1.有序数组找数
- 可以是有序数组找某个数,找到返回True,没找到返回False
- 可以是有序数组(没有重复的数),找到某个数的位置
下面代码完成的功能是上面第二个要求:分别给出了二分写法和暴力写法,以及对数器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
public class FindNumber {
// 二分法找(在不重复的数组中)
public static int find(int[] arr, int num) {
int l = 0, r = arr.length - 1;
while (l <= r) {
int m = l + ((r - l)>> 1);
if (arr[m] == num) {
return m;
} else if(arr[m] < num) {
l = m + 1;
} else {
r = m - 1;
}
}
return -1;// 没找着
}
// 暴力解法
public static int find2(int[] arr, int num) {
for (int i = 0;i < arr.length;i++) {
if (num == arr[i]) return i;
}
return -1;
}
// 产生数组(不可重复)
// 长度[0, maxLen-1]
// 值的范围[0, maxValue - 1]
public static int[] randomArrNoRepeat(int maxLen, int maxValue) {
int len = (int)(Math.random() * maxLen);
int[] ans = new int[len];
Set<Integer> set = new HashSet<>();
int i = 0;
while (i < len) {
int v = (int)(Math.random() * maxValue);
if (!set.contains(v)) {
set.add(v);
ans[i] = v;
i++;
}
}
return ans;
}
public static void main(String[] args) {
int maxLen = 5;
int maxValue = 1000;
int testTime = 100000;
for (int i = 0;i < testTime;i++) {
int[] arr = randomArrNoRepeat(maxLen, maxValue);
if (arr.length == 0) continue;
// 数组排序
Arrays.sort(arr);
// 要找的数是不是来自于原数组(上帝视角)
boolean isFromOri = Math.random() < 0.5 ;
int target;
if (isFromOri) {
// index_ 取值范围: [0,arr.length-1]
int index_ = (int) (Math.random() * arr.length);
target = arr[index_];
} else {
// 随机生成一个数 范围超过maxValue 或者小于 maxValue
// 大于maxValue
target = (int)(Math.random() * 10 ) + maxValue;
}
// 暴力解法
int ans2 = find2(arr, target);
// 二分法
int ans1 = find(arr, target);
if (ans1 != ans2) {
System.out.println("出错了!!!");
System.out.println(Arrays.toString(arr));
System.out.println("target = " + target);
System.out.println("ans1 = " + ans1);
System.out.println("ans2 = " + ans2);
break;
}
}
}
}
2.有序数组中找到大于等于num最左的位置
暴力解法+二分解法+对数器都如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
import java.util.Arrays;
public class FindNumMostLeft {
// 有序数组中找到大于=num最左的位置
public static int[] randomArrayRepeat(int maxLen, int maxValue) {
// 长度范围[1, maxLen]
int len = (int)(Math.random() * maxLen) + 1;
int[] arr = new int[len];
for (int i = 0;i < len;i++) {
arr[i] = (int)(Math.random() * maxValue);
}
return arr;
}
public static int findNumLeft(int[] arr, int num) {
int l = 0, r = arr.length - 1;
int ans = -1;
while (l <= r) {
int m = l + ((r - l) >> 1);
if(arr[m] >= num) {
ans = m;
r = m - 1;
}else {
l = m + 1;
}
}
return ans;
}
// 暴力解法
public static int findNumLeft2(int[] arr, int num) {
int ans = -1;
for (int i = arr.length - 1;i >= 0;i--) {
if (arr[i] >= num) ans = i;
}
return ans;
}
public static void main(String[] args) {
int maxLen = 50;
int maxValue = 30;
int testTime = 100000;
for (int i = 0;i < testTime;i++) {
int[] arr = randomArrayRepeat(maxLen, maxValue);
// 数组排序
Arrays.sort(arr);
// 要找的数是不是来自于原数组(上帝视角)
boolean isFromOri = Math.random() < 0.5 ;
int target;
if (isFromOri) {
// index_ 取值范围: [0,arr.length-1]
int index_ = (int) (Math.random() * arr.length);
target = arr[index_];
} else {
// 随机生成一个数 范围超过maxValue 或者小于 maxValue
// 大于maxValue
target = (int)(Math.random() * 10 ) + maxValue;
}
int ans1 = findNumLeft(arr, target);
int ans2 = findNumLeft2(arr, target);
if (ans1 != ans2) {
System.out.println("出错了!!!");
System.out.println(Arrays.toString(arr));
System.out.println("target = " + target);
System.out.println("ans1 = " + ans1);
System.out.println("ans2 = " + ans2);
break;
}
}
}
}
以此类推,有序数组中找到小于等于num的最右的位置也可以完成。
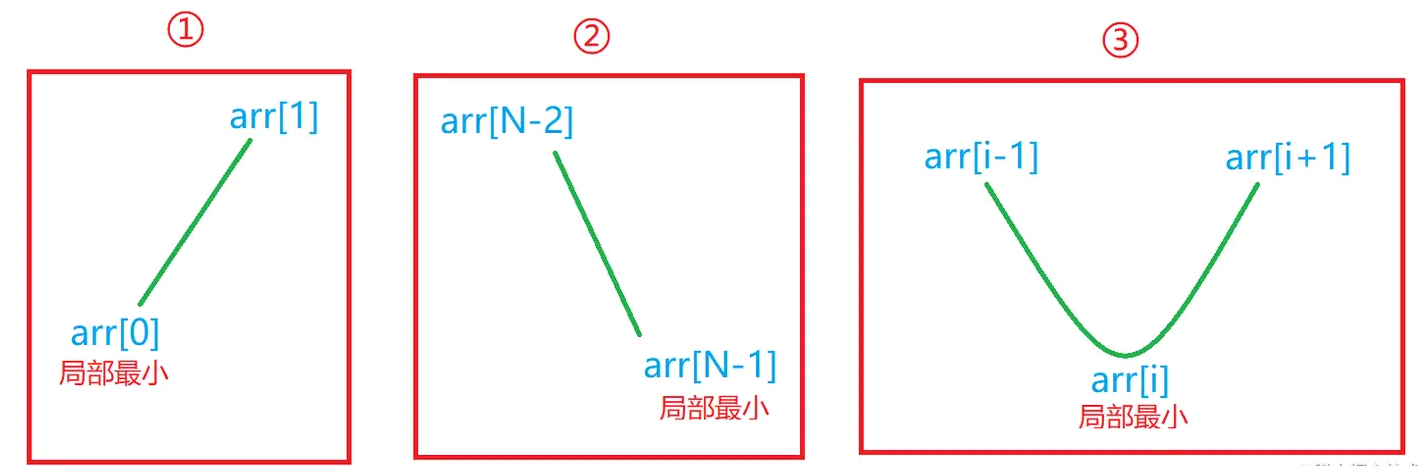
3.局部最小值位置
给定无序数组arr,已知arr中任意两个相邻的数都不相等,只需要返回arr中任意一个局部最小值出现的位置即可。
- 定义局部最小的概念:
- arr长度为1时,arr[0]是局部最小;
- arr的长度为N(N>1)时,如果arr[0] < arr[1],那么arr[0]是局部最小;
- 如果arr[N-1]<arr[N-2],那么arr[N-1]是局部最小;
- 如果0<i<N-1,既有arr[i] < arr[i-1],又有arr[i] < arr[i + 1],那么arr[i]是局部最小。
题目链接(牛客网):https://www.nowcoder.com/questionTerminal/bcddaae08d7349f5886c1ed40de66d8d
N>1时,也就是下图中的三种情况
贴出这道题的牛客的解法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import java.util.*;
import java.io.*;
// 注意类名必须为 Main, 不要有任何 package xxx 信息
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StreamTokenizer in = new StreamTokenizer(br);
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
while (in.nextToken() != StreamTokenizer.TT_EOF) {
int n = (int) in.nval;// 读入数组大小
in.nextToken();
int[] arr = new int[n];
// 读入数组每个元素
for (int i = 0; i < n; i++) {
arr[i] = (int)in.nval;
in.nextToken();
}
out.println(findLocalMin(arr));
}
out.flush();
br.close();
out.close();
}
public static int findLocalMin(int[] arr) {
if (arr == null) return -1;
int len = arr.length;
if (len == 0) return -1;
// 数组中至少1个元素
if (len == 1 || arr[0] < arr[1]) return 0;
if (arr[len - 1] < arr[len - 2]) return len - 1;
int l = 0, r = len - 1;
while (l < r - 1) { // l...r位置上至少3个数
int m = l + ((r - l) >> 1);
if (arr[m] < arr[m - 1] && arr[m] < arr[m + 1]) {
return m;
} else if (arr[m] > arr[m - 1]) {
r = m - 1;
} else {
l = m + 1;
}
}
// 循环出来的时候,l..r范围上最多2个数
return arr[l] < arr[r] ? l : r;
}
}
关于处理ACM的输入,可以参考下面的模版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public static void main(String[] args) throws IOException {
// 把文件里的内容,load进来,保存在内存里,很高效,很经济,托管的很好
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 一个一个读数字
StreamTokenizer in = new StreamTokenizer(br);
// 提交答案的时候用的,也是一个内存托管区
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
while (in.nextToken() != StreamTokenizer.TT_EOF) { // 文件没有结束就继续
// n,二维数组的行
int n = (int) in.nval;
in.nextToken();
// m,二维数组的列
int m = (int) in.nval;
// 装数字的矩阵,临时动态生成
int[][] mat = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
in.nextToken();
mat[i][j] = (int) in.nval;
}
}
out.println(maxSumSubmatrix(mat, n, m));
}
out.flush();
br.close();
out.close();
}
如果想书写关于这道题的对数器,参考下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import java.util.Arrays;
public class FindLocalMin {
public static void main(String[] args) {
// int[] arr = {1};
// System.out.println(findLocalMin(arr));
int maxLen = 10;
int maxValue = 20;
int testTime = 100000;
System.out.println("测试开始!");
for (int i = 0;i < testTime;i++) {
int[] arr = randomArray(maxLen, maxValue);
int ans = findLocalMin(arr);
if (!check(arr, ans)) {
System.out.println("出错了!");
System.out.println(Arrays.toString(arr));
System.out.println("ans = " + ans);
}
}
System.out.println("测试结束!");
}
// 验证方法
public static boolean check(int[] arr, int ans) {
if (arr == null || arr.length == 0) return ans == -1;
if (arr.length == 1) return ans == 0;
if (ans == 0) return arr[0] < arr[1];
if (ans == arr.length - 1) return arr[ans] < arr[ans - 1];
return arr[ans - 1] >= arr[ans] && arr[ans + 1] >= arr[ans];
}
// 生成随机数组,对数器
public static int[] randomArray(int maxLen, int maxValue) {
int len = (int) (Math.random() * maxLen);
if (len == 0) return null;
int[] arr = new int[len];
int i = 1;
arr[0] = (int) (Math.random() * maxValue);
while (i < len) {
int t = (int) (Math.random() * maxValue);
if (t != arr[i - 1]) {
arr[i] = t;
i++;
}
}
return arr;
}
public static int findLocalMin(int[] arr) {
if (arr == null) return -1;
int len = arr.length;
if (len == 0) return -1;
// 数组中至少1个元素
if (len == 1 || arr[0] < arr[1]) return 0;
if (arr[len - 1] < arr[len - 2]) return len - 1;
int l = 0, r = len - 1;
while (l < r - 1) { // l...r位置上至少3个数
int m = l + ((r - l) >> 1);
// System.out.println("m = " + m);
if (arr[m] < arr[m - 1] && arr[m] < arr[m + 1]) {
return m;
} else if (arr[m] > arr[m - 1]) {
r = m - 1;
} else {
l = m + 1;
}
}
// 循环出来的时候,l..r范围上最多2个数
return arr[l] < arr[r] ? l : r;
}
}
上面这道局部最小值的题目,其实可以看出:二分不一定要求数组是有序的!!
4.什么是常数操作?
常数操作是指执行时间与输入数据量无关的操作。
在算法和数据结构中,我们用大O表示法来分析操作的效率。如果一个操作的执行时间是固定的,不随问题规模 n 的变化而变化,我们就可以将其标记为 O(1),也就是常数时间复杂度。
例如:假设有一个数组 arr,它有 n 个元素。
常数操作的例子:
- 访问数组中的第一个元素:
arr[0] - 访问数组中的第 i 个元素:
arr[i] - 给一个变量赋值:
int a = 10; - 进行一次简单的算术运算:
a = b + 5;
无论数组有多大(n=100 还是 n=1000000),完成这些操作所需要的时间都是基本相同的,因此它们都是常数操作。
以下是一些常见的常数时间操作:
- 对变量赋值:
int x = 10;String name = "Alice";
- 算术运算:
int sum = a + b;int result = 2 * 10 / 5;
- 访问数组中的元素:
int value = arr[i];arr[j] = 20;
- 访问哈希表(Hash Map)中的元素:
map.get("key");map.put("key", "value");set.contains("element");- 哈希表的访问通常是常数时间的,但可能因哈希冲突而退化为线性时间。
- 函数调用:
- 调用一个内部不包含循环或递归的简单函数,例如
return a + b;。
- 调用一个内部不包含循环或递归的简单函数,例如
- 指针或引用赋值:
Node next = head.next;
这些操作之所以是常数时间,是因为计算机可以直接通过内存地址找到数据,或者执行固定次数的指令来完成任务,无论数据集合有多大。
5.什么是时间复杂度?
时间复杂度(Time Complexity)是用来衡量一个算法运行时间随输入数据量增长而增长的趋势的指标。它描述了算法的效率,通常用大O表示法(Big O notation)来表示。
核心思想:
- 不是实际运行时间:时间复杂度不是指算法运行的秒数、毫秒数,因为实际运行时间受计算机性能、编程语言、编译器等多种因素影响。
- 是增长趋势:它关注的是当输入数据量 n 变得非常大时,算法执行的指令数(或基本操作数)是如何变化的。
为什么使用大O表示法?
大O表示法只保留算法运行时间的最高阶项,并忽略常数系数和低阶项。这是因为它关注的是算法的渐近行为,即当 n 趋于无穷大时,算法的运行时间由哪个项主导。
例如,一个算法的运行时间是 \(2n^2+10n+50\)。
- 当 n 很小时,比如 n=10,所有项都很重要。
- 当 n 变得很大时,比如 n=10000, \(2n^2\) 的值(2亿)远大于 10n(10万)和 50。
- 在这种情况下,\(n^2\) 是决定运行时间增长趋势的主要因素。
所以,这个算法的时间复杂度就是 O(\(n^2\))。
【常见的时间复杂度】
| 复杂度 | 描述 | 例子 |
|---|---|---|
| O(1) | 常数时间 | 访问数组中的元素 arr[i] |
| O(logn) | 对数时间 | 二分查找 |
| O(n) | 线性时间 | 遍历一个数组或列表 |
| O(nlogn) | 线性对数时间 | 快速排序、归并排序 |
| O(\(n^2\)) | 平方时间 | 简单的嵌套循环(如冒泡排序、选择排序) |
| O(\(n^k\)) | 多项式时间 | 包含多重嵌套循环的算法 |
| O(\(2^n\)) | 指数时间 | 暴力穷举法(如旅行商问题) |
| O(n!) | 阶乘时间 | 寻找所有可能的排列 |
6.动态数组ArrayList
6.1什么是动态数组
和动态数组相对应的概念就是静态数组,即一开始分配内存大小固定的数组,后续都不会扩容了。
传统的数组(如 int[] arr = new int[10];)在创建时必须指定固定的大小,一旦创建,其大小就不能改变。如果数组满了,你想要添加新的元素,就必须创建一个更大的新数组,并将旧数组的所有元素复制过去。
动态数组是一种可以在运行时自动调整大小的数组。它结合了数组和链表的优点,既可以像传统数组一样通过索引快速访问元素,又可以像链表一样在需要时增加或减少容量。
在 Java 中,ArrayList 就是动态数组的一种典型实现。
当向 ArrayList 中添加元素,并且它的内部容量不足时,ArrayList 会自动完成以下操作:
- 创建一个新的、更大的内部数组(通常是旧数组容量的1.5倍或2倍)。
- 将旧数组中的所有元素复制到新数组中。
- 在新数组中添加你的新元素。
这个过程对开发者来说是透明的,只需要调用 add() 方法即可,无需担心底层的容量问题。
主要特点总结:
- 大小可变:可以自动扩容或缩容。
- 随机访问高效:由于底层是数组,通过索引访问元素的时间复杂度为 O(1)。
- 插入/删除效率低:在数组中间插入或删除元素时,需要移动后面的所有元素,平均时间复杂度为 O(n)。
- 线程不安全:
ArrayList不是线程同步的,在多线程环境下使用时,需要额外处理同步问题。
6.2动态数组的使用和扩容
ArrayList的表现会不会因为数组的扩容变得不好呢?因为数组扩容时需要实现扩容+数组的拷贝。
由于数据拷贝是一个相对耗时的操作,频繁地进行扩容会影响程序的性能。如果知道动态数组将要存储大量元素,最好在创建时就指定一个较大的初始容量。
例如:如果知道将要添加1000个元素,创建一个 new ArrayList<>(1000) 会比使用默认容量 new ArrayList<>() 更高效。后者可能会经历多次扩容(10 -> 15 -> 22 -> 33…),每次扩容都会有额外的拷贝开销。
数组扩容时,需要创建一个更大的新数组并将旧数组的元素复制过去,这个过程会带来额外的性能开销。
这个操作被称为摊还分析(Amortized Analysis)。虽然单次扩容操作的成本很高(时间复杂度为 O(n),其中 n 是当前数组的大小),但从长远来看,ArrayList 的平均插入操作仍然非常高效。
【为什么说平均性能依然高效?】
ArrayList 的扩容策略通常是成倍增加容量(比如,旧容量的1.5倍或2倍)。这意味着,虽然每隔一段时间会发生一次耗时的扩容,但在两次扩容之间,你可以进行多次快速的 O(1) 插入操作。
例如,一个 ArrayList 的容量从1000增加到1500。在接下来的500次插入中,每次操作都是 O(1)。只有在第501次插入时,才会再次触发扩容。
通过这种方式,将所有操作的成本加起来,并除以操作的总次数,你会发现每次添加操作的平均时间复杂度仍然是 O(1)。
摊还分析的解释详细
以 ArrayList 的扩容过程为例,假设每次扩容都将容量增加一倍(即从 k 变为 2k)。
- 初始状态:假设
ArrayList的初始容量为 1。 - 第一次扩容:当你添加第 2 个元素时,容量不足,需要扩容。新数组大小为 2,你需要进行 1 次元素拷贝。
- 第二次扩容:当你添加第 3 个元素时,容量不足,需要扩容。新数组大小为 4,你需要进行 2 次元素拷贝。
- 第三次扩容:当你添加第 5 个元素时,容量不足,需要扩容。新数组大小为 8,你需要进行 4 次元素拷贝。
- …
- 第 i 次扩容:当你添加第 \(2^{i−1}+1\) 个元素时,需要扩容。新数组大小为 \(2^i\),你需要进行 \(2^{i−1}\) 次元素拷贝。
现在我们来计算添加 N 个元素时的总成本。
- 每次添加操作本身的成本是 O(1)。
- 扩容操作的成本是元素拷贝,成本与当前元素数量成正比。
总成本 = (每次插入的成本)+ (所有扩容的拷贝成本)
假设我们添加 N 个元素。总共会发生大约\(log_2N\) 次扩容。
- 第一次扩容拷贝 1 个元素。
- 第二次扩容拷贝 2 个元素。
- 第三次扩容拷贝 4 个元素。
- …
- 最后一次扩容拷贝 \(2^{k−1}\)个元素(其中 \(2^k≈N\))。
总的拷贝成本可以表示为一个等比数列的和: 总拷贝成本 \(≈1+2+4+...+2^{k−1}=2^k−1\)
由于 \(2^k\) 大约等于 N,所以总的拷贝成本大约是 O(N)。
总的插入成本 = N 次插入 × 每次插入的成本 ≈O(N)。
总成本 = 总插入成本 + 总拷贝成本 ≈O(N)+O(N)=O(N)。
现在,我们用总成本除以操作次数来计算平均成本: 平均成本 = \(\frac{总成本}{N}\)=\(\frac{O(N)}{N}\)=O(1)
尽管某些特定的插入操作(即扩容时)的成本很高,达到了 O(n),但由于扩容操作的次数相对较少且成本可以分摊到每次插入上,所以从长期来看,平均到每一次插入操作的成本是恒定的。这就是为什么说 ArrayList 的添加操作具有摊还常数时间复杂度,也就是 O(1)。
7.哈希表和有序表的使用
| 特性 | 哈希表(HashMap) | 有序表(TreeMap) |
|---|---|---|
| 底层实现 | 哈希表(数组+链表/红黑树) | 红黑树(自平衡二叉查找树) |
| 存取速度 | O(1) (平均) | O(logn) (平均) |
| 元素顺序 | 无序,不保证顺序 | 有序,按键的自然排序或自定义排序 |
| 键是否为空 | 允许 | 不允许 |
| 主要用途 | 高效的键值对存储,需要快速查找 | 需要按键排序,或进行范围查询 |
7.1哈希表 (Hash Table)
哈希表基于哈希函数实现,它将键映射到数组中的一个索引位置,从而实现快速存取。在 Java 中,最常见的哈希表实现是 HashMap。
【用法特点】
- 无序性:哈希表不保证元素的顺序。你无法预测元素在迭代时出现的顺序。
- 高效性:插入、删除和查找操作的平均时间复杂度为 O(1)。这是哈希表最大的优势!!!(但是是比较大的常数时间)。
- 键唯一:每个键都是唯一的,但值可以重复。
- 可为空:
HashMap允许键和值都为null。
【常用场景】
- 需要快速查找、插入和删除:当你需要一个字典或映射表,并且对性能要求很高时,
HashMap是首选。例如,根据用户ID查找用户信息,或者缓存数据。 - 统计频率:统计单词在文章中出现的频率,用哈希表来存储
(单词, 次数)的键值对非常高效。
7.2有序表 (Ordered Map)
有序表保证了元素的顺序性。在 Java 中,常见的有序表实现是 TreeMap。它基于红黑树(一种自平衡二叉查找树)实现,所以能保持键的排序。
【用法特点】
- 有序性:元素是按键的自然排序(或自定义的比较器)存储的。
- 相对低效:插入、删除和查找操作的平均时间复杂度为 O(logn)。虽然比哈希表慢,但比无序遍历快得多。
- 键唯一:每个键都是唯一的,但值可以重复。
- 不可为空:
TreeMap不允许键为null。
【常用场景】
- 需要按键排序:当你需要一个按键排序的映射表时,
TreeMap是理想选择。例如,存储学生的成绩并按学号排序。 - 范围查询:可以方便地进行范围查询,比如查找某个键范围内的所有元素。
- 查找最大/最小键:由于数据有序,
TreeMap可以轻松地找到最大键和最小键。
常用方法firstKey,lastKey,floorKey,ceilingKey等
7.3HashMap中按值传递与按引用传递
如果是String,Integer等等虽然其他场景下会认为不同,但是HashMap中如果作为键,则认为是一样的,比较的是其字面量。
在HashMap存储自定义对象的时候,需要自己再自定义的对象中重写其hashCode()方法和equals方法,才能保证其存储不重复的元素,否则将存储多个重复的对象,因为每new一次,其就创建一个对象,内存地址是不同的。
7.4HashMap占用内存的问题
如果是HashMap<String, String>,存储的是String所有的字节数,如果是HashMap<Node,Node>,则存储的是Node的引用(即地址值),是固定的,比如8字节+8字节
详细解释:
HashMap<String, String>: 当存储 String 对象时,内存占用是可变的。HashMap 存储的不是 String 的引用地址,而是 String 对象本身。String 对象是一个由字符数组(char[])和一些其他元数据组成的类,其内存大小取决于字符串的长度。
- 一个
String的内存占用大致等于:String对象头部开销 + 字符数组头部开销 + 字符数量 * 字符大小(Java 8 前是 2 字节,Java 9 后是 1 或 2 字节)+ 其他字段。 - 所以,你存储的字符串越长,
HashMap占用的内存就越大。
HashMap<Node, Node>: 当存储自定义的类对象(如你的 Node 类)时,HashMap 存储的确实是这些对象的引用(地址值)。
- 在64位JVM上,一个普通对象引用(Ordinary Object Pointer)通常是8字节(开启指针压缩后是4字节)。
- 所以,存储一个
Node对象的键和值,HashMap会为它们各分配一个引用空间。HashMap的数据部分占用的内存大致为:键引用(8字节)+ 值引用(8字节)。这个大小是固定的。 - 当然,所引用的
Node对象本身的内存开销是额外计算的,它存储在堆(Heap)的其他位置。