预备
pandas获取当前时间
1
pd.Timestamp.now()

时间序列数据在金融、经济、气象、物联网等众多领域中无处不在。Pandas 提供了强大而灵活的工具来处理、分析和操作时间序列数据。理解其核心概念对于任何数据科学家或分析师都至关重要。
1.时间戳操作
时间戳(Timestamp)是 Pandas 中表示单个特定时间点的数据类型,而时期(Period)表示一个时间段。理解它们的创建和转换是时间序列分析的基础。
1.1 创建方法
Pandas 提供了多种创建时间戳和时期数据的方法,以及用于生成时间范围的函数。
创建单个时间戳
pd.Timestamp():创建单个时间戳pd.Timestamp是 Pandas 中用于表示单个精确时间点的标量类型,它继承自 Python 的datetime.datetime对象,但提供了更丰富的功能和更好的性能,尤其是在与 Pandas 的时间序列结构(如DatetimeIndex)结合使用时。其内部存储通常是一个纳秒精度的时间戳。- 拓展:
- 精度:
Timestamp默认支持纳秒级精度,远超 Python 内置datetime的微秒级。这对于高频交易数据或传感器数据等场景非常有用。 - 时区: 可以直接在创建时指定时区,或之后进行时区本地化和转换。
- 与 Python
datetime互操作:Timestamp可以轻松地与 Python 内置的datetime对象进行转换。
- 精度:
【1】创建一个精确到时分秒的时间戳:
1
2
ts1 = pd.Timestamp("2025-07-25 23:00:00")
ts1

【2】创建一个带时区的时间戳:
1
2
ts2 = pd.Timestamp("2025-07-25 23:00:00", tz="Asia/Shanghai")
ts2

【3】从Unix时间戳创建(默认单位是纳秒)
1
2
ts3 = pd.Timestamp(1678886400000000000)
ts3

【4】从python datetime对象创建:
1
2
3
4
from datetime import datetime
dt_obj = datetime.now()
ts4 = pd.Timestamp(dt_obj)
ts4

创建单个时期
-
pd.Period():创建单个时期-
pd.Period表示一个具有特定频率的时间段,而不是一个精确的时间点。例如,Period('2020-08', freq='M')表示 2020 年 8 月这个月份。它的内部存储通常是一个整数,表示从某个基准点(如 1970-01-01)开始的特定频率的偏移量。Period对于财务报告周期、季度数据等非常有用。 -
拓展:
- 频率推断:
Period可以根据输入字符串自动推断频率,但显式指定更安全。- 算术运算:
Period对象支持与整数的算术运算,表示时间段的移动。 - 转换: 可以将
Period转换为Timestamp(通常是该时期的开始或结束)。
- 算术运算:
- 频率推断:
-
注:Q表示Quarterly,表示季度,M表示Monthly,表示月份。
【1】创建一个表示月份的时期:
1
2
p2 = pd.Period("2025-07-25", freq="M")
p2

【2】创建一个表示季度的时期:
1
2
3
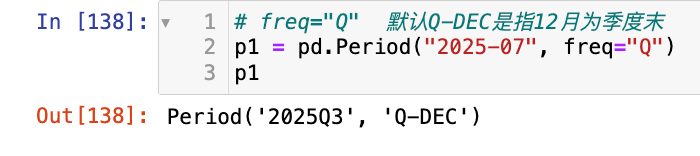
# freq="Q" 默认Q-DEC是指12月为季度末
p1 = pd.Period("2025-07", freq="Q")
p1
【3】时期算术运算:
1
2
p3 = pd.Period("2025-07", freq="M") + 3
p3

创建批量时间戳索引
pd.date_range():创建批量时间戳索引
- 原理:
pd.date_range()是创建DatetimeIndex的主要函数,它生成一系列等间隔的时间戳。DatetimeIndex是 Pandas 中用于时间序列数据的核心索引类型,它支持高效的时间点查找、切片和频率操作。其内部是一个Timestamp对象的数组,优化了存储和计算。 - 参数:
start,end: 起始和结束日期(二选一与periods配合)。periods: 生成的时间戳数量。freq: 频率字符串(如 ‘D’ 表示天,’M’ 表示月末,’H’ 表示小时等)。tz: 时区。normalize: 将时间戳归一化到午夜(00:00:00)。
- 拓展:
- 频率字符串: Pandas 支持丰富的频率字符串,包括别名(如 ‘B’ for business day, ‘W’ for weekly, ‘MS’ for month start, ‘QS’ for quarter start, ‘AS’ for annual start等)。还可以结合数字(如 ‘2H’ 表示每两小时)。
- 自定义频率: 可以使用
pd.tseries.offsets模块中的对象来创建更复杂的自定义频率。 - 应用场景: 生成时间序列数据的索引、创建空的日历、填充缺失日期等
【1】创建一个以月为频率的批量时间的数据:
1
2
index_ts = pd.date_range("2025-07-26", periods=5, freq="M")
index_ts

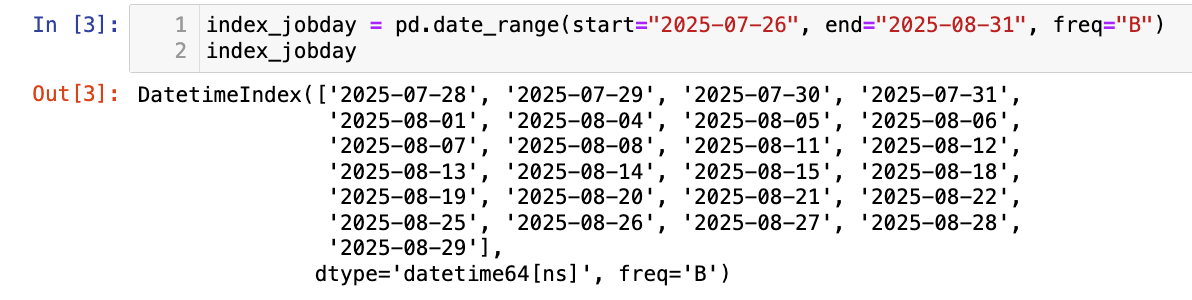
【2】创建一个以工作日为频率的时间戳索引:
1
2
index_jobday = pd.date_range(start="2025-07-26", end="2025-08-31", freq="B")
index_jobday
【3】创建一个每2个小时的时间戳索引:
1
2
index_2h = pd.date_range("2025-07-26", periods=4, freq="2H")
index_2h

创建批量时期索引
pd.period_range():创建批量时期索引
- 原理:
pd.period_range()用于创建PeriodIndex,它生成一系列等间隔的时期。PeriodIndex是 Pandas 中用于时期序列数据的索引类型,与DatetimeIndex类似,但侧重于时间段而非时间点。 - 参数: 与
date_range类似,但freq字符串通常表示时间段的频率。 - 拓展:
- 与
Period对象的对应:PeriodIndex内部存储的是Period对象。 - 应用场景: 处理财务报表(通常按季度或年度发布)、统计数据(按月或年汇总)等。
- 与
【1】创建一个以月为频率的批量时期的数据:
1
2
index_period = pd.period_range("2025.07.26", periods=5, freq="M")
index_period

【2】创建一个以季度为频率的时期的索引:
1
2
index_q = pd.period_range(start="2025Q3", end="2026Q1", freq="Q")
index_q

时间戳作为行索引的Series
pd.Series(..., index=...):时间戳索引 Series
- 原理: 当一个
Series或DataFrame的索引是DatetimeIndex或PeriodIndex时,它就成为一个时间序列对象。Pandas 为这些对象提供了专门的时间序列方法,使得时间相关的操作更加便捷和高效。索引的类型决定了时间序列的性质(时间点或时间段)。 - 拓展:
- 数据对齐: Pandas 在进行时间序列运算时会自动根据时间索引进行数据对齐,处理缺失值。
- 时间序列特有方法:
resample,asfreq,shift,rolling等。 - 在机器学习中的作用: 大多数时间序列模型(ARIMA, Prophet, LSTM等)都要求输入数据具有时间索引,以便进行特征工程(如提取日期特征)、数据分割(训练/测试集按时间顺序)和模型评估。
【1】创建一个时间戳索引的Series
1
2
3
ts = pd.date_range("2025-07-26", periods=5, freq="D")
s = pd.Series(data=np.random.randint(100, 200, (5,)), index=ts)
s

【2】创建一个时期索引的Series
1
2
3
pe = pd.period_range("2025-07", periods=3, freq="M")
s1 = pd.Series(data=np.random.randint(200, 300, (3,)), index=pe)
s1
1.2 转换方法
Pandas 提供了强大的工具来将各种格式的数据转换为时间戳,以及对时间戳进行日期偏移操作。
转换为时间戳
pd.to_datetime():将各种类型转换为时间戳- 原理:
pd.to_datetime()是 Pandas 中最常用的时间数据解析函数。它能够智能地识别多种日期和时间字符串格式,并将其转换为Timestamp对象。其底层实现会尝试多种解析策略,包括 ISO 8601 格式、各种常见的日期分隔符等。对于无法识别的格式,可以通过format参数显式指定。 - 参数:
arg: 要转换的对象(字符串、列表、Series、DataFrame列等)。unit: 当输入是整数或浮点数时,指定其单位(’s’ for seconds, ‘ms’ for milliseconds, ‘us’ for microseconds, ‘ns’ for nanoseconds)。这对于 Unix 时间戳转换非常有用。errors: 错误处理方式 (‘ignore’ 返回原始输入,’coerce’ 将无法解析的转换为NaT(Not a Time),’raise’ 抛出错误)。format: 显式指定日期时间格式字符串,可以提高解析速度和准确性。
- 拓展:
- 批量转换:
pd.to_datetime可以高效地处理整个 Series 或 DataFrame 列的转换。 - 性能优化: 对于大量数据,如果日期时间格式一致,使用
format参数可以显著提高性能。 NaT(Not a Time): Pandas 中表示时间缺失值的特殊类型,类似于NaN。
- 批量转换:
- 原理:
【1】字符串:
1
2
3
4
5
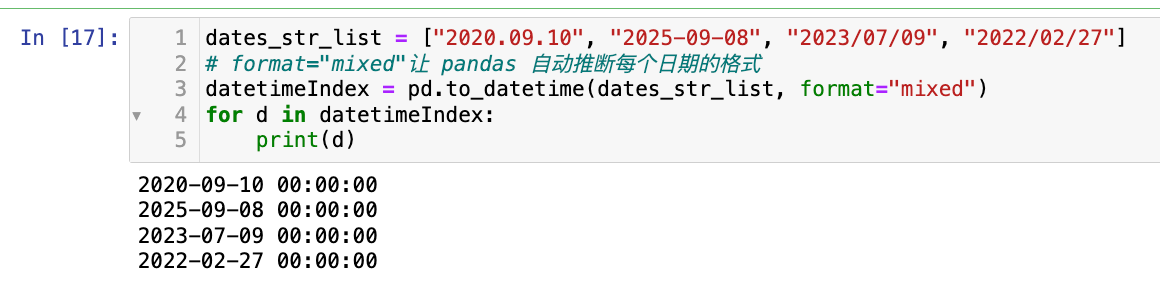
dates_str_list = ["2020.09.10", "2025-09-08", "2023/07/09", "2022/02/27"]
# format="mixed"让 pandas 自动推断每个日期的格式
datetimeIndex = pd.to_datetime(dates_str_list, format="mixed")
for d in datetimeIndex:
print(d)
【2】转换unix时间戳(秒)
1
2
unix_time = [1598582232, 1609459200]
pd.to_datetime(unix_time, unit="s")

注意参数:
unit="s",输入的时间戳是以秒为单位(而不是毫秒、微秒等)
【3】转换unix时间戳(毫秒)
1
2
unix_time2 = [1598582420401, 1678886400000]
pd.to_datetime(unix_time2, unit="ms")

【4】使用format参数指定格式:
1
2
str_list = ["2025-July-09", "2025-June-21"]
pd.to_datetime(str_list, format="%Y-%B-%d")

如果你不确定日期字符串的格式是否一致,或者想让 pandas 自动推断格式,可以使用 format="mixed"
日期偏移
pd.DateOffset():日期偏移
- 原理:
pd.DateOffset是 Pandas 中用于表示时间偏移量的对象。它允许您以各种时间单位(如年、月、日、小时、分钟、秒、工作日等)对时间戳进行加减运算。与 Python 内置的timedelta不同,DateOffset能够处理日历效应,例如月份的长度不同、闰年等。其内部逻辑会根据日历规则进行调整,而不是简单地增加固定秒数。 - 拓展:
- 多种偏移量:
pd.DateOffset支持多种参数,如years,months,days,hours,minutes,seconds,microseconds,nanoseconds。 - 特定日历规则: Pandas 还提供了更专业的偏移量,如
BusinessDay,MonthEnd,QuarterEnd,YearEnd等,这些在处理财务或商业数据时非常有用。 - 应用场景: 计算未来/过去的日期、生成特定频率的日期序列、时间窗口的定义等。
- 多种偏移量:
-
偏移别名
大量的字符串别名被赋予常用的时间序列频率。我们把这些别名称为偏移别名
别名 描述说明 B 工作日频率 BQS 商务季度开始频率 D 日历/自然日频率 A 年度(年)结束频率 W 每周频率 BA 商务年底结束 M 月结束频率 BAS 商务年度开始频率 SM 半月结束频率 BH 商务时间频率 BM 商务月结束频率 H 小时频率 MS 月起始频率 T, min 分钟的频率 SMS SMS半开始频率 S 秒频率 BMS 商务月开始频率 L, ms 毫秒 Q 季度结束频率 U, us 微秒 BQ 商务季度结束频率 N 纳秒 QS 季度开始频率
【1】转换为某个时区:(比如下面的东八时区)
1
2
3
dt = pd.to_datetime([1598582420401], unit="ms")[0] # Timestamp('2020-08-28 02:40:20.401000')
dt_shanghai = dt + pd.DateOffset(hours=8)
dt_shanghai

【2】100天之后:
1
2
df_plus_100 = dt + pd.DateOffset(days = 100)
df_plus_100

【3】增加3个月:
1
2
dt_plus_3_month = dt+pd.DateOffset(months=3)
dt_plus_3_month # Timestamp('2020-11-28 02:40:20.401000')
【4】增加2个工作日
1
2
dt2 = dt+pd.tseries.offsets.BDay(2)
display(dt, dt2)

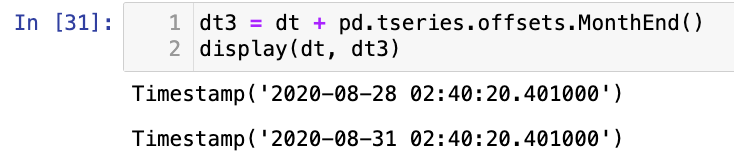
【5】到下一个月末:
1
2
dt3 = dt + pd.tseries.offsets.MonthEnd()
display(dt, dt3)
练习:时间戳操作
选择题:
-
以下哪个函数最适合用于将一个包含多种日期字符串格式的 Pandas Series 转换为
DatetimeIndex?A)
pd.Timestamp()B)pd.Period()C)pd.to_datetime()D)pd.DateOffset()
答案:C。
pd.to_datetime()专门设计用于解析各种日期时间格式并将其转换为Timestamp或DatetimeIndex。A 和 B 用于创建单个时间戳或时期,D 用于时间偏移。
-
如果
ts = pd.Timestamp('2023-01-31'),那么ts + pd.DateOffset(months=1)的结果是什么?A)
Timestamp('2023-02-28 00:00:00')B)
Timestamp('2023-03-01 00:00:00')C)
Timestamp('2023-02-31 00:00:00')(会报错)D)
Timestamp('2023-02-28 00:00:00')(如果2023年是闰年)答案:A。
pd.DateOffset会智能处理月份的长度。从 1 月 31 日加 1 个月,会得到 2 月的最后一天,即 2023 年 2 月 28 日(2023 年不是闰年)。
编程题:
- 创建一个从 ‘2024-01-01’ 开始,包含 10 个工作日(周一到周五)的
DatetimeIndex。
1
pd.date_range("2024-01-01", periods=10, freq="B")
注意:使用
freq='B'(Business Day) 可以生成只包含工作日的时间序列。
- 给定一个包含以下字符串的列表:
['2022-05-10', '15/06/2023', 'July 4, 2024', '20250101']。尝试使用pd.to_datetime将其转换为DatetimeIndex。如果遇到无法解析的日期,请将其转换为NaT。
1
2
str_l = ['2022-05-10', '15/06/2023', 'July 4, 2024', '20250101']
pd.to_datetime(str_l, format="mixed", errors="coerce")
2.时间戳索引
时间戳索引是 Pandas 时间序列数据操作的核心。它允许我们使用直观的日期和时间字符串来选择、切片和过滤数据。
2.1 基于字符串的索引和切片
当 Series 或 DataFrame 的索引是 DatetimeIndex 时,Pandas 提供了强大的基于字符串的索引和切片功能。其原理是 Pandas 会尝试将输入的字符串解析为时间戳,然后进行精确或范围匹配。这种方式大大简化了时间序列数据的选择。
- 精确匹配: 当传入完整的日期字符串时,Pandas 会查找索引中匹配的精确时间戳。
- 部分匹配(切片): 当传入部分日期字符串(如年、年月)时,Pandas 会将其扩展为该时间段的起始和结束时间戳,然后进行范围切片。例如,
'2020-08'会被解释为从'2020-08-01 00:00:00'到'2020-08-31 23:59:59.999999999'的范围。
拓展:
- 效率: 对于大型时间序列,基于
DatetimeIndex的索引和切片非常高效,因为索引是排序的,Pandas 可以利用二分查找等优化技术。 - 与
loc结合: 也可以使用.loc访问器进行基于标签的索引,例如ts.loc['2020-08-30']。 - 不完整日期匹配: 这种特性在需要快速获取某个月份或年份的所有数据时非常方便。
【1】精确匹配:
1
2
3
4
5
ts = pd.date_range("2025-07-26", periods=200, freq="D") # 工作日B
s = pd.Series(data=range(len(ts)), index=ts)
display(s)
# 2025-08-30
s["2025-08-30"]

【2】日期切片(包含起始和结束)
1
s["2025-07-30": "2026-02-21"]
【3】模糊匹配:
1
s["2025-09"]

1
s["2026"]

2.2 基于时间戳对象的索引和切片
除了字符串,我们也可以直接使用 pd.Timestamp 对象作为索引或切片条件。这在需要程序化生成时间点进行访问时非常有用。其原理与字符串索引类似,但避免了字符串解析的开销。
拓展:
- 灵活性: 结合
pd.date_range可以动态生成时间戳列表进行高级选择。 - 混合索引: 可以在同一个操作中混合使用字符串和
Timestamp对象。
【1】基于pd.Timestamp进行精确访问:
1
s[pd.Timestamp("2025-08-23")]

也可以是切片:
1
s[pd.Timestamp("2025-08-23"): pd.Timestamp("2026-01-23")]
【2】结合 pd.date_range 可以动态生成时间戳列表进行高级选择
1
2
dr = pd.date_range("2025-08-01", periods=10, freq="D")
s[dr]
2.3 时间戳索引属性
DatetimeIndex 对象提供了丰富的属性,可以直接从中提取年、月、日、星期几、季度等时间信息。这些属性是基于 Timestamp 对象的内部结构计算得出的,非常高效。它们是进行时间序列特征工程的关键。
拓展:
- 特征工程: 在机器学习/深度学习中,从时间戳中提取这些属性(如
year,month,day,dayofweek,weekofyear,quarter,is_month_start,is_quarter_end等)是非常常见的特征工程方法。这些离散的、周期性的特征可以帮助模型捕捉时间序列中的季节性、周期性模式。 - 可视化: 可以根据这些属性对数据进行分组或聚合,然后进行可视化分析。
- 可用属性: 除了示例中的,还有
month,day,hour,minute,second,microsecond,nanosecond,quarter,is_month_start,is_month_end,is_quarter_start,is_quarter_end,is_year_start,is_year_end,is_leap_year等。

练习 时间戳索引
选择题:
-
给定
ts = pd.Series(range(10), index=pd.date_range('2023-01-01', periods=10, freq='D'))。执行ts['2023-01-05':'2023-01-07']会返回多少个数据点?A) 2 B) 3 C) 4 D) 5
答案:B,时间序列切片是包含起始和结束的。所以会返回 2023-01-05, 2023-01-06, 2023-01-07 这三个数据点。
-
要获取
DatetimeIndex中所有日期是周六或周日的数据,可以使用哪个属性?A)
index.dayB)index.dayofweekC)index.weekdayD)index.is_weekend
答案:B或者C,
dayofweek(或weekday) 返回星期几的整数表示,0 代表周一,6 代表周日。所以周六是 5,周日是 6。is_weekend属性在 Pandas 中并不直接存在,但可以通过dayofweek派生。
编程题:
- 创建一个从 ‘2023-01-01’ 到 ‘2023-12-31’ 的每日时间序列
Series,数据为随机整数。然后: a) 提取所有 2023 年 3 月的数据。 b) 提取所有每周一的数据。 c) 计算每个月的平均值。
1
2
3
4
5
6
7
8
9
10
11
ts = pd.date_range(start="2023-01-01", end="2023-12-31")
s = pd.Series(data=range(len(ts)), index=ts)
display(s)
# a) 提取所有 2023 年 3 月的数据。
s1 = s["2023-03"]
display(s1)
# b) 提取所有每周一的数据。
display(s[s.index.dayofweek == 0] )
# c) 计算每个月的平均值。
mean_ = s.groupby(s.index.month).mean()
display(mean_)
3.时间序列常用方法
在时间序列分析中,经常需要对数据进行移动(滞后)、频率转换和重采样等操作。Pandas 提供了高效且功能丰富的内置方法来完成这些任务。
3.1 移动 (Shifting)
数据移动
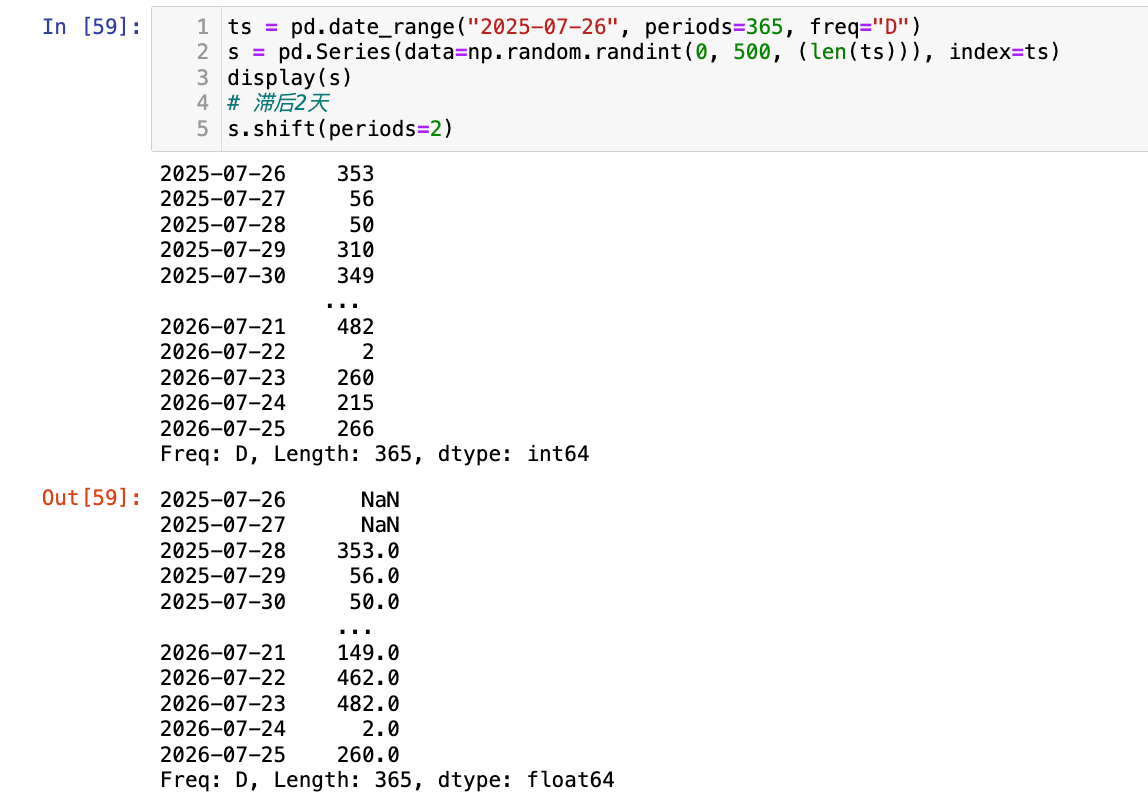
Series.shift():数据移动
shift()方法用于将 Series 或 DataFrame 中的数据沿时间轴向前或向后移动(滞后或超前)。它会根据指定的periods参数移动数据,并在移动后产生的空白位置填充NaN。periods > 0:数据向后移动,即滞后。例如,shift(1)会将当前行的数据移动到下一行,第一行变为NaN。这在计算滞后特征(lagged features)时非常有用。periods < 0:数据向前移动,即超前。例如,shift(-1)会将当前行的数据移动到前一行,最后一行变为NaN。这在计算超前特征(leading features)时很有用。
- 原理:
shift操作本质上是改变了数据与索引的对应关系,数据值保持不变,但它们被关联到了不同的时间点上。 - 拓展:
- 计算变化量: 结合
diff()方法可以计算时间序列的差分,例如ts.diff(periods=1)等同于ts - ts.shift(1)。 - 特征工程: 在机器学习中,滞后特征(如前一天的销售额、前一小时的温度)是时间序列预测模型中非常重要的特征。它们捕捉了数据在时间上的依赖性。
- 填充值: 可以通过
fill_value参数指定填充NaN的值。
- 计算变化量: 结合
【1】数据后移2天(滞后)
1
2
3
4
5
ts = pd.date_range("2025-07-26", periods=365, freq="D")
s = pd.Series(data=np.random.randint(0, 500, (len(ts))), index=ts)
display(s)
# 滞后2天
s.shift(periods=2)
【2】数据前移2天(超前):
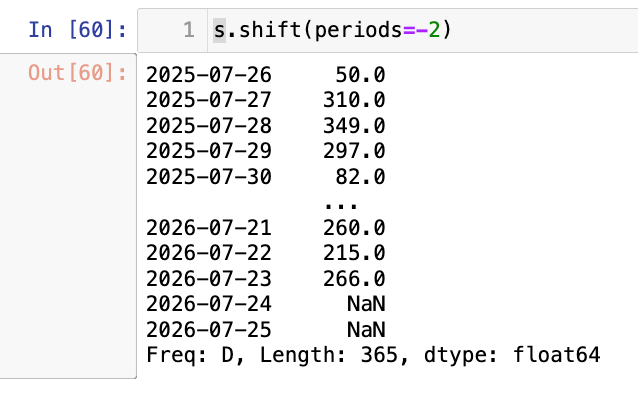
1
s.shift(periods=-2)
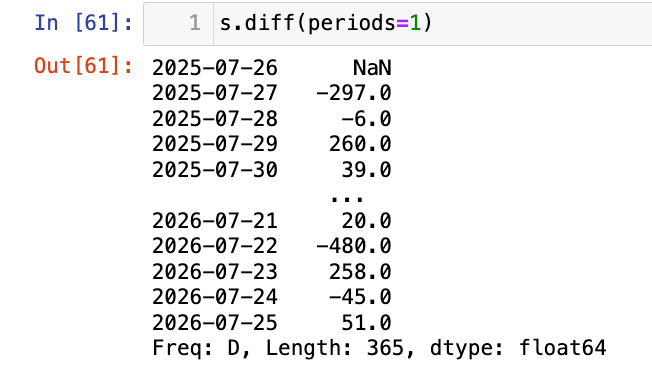
【3】应用:diff()差分,计算日变化
1
s.diff(periods=1)
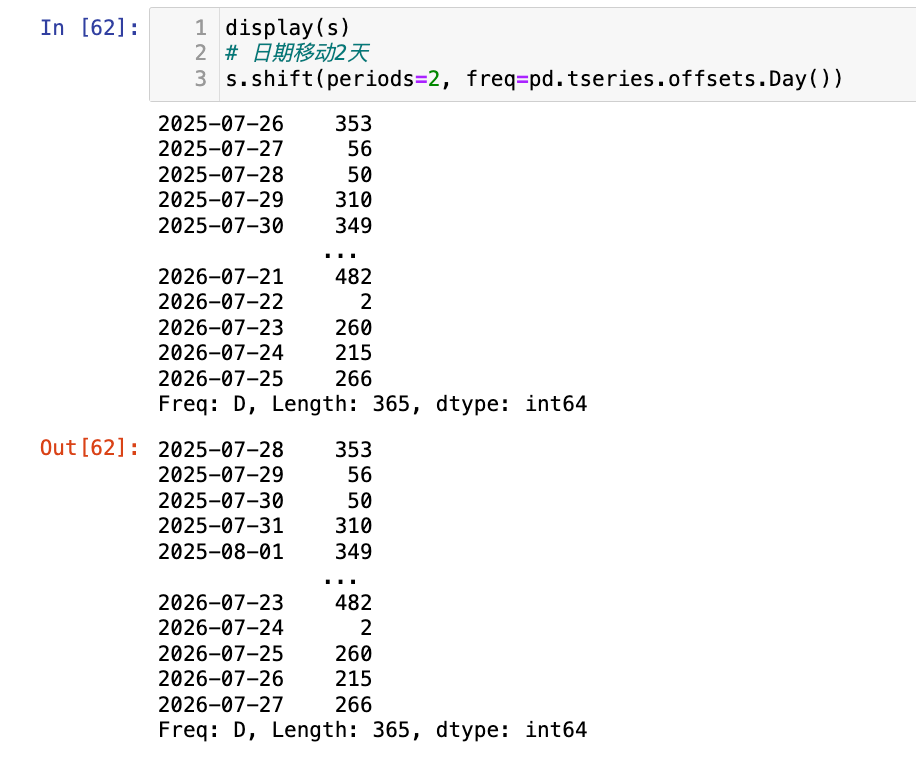
日期移动
Series.shift(freq=...):日期移动 (不常用,推荐 tshift 或 asfreq)
但是tshift 方法在现代版本的 pandas 中已被废弃(deprecated),并且在较新版本(如 pandas 1.x 及以上)中已移除。
- 讲解与原理: 这里的
shift结合freq参数实际上是调整了索引的频率,而不是移动数据。它会将索引移动指定的频率,同时保持数据与新索引的对齐。这与tshift的行为类似,但tshift更直接地表示“时间索引移动”。 - 注意: 官方文档推荐使用
tshift或asfreq进行日期索引的移动或频率转换,而不是shift(freq=...)。
1
2
3
display(s)
# 日期移动2天
s.shift(periods=2, freq=pd.tseries.offsets.Day())
3.2 频率转换 (asfreq)
asfreq() 方法用于将时间序列的频率转换为新的频率。
- 升采样 (Upsampling): 当新频率比原频率更高(例如,从天到小时),即数据点变多时,
asfreq会在新的时间点上引入NaN。可以通过fill_value或method参数(如 ‘ffill’ 前向填充,’bfill’ 后向填充)来处理这些缺失值。 - 降采样 (Downsampling): 当新频率比原频率更低(例如,从天到周),即数据点变少时,
asfreq会选择每个新频率周期内的第一个或最后一个数据点(取决于频率定义)。 - 原理:
asfreq是基于索引的重新采样,它会创建一个新的DatetimeIndex,然后尝试将原数据映射到新索引上。
拓展:
- 数据填充:
method参数在处理缺失值时非常重要,例如ffill(forward fill) 适用于股票价格等数据,bfill(backward fill) 适用于某些事件数据。 - 与
resample的区别:asfreq仅改变频率并进行简单的值选择或填充,不进行聚合运算。resample则在改变频率的同时,可以对每个新频率周期内的数据进行聚合(如求和、平均值等)。 - 机器学习/深度学习: 在时间序列预测中,有时需要将数据统一到某个频率(例如,将日数据转换为周数据),或者将低频数据升采样到高频以匹配其他特征。
- 应用场景: 将每日销售数据转换为每周销售数据,将每分钟传感器读数转换为每小时平均值等。
【1】天变周(降采样)
1
2
3
4
5
ts = pd.date_range(start="2023-01-01", end="2023-12-31")
s = pd.Series(data=range(len(ts)), index=ts)
# display(s)
# 天变周
s.asfreq(pd.tseries.offsets.Week())
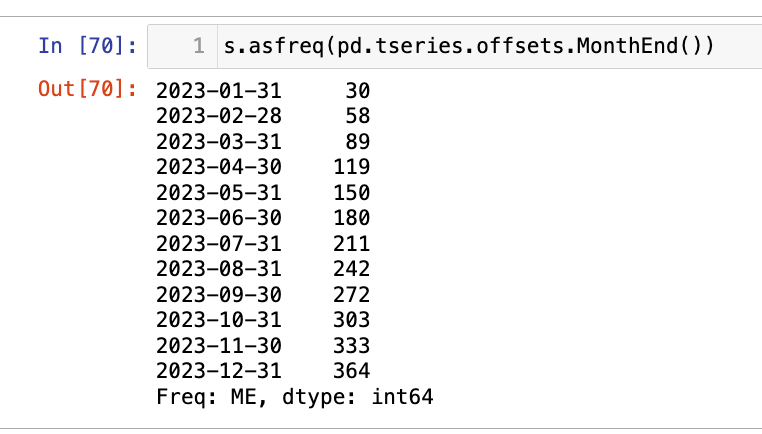
【2】天变月(降采样)
1
s.asfreq(pd.tseries.offsets.MonthEnd())
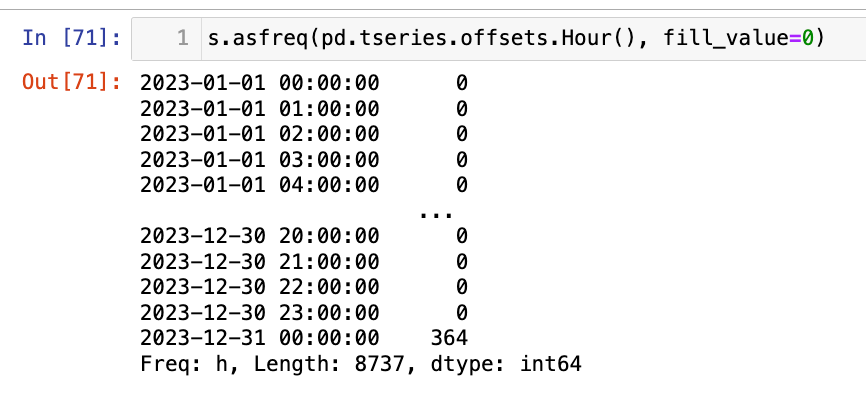
【3】天变小时(升采样,数据变多,需要填充)
1
s.asfreq(pd.tseries.offsets.Hour(), fill_value=0)
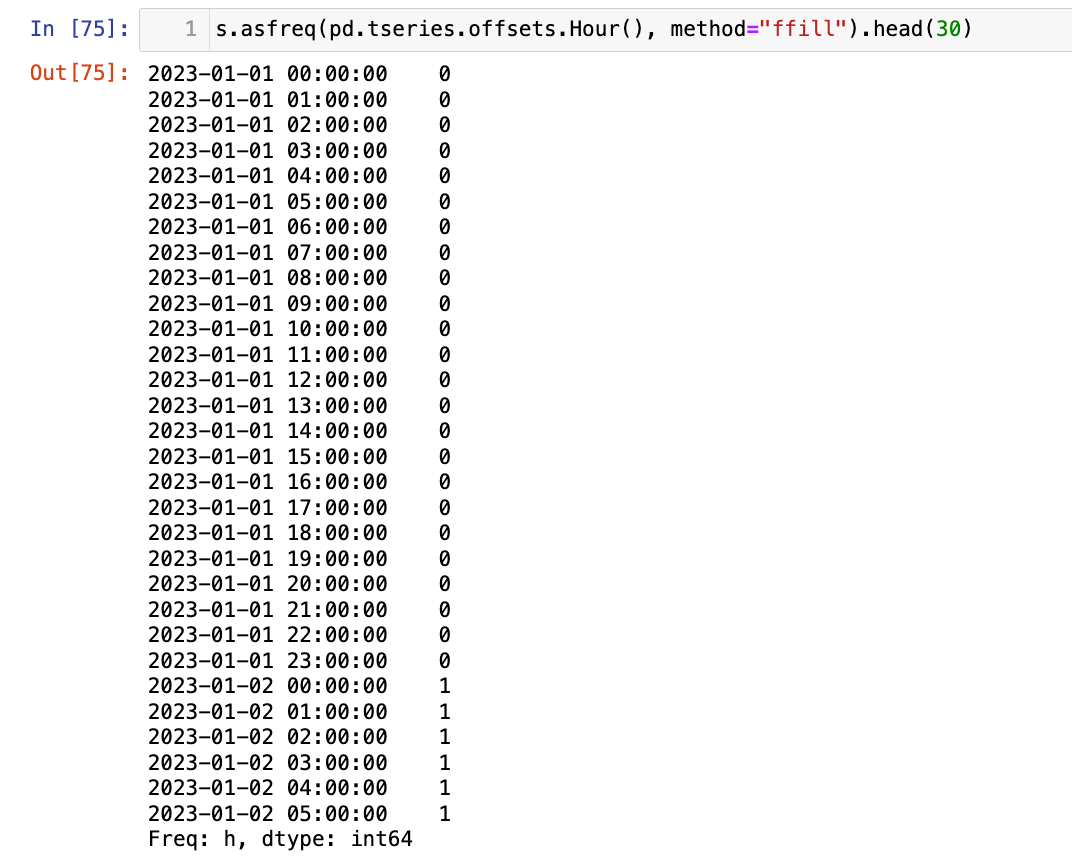
可以指定前向填充:
1
s.asfreq(pd.tseries.offsets.Hour(), method="ffill").head(30)
3.3 重采样 (resample)
resample() 是 Pandas 中用于时间序列聚合的核心方法。它允许您根据日期维度对数据进行分组,然后对每个组执行聚合操作(如求和、平均值、计数等)。
- 工作流程:
resample()返回一个Resampler对象,这个对象类似于groupby对象,需要链式调用一个聚合函数(如sum(),mean(),count(),ohlc()等)来执行实际的聚合。 - 原理:
resample会根据指定的频率创建一个新的时间段(bins),然后将原始时间序列中的数据点分配到对应的 bin 中,最后对每个 bin 中的数据执行聚合函数。
拓展:
- 聚合函数: 可以使用任何 NumPy 或 Pandas 的聚合函数,也可以使用自定义函数。
- OHLC: 对于金融数据,
ohlc()方法可以直接计算开盘价、最高价、最低价和收盘价。 - 升采样与降采样:
resample既可以用于降采样(将高频数据聚合为低频数据,如日数据到月数据),也可以用于升采样(将低频数据插值为高频数据,但通常需要配合fillna和插值方法)。 - 机器学习/深度学习: 在构建时间序列特征时,重采样是关键一步。例如,将每分钟的传感器读数重采样为每小时的平均值或最大值,以减少数据维度或提取更有意义的特征。
- 应用场景: 计算每周、每月、每年的销售总额;计算每小时的平均温度;将高频交易数据聚合为 K 线图等。
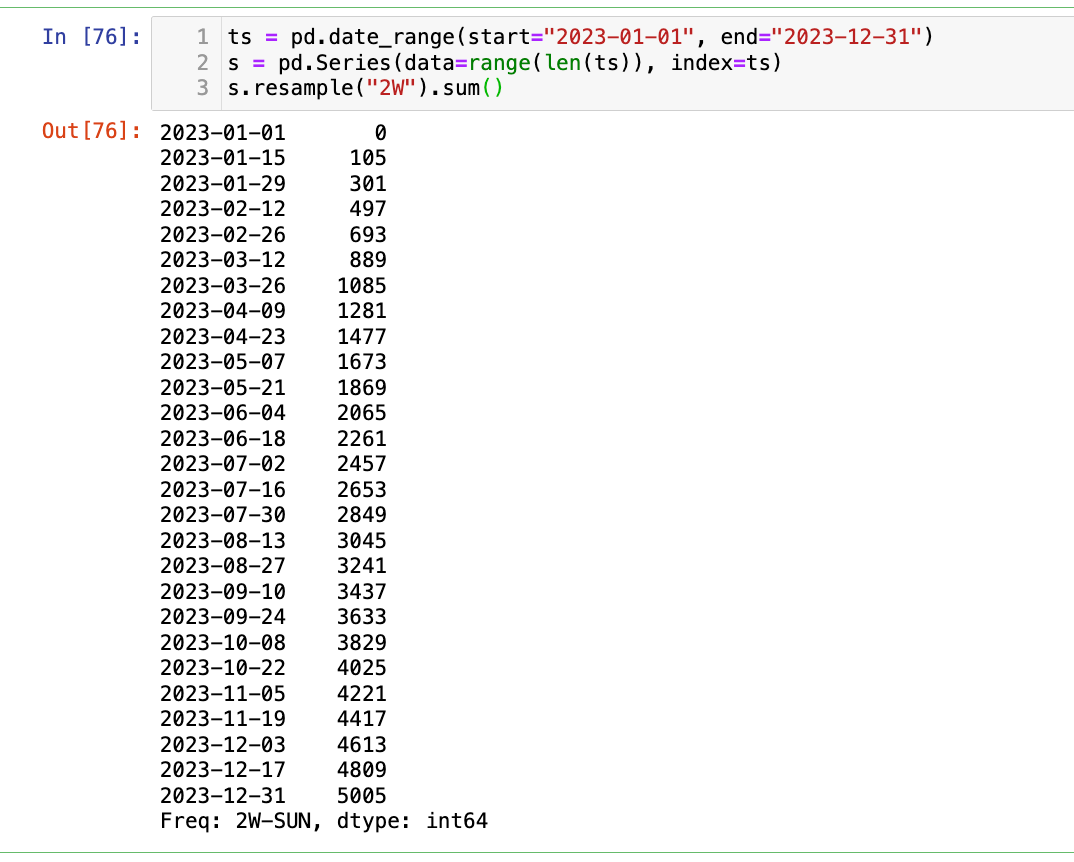
【1】以2周为单位进行汇总(比如求和)
1
2
3
ts = pd.date_range(start="2023-01-01", end="2023-12-31")
s = pd.Series(data=range(len(ts)), index=ts)
s.resample("2W").sum()
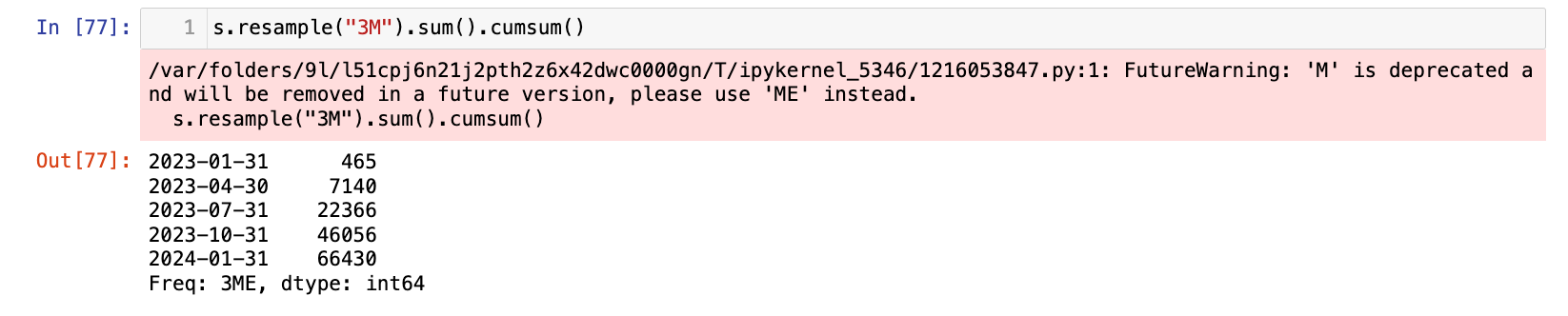
【2】以3个月为单位进行汇总(求和,然后再求累积和)
1
s.resample("3M").sum().cumsum()
【3】降采样+计算均值:
1
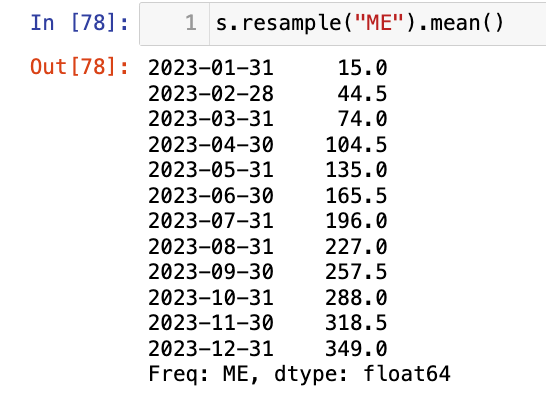
s.resample("ME").mean()
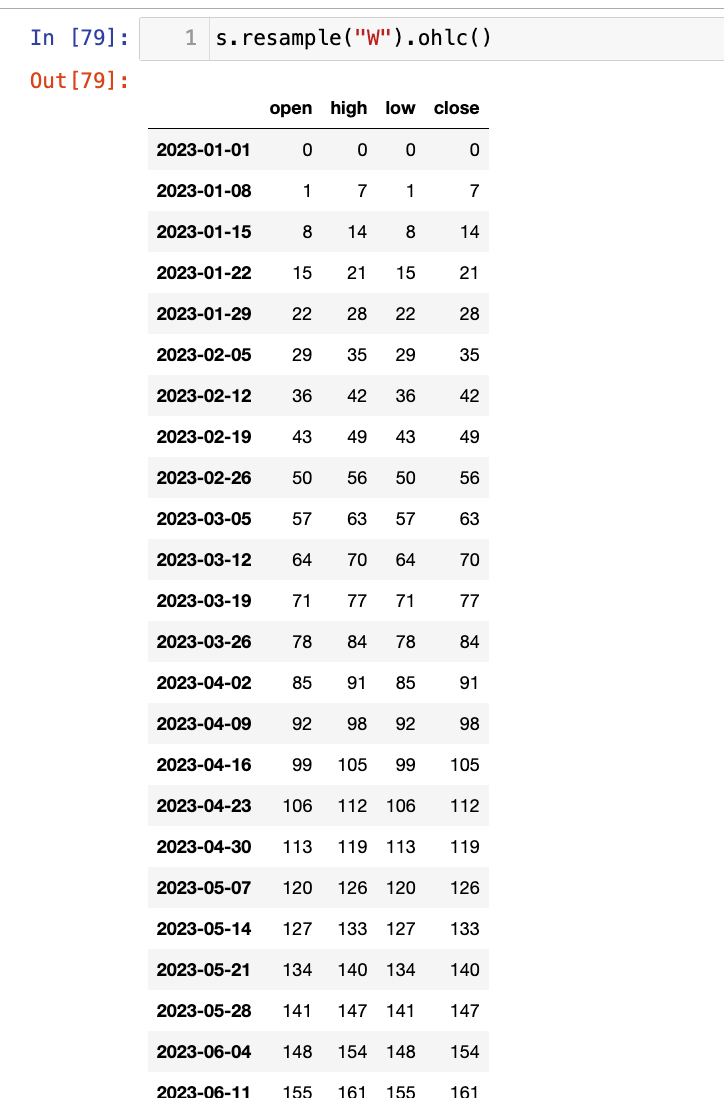
【4】降采样+OHLC(开盘价,最高价,最低价,收盘价)
1
s.resample("W").ohlc()
3.4 DataFrame 重采样
DataFrame 的重采样与 Series 类似,但可以指定用于重采样的列,或者在多级索引中指定级别。
on参数: 当 DataFrame 中存在多个日期时间列时,可以使用on参数指定哪个列作为重采样的基准。level参数: 当 DataFrame 具有多级索引,且其中一个级别是DatetimeIndex时,可以使用level参数指定对哪个级别进行重采样。agg()方法:agg()方法允许您对不同的列应用不同的聚合函数,这在重采样时非常灵活。
拓展:
- 复杂聚合:
agg可以接受字典,列表或元组来定义复杂的聚合。 - 多级索引处理:
level参数在处理复杂数据结构时非常有用。 - 应用场景: 股票交易数据(价格、成交量),需要按周或月聚合时,价格可能需要求平均,而成交量需要求和。
1
2
3
4
5
6
7
8
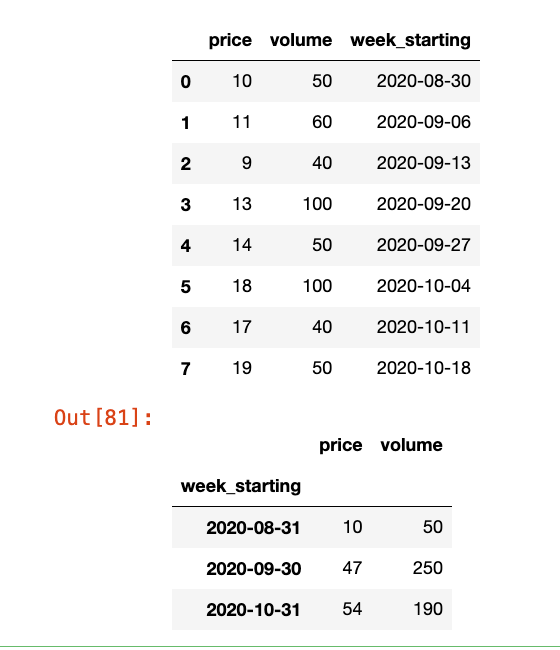
d = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50],
'week_starting': pd.date_range('24/08/2020', periods=8, freq='W')})
df = pd.DataFrame(d)
display(df)
# 基于week_starting,按照月汇总求和
# 也可以用 df.resample("ME", on="week_starting").apply("sum")
df.resample("ME", on="week_starting").sum()
也可以基于不同的列进行聚合:
1
df.resample("ME", on="week_starting").agg({"price": "mean", "volume": "sum"})
多级索引的重采样:
1
2
3
4
5
6
7
8
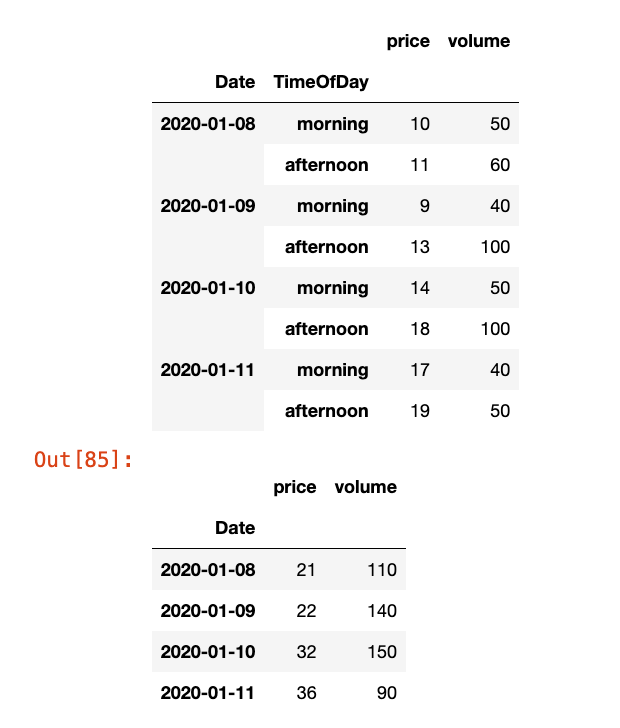
days = pd.date_range('1/8/2020', periods=4, freq='D')
data2 = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50]})
df2 = pd.DataFrame(data2,
index=pd.MultiIndex.from_product([days, ['morning', 'afternoon']], names=['Date', 'TimeOfDay']))
display(df2)
# 基于日期进行重采样+求和
df2.resample("D", level="Date").sum()
4.时区表示
在处理全球化数据时,时区是一个非常重要的概念。Pandas 提供了完善的时区处理功能,包括时区本地化和时区转换。
时区感知 (Timezone-aware) vs. 朴素 (Naive) 时间戳:
- 朴素时间戳: 不带任何时区信息的时间戳(例如
2023-01-01 10:00:00)。它不知道自己属于哪个时区,通常被解释为本地时间或 UTC 时间,这可能导致歧义。 - 时区感知时间戳: 包含明确时区信息的时间戳(例如
2023-01-01 10:00:00+08:00)。它明确知道自己属于哪个时区,并且可以正确地进行时区转换。
UTC (Coordinated Universal Time): 协调世界时,是全球统一的时间标准。在数据存储和传输时,通常建议将时间戳转换为 UTC,以避免时区问题。
pytz 库: Pandas 内部使用 pytz 库来处理时区信息。pytz.common_timezones 列出了所有常用的时区名称。
4.1 时区本地化
tz_localize():时区本地化
tz_localize()用于将一个朴素(不带时区信息)的DatetimeIndex或Timestamp转换为时区感知(带时区信息)的对象。它告诉 Pandas 这些时间戳应该被解释为哪个时区的时间。- 重要:
tz_localize()只是给时间戳“打上标签”,并没有改变时间戳的实际 UTC 值。例如,将2020-08-01 00:00:00本地化为 ‘Asia/Shanghai’ (UTC+8),它仍然是2020-08-01 00:00:00,但现在被理解为上海时间。
4.2 时区转换
tz_convert():时区转换
tz_convert()用于将一个已经有时区信息的DatetimeIndex或Timestamp从一个时区转换为另一个时区。它会根据时区规则调整时间戳的实际 UTC 值,以确保时间点在全球范围内是相同的。- 重要:
tz_convert()改变了时间戳的实际显示值,但其表示的“绝对时间点”在 UTC 层面是不变的。例如,将2020-08-01 00:00:00+08:00转换为 ‘UTC’,会得到2020-07-31 16:00:00+00:00。
拓展:
- 夏令时 (Daylight Saving Time):
pytz库和 Pandas 会自动处理夏令时转换。在进行时区转换时,它们会考虑夏令时的开始和结束,确保时间的正确性。 - 数据一致性: 在处理来自不同地理位置或系统的数据时,统一时区是确保数据一致性和正确分析的关键。通常的做法是将所有数据转换为 UTC 进行存储和处理,只在展示给用户时才转换为用户所在的时区。
- 机器学习/深度学习: 在时间序列预测中,如果数据来源于不同时区,或者预测模型需要考虑全球时间,那么时区处理是必不可少的预处理步骤。不正确的时区处理可能导致模型学习到错误的模式。