1.索引列名排序
df.sort_index() 方法用于根据 DataFrame 的行索引或列索引进行排序。
- 基本语法:
df.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True)axis: 指定排序的轴。0(或'index'):按行索引排序。1(或'columns'):按列索引排序。
ascending: 布尔值,如果为True(默认),则按升序排序;如果为False,则按降序排序。inplace: 布尔值,是否直接修改原始 DataFrame。level: 当索引是多层索引时,指定要排序的级别。
sort_index()的底层实现是基于索引对象的排序。它会创建一个新的排序后的索引对象,然后根据这个新索引重新排列 DataFrame 的数据。
- 对于单层索引,它直接对索引标签进行排序(字符串按字典序,数字按数值序)。
- 对于多层索引,它会根据指定的
level进行排序,如果未指定level,则按所有级别进行排序。sort_index()总是返回一个新的 DataFrame(除非inplace=True),因为排序会改变数据的排列顺序。
多层索引排序
当处理多层索引时,level 参数非常强大。您可以选择只对某个特定级别的索引进行排序,而保持其他级别的相对顺序不变。例如,在一个按地区和城市分层的索引中,可以只按城市名排序,而不改变地区的顺序。
【1】按照行索引排序(默认升序)
1
2
3
4
5
6
data = np.random.randint(0, 31, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "golang"])
display(df)
# 行索引排序
df1 = df.sort_index(axis=0)
display(df1)

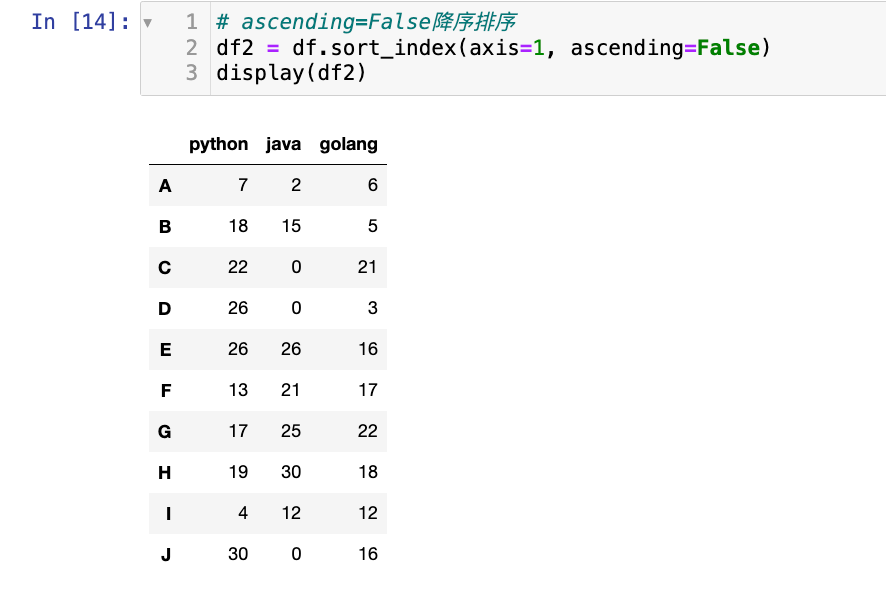
【2】按照列名排序:
1
2
3
# ascending=False降序排序
df2 = df.sort_index(axis=1, ascending=False)
display(df2)
【3】多层索引的排序:
1
2
3
4
5
6
data = np.random.randint(0, 101, (6, 2))
index = pd.MultiIndex.from_product([["A", "B"], ["X", "Y", "Z"]])
df = pd.DataFrame(data=data, index=index, columns=["v1", "v2"])
display(df)
# 第二层索引(X, Y, Z)降序
df.sort_index(level=1, ascending=False)

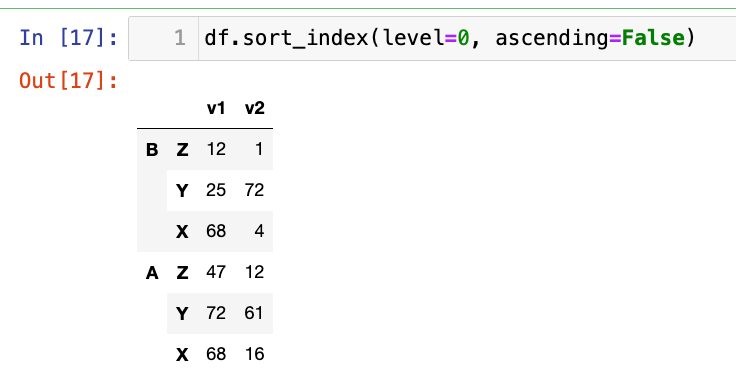
1
df.sort_index(level=0, ascending=False)
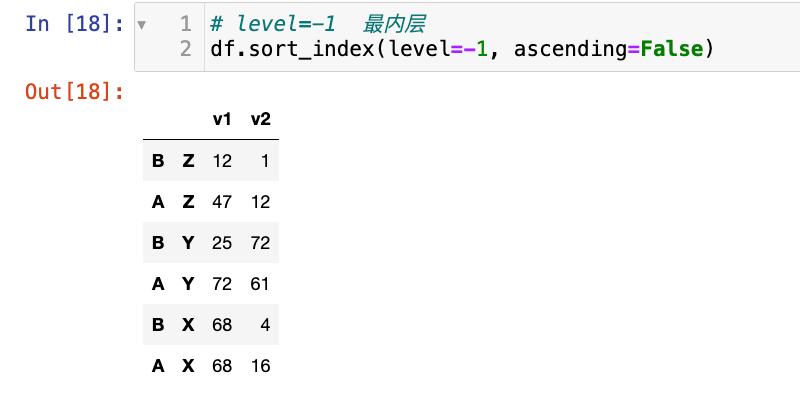
1
2
# level=-1 最内层
df.sort_index(level=-1, ascending=False)
选择题
-
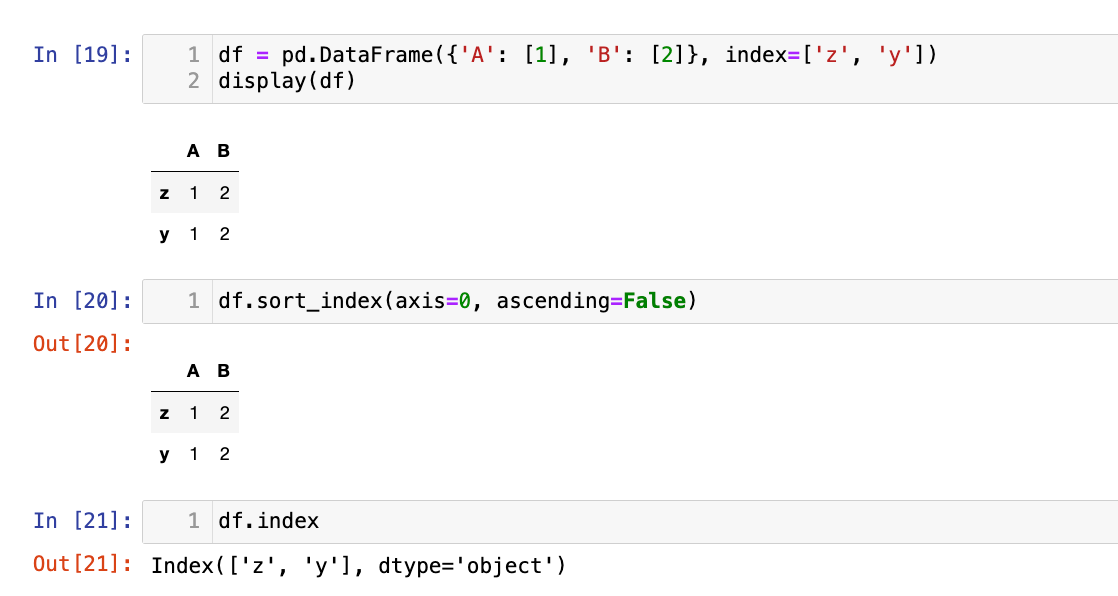
给定
df = pd.DataFrame({'A': [1], 'B': [2]}, index=['z', 'y']),执行df.sort_index(axis=0, ascending=False)后,df.index的结果是什么?A.
Index(['z', 'y'], dtype='object')B.
Index(['y', 'z'], dtype='object')C.
Index([0, 1], dtype='int64')D. 报错
答案:A
-
df.sort_index(axis=1)的作用是?A. 按行索引排序。
B. 按列索引(列名)排序。
C. 按 DataFrame 的值排序。
D. 报错。
答案:B
编程题
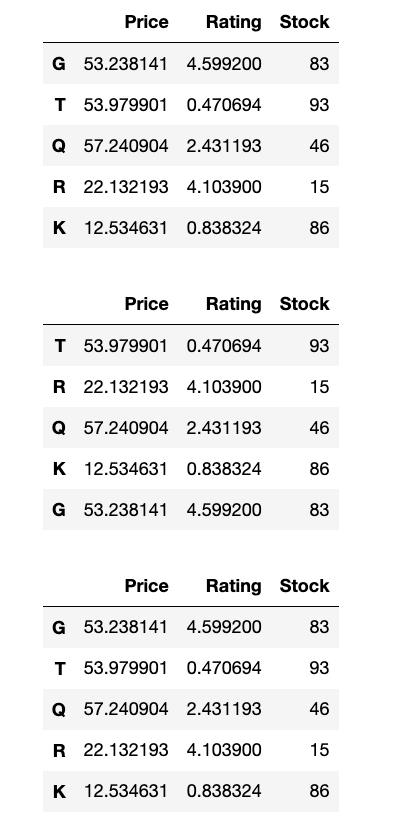
- 创建一个 DataFrame
product_data,行索引为随机字符串,列索引为'Price','Rating','Stock'。 - 对
product_data按行索引进行降序排序。 - 对
product_data按列索引(列名)进行升序排序。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 生成 5 个随机字符串作为行索引
def random_string(length=1):
import string
return ''.join(np.random.choice(list(string.ascii_uppercase), size=length))
index = [random_string() for _ in range(5)]
# 创建 data
data = {
'Price': np.random.uniform(10, 100, size=5),
'Rating': np.random.uniform(0, 5, size=5),
'Stock': np.random.randint(0, 101, size=5)
}
product_data = pd.DataFrame(data=data, index=index)
display(product_data)
# 对 product_data 按行索引进行降序排序
res1 = product_data.sort_index(axis = 0, ascending=False)
display(res1)
# 对 product_data 按列索引(列名)进行升序排序
res2 = product_data.sort_index(axis=1)
display(res2)
2.属性值排序
df.sort_values() 方法用于根据 DataFrame 中一个或多个列的值进行排序。
- 基本语法:
df.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False)by: 字符串或字符串列表,指定用于排序的列名。axis: 默认为0(按行排序,即根据列的值对行进行排序)。如果设置为1,则按列排序(根据行的值对列进行排序)。ascending: 布尔值或布尔值列表。如果传入列表,则与by中的列一一对应,指定每列的排序方向。na_position: 字符串,指定NaN值的处理位置。'last'(默认):将NaN值放在末尾。'first':将NaN值放在开头。
ignore_index: 布尔值,如果为True,则在排序后重置索引。
sort_values()的底层实现是根据指定列的值进行排序。它会首先对by参数指定的列进行排序,然后根据排序结果重新排列 DataFrame 的所有行。
- 当
by是一个列表时,pandas会按照列表中列的顺序进行多级排序:首先按第一个列排序,如果值相同,则按第二个列排序,以此类推。- 与
sort_index()类似,sort_values()总是返回一个新的 DataFrame(除非inplace=True),因为它会改变数据的排列顺序。
多列排序: 在数据分析中,经常需要根据多个条件进行排序。例如,先按部门排序,再按薪资降序排序。
缺失值位置: na_position 参数在处理含有缺失值的排序时非常有用,可以控制缺失值是出现在排序结果的开头还是末尾。
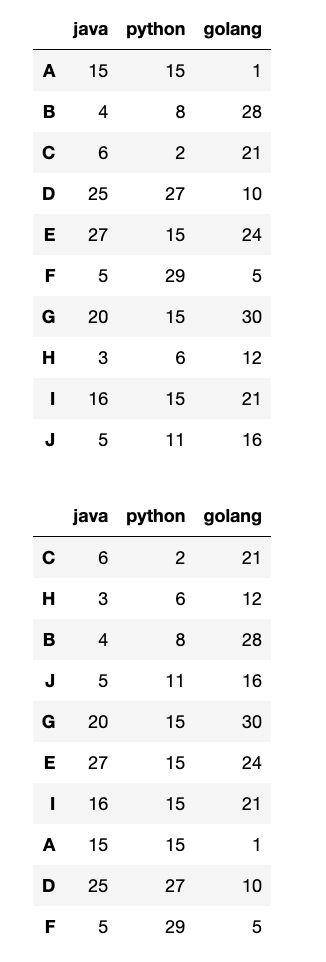
【1】按照某一列属性值排序:
1
2
3
4
5
6
7
8
data = np.random.randint(0, 31, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "golang"])
# 为了测试,确保有多个重复的值用于多列排序
df.loc[["A", "E", "G", "I"], "python"] = 15
display(df)
# 按照python列值排序(默认升序)
df1 = df.sort_values(by="python")
display(df1)
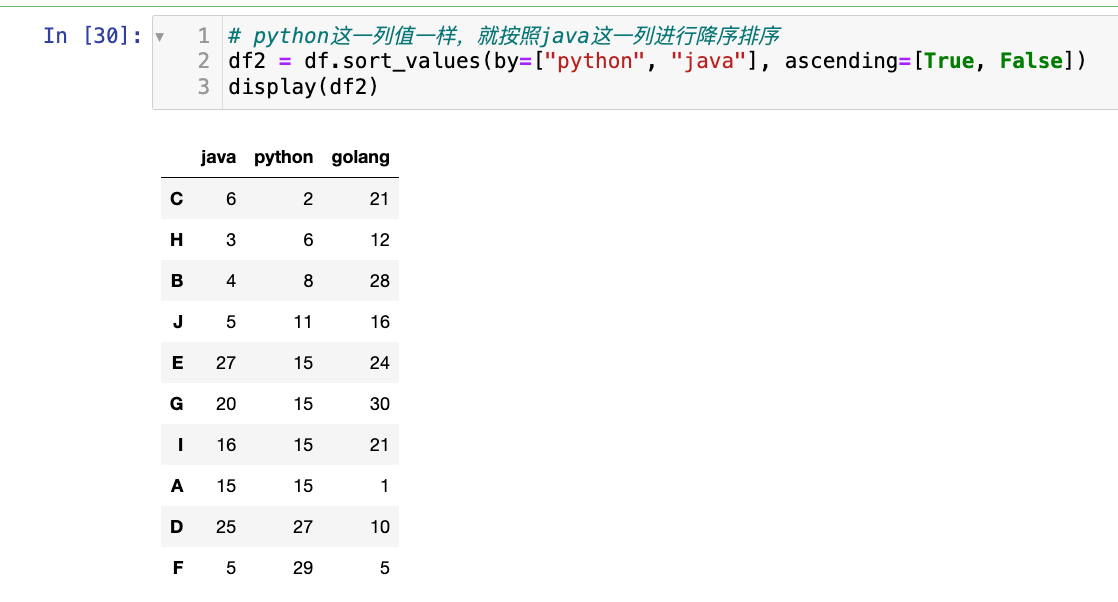
【2】多列排序,比如某一列升序,某一列降序:
1
2
3
# python这一列值一样,就按照java这一列进行降序排序
df2 = df.sort_values(by=["python", "java"], ascending=[True, False])
display(df2)
【3】处理缺失值位置:
1
2
3
4
5
# 为了测试,插入一个测试值
df.loc["F", "golang"] = np.nan
display(df)
df3 = df.sort_values(by="golang", na_position="first")
display(df3)

可以看到缺失值在最前面了。
选择题
-
给定
df = pd.DataFrame({'A': [1, 3, 2], 'B': ['x', 'z', 'y']}),执行df.sort_values(by='B')后,df['B']列的顺序是什么?A.
['x', 'y', 'z']B.
['z', 'y', 'x']C.
['x', 'z', 'y']D. 报错
答案:C,因为没有设定
replace=True -
要将 DataFrame 先按
'Department'升序排序,然后按'Salary'降序排序,以下哪个sort_values()调用是正确的?A.
df.sort_values(by=['Department', 'Salary'], ascending=True)B.
df.sort_values(by=['Department', 'Salary'], ascending=[True, False])C.
df.sort_values(by='Department', ascending=True).sort_values(by='Salary', ascending=False)D.
df.sort_values(by='Department', by='Salary', ascending=[True, False])答案:B
编程题
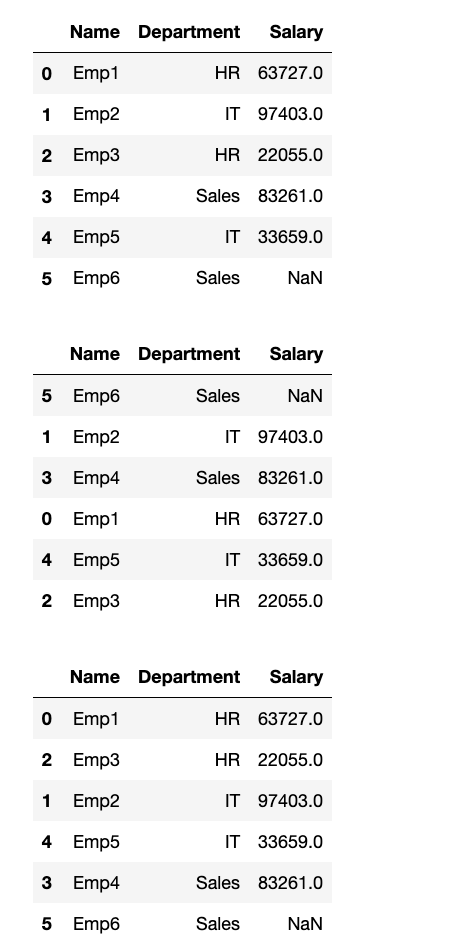
- 创建一个 DataFrame
employee_data,包含'Name','Department','Salary'三列,以及 6 行数据。Department包含'HR','IT','HR','Sales','IT','Sales'。Salary填充随机整数,其中一个Salary值为np.nan。
- 按
'Salary'列降序排序,并将缺失值放在开头。 - 先按
'Department'升序排序,再按'Salary'降序排序。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
data = {
'Name': ['Emp1', 'Emp2', 'Emp3', 'Emp4', 'Emp5', 'Emp6'],
'Department': ['HR', 'IT', 'HR', 'Sales', 'IT', 'Sales'],
'Salary': [63727.0, 97403.0, 22055.0, 83261.0, 33659.0, np.nan]
}
employee_data = pd.DataFrame(data=data)
display(employee_data)
# 按 'Salary' 列降序排序,并将缺失值放在开头
df1 = employee_data.sort_values(by="Salary", na_position="first", ascending=False)
display(df1)
# 先按 'Department' 升序排序,再按 'Salary' 降序排序
df2 = employee_data.sort_values(by=["Department", "Salary"], ascending=[True, False])
display(df2)
3.返回属性 n 大或者 n 小的值
nlargest() 和 nsmallest() 方法用于高效地获取 DataFrame 或 Series 中最大或最小的 n 个值。它们比先排序再切片更高效,尤其是在只需要少数几个最大/最小值时。
df.nlargest(n, columns, keep='first'):- 根据指定列的值,返回 DataFrame 中最大的
n行。 n: 整数,要返回的行数。columns: 字符串或字符串列表,用于排序的列名。keep: 当存在重复值时如何处理。'first'(默认):保留第一次出现的重复项。'last':保留最后一次出现的重复项。'all':保留所有重复项。
- 根据指定列的值,返回 DataFrame 中最大的
df.nsmallest(n, columns, keep='first'):- 根据指定列的值,返回 DataFrame 中最小的
n行。 - 参数与
nlargest()相同。
- 根据指定列的值,返回 DataFrame 中最小的
nlargest()和nsmallest()在底层使用了优化的选择算法(例如,部分排序或基于堆的选择算法),而不是对整个 DataFrame 进行完全排序。这使得它们在n远小于 DataFrame 总行数时,比sort_values().head(n)或sort_values().tail(n)更加高效。
排行榜: 找出销售额最高的 10 个产品,或评分最高的 5 名学生。
异常值初步检测: 快速查看数据集中最极端的大值或小值。
数据探索: 快速了解数据分布的尾部特征。
1
2
3
4
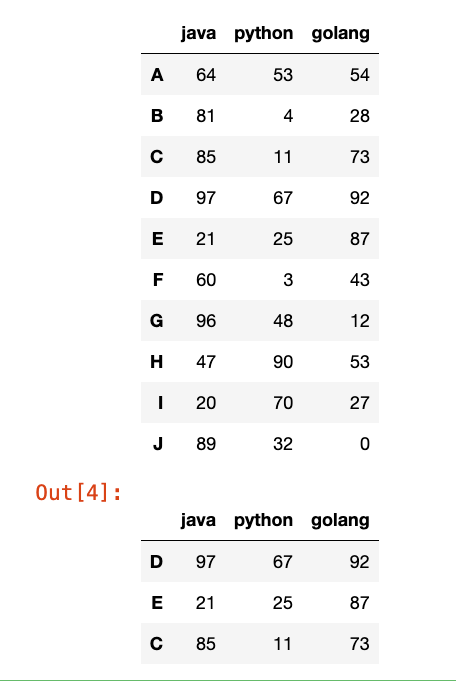
data = np.random.randint(0, 101, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "golang"])
display(df)
df.nlargest(3, columns="golang")
1
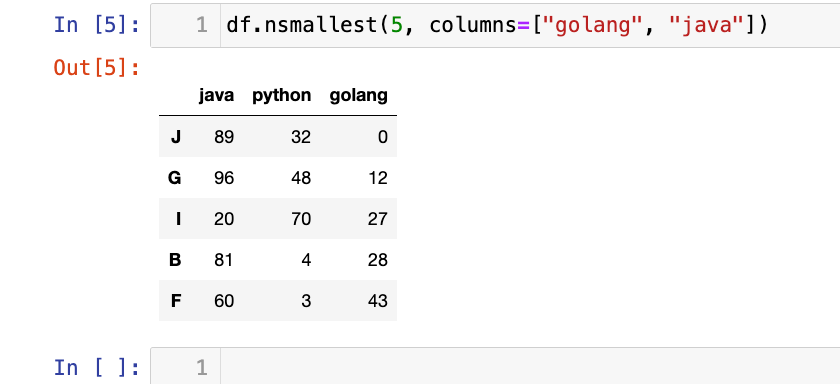
df.nsmallest(5, columns=["golang", "java"])
选择题
- 比
df.sort_values(by='Price').head(3)更高效的场景是?
A. 当 DataFrame 非常小的时候。
B. 当需要获取所有行时。
C. 当 n(要返回的行数)远小于 DataFrame 的总行数时。
D. 当 DataFrame 包含大量缺失值时。
答案:C