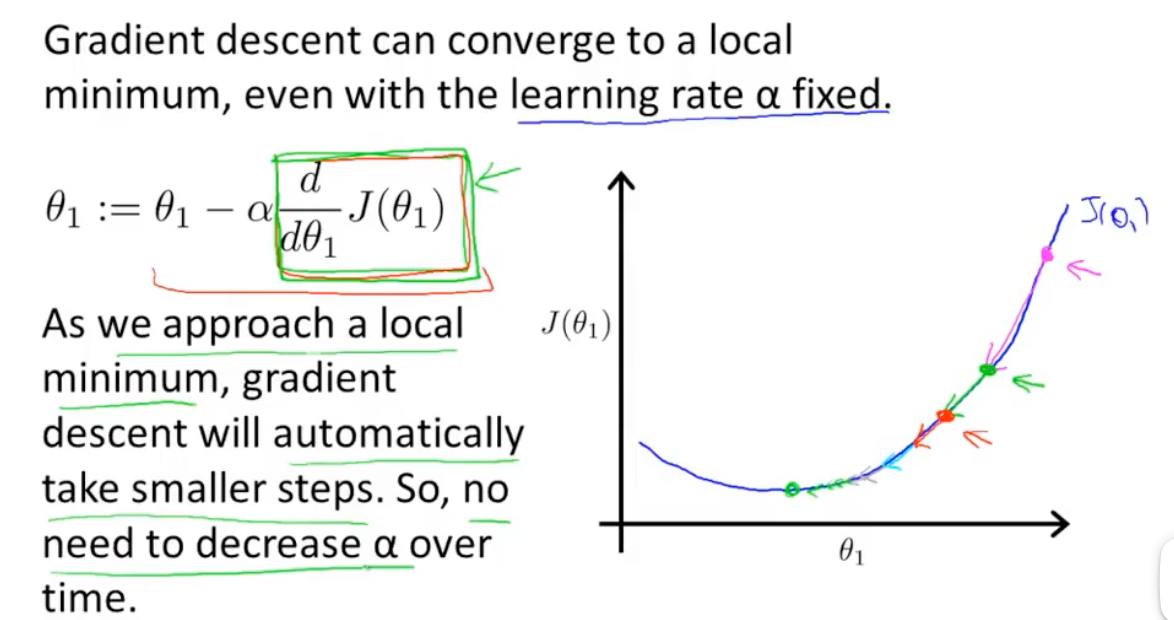
梯度下降的核心是利用导数(或者更准确地说是梯度,多维导数)来指引参数更新的方向。 越接近局部最优解(无论是全局的还是局部的),导数(梯度)的值会越来越接近于零。 这是因为局部最优解通常是目标函数的一个“平坦”区域,在这些区域,切线的斜率(即导数)趋近于零。
所以,梯度下降利用梯度指引参数更新,梯度的大小和方向反映了当前点与最优解的距离。越接近最优解,函数越平坦,梯度越接近零。这是一个优美的数学机制,也是机器学习中许多算法(如神经网络训练)的基石。