分组聚合是数据分析中非常强大和常用的操作,它遵循“分-组-合”(Split-Apply-Combine)的范式:
- 分(Split): 根据某个(或多个)键将数据拆分成组。
- 组(Apply): 对每个组独立地应用一个函数(例如,聚合、转换或过滤)。
- 合(Combine): 将各个组的结果合并成一个最终的数据结构。
1.分组 (groupby)
df.groupby() 方法是实现“分”操作的核心。它返回一个 GroupBy 对象,这个对象本身是可迭代的,但其主要目的是用于后续的聚合、转换或过滤操作。
- 基本语法:
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, dropna=True)by: 用于分组的键。可以是:- 列名(字符串)或列名列表。
- Series(与 DataFrame 长度相同)。
- 字典(用于按列分组)。
- 函数(应用于索引或列的每个元素)。
axis: 默认为0(按行分组),也可以设置为1(按列分组)。as_index: 布尔值,如果为True(默认),则分组键将作为结果 DataFrame 的索引。如果为False,则分组键将作为常规列。level: 当索引是多层索引时,指定要分组的级别。
- 分组后的可迭代对象:
GroupBy对象是一个可迭代对象,每次迭代返回一个元组(组名, 组数据)。
groupby()操作的内部机制是构建一个哈希表来映射每个唯一的分组键到其对应的行索引。这使得pandas能够快速地将数据拆分成组,而无需实际复制数据块。GroupBy对象本身并不立即执行任何计算,它只是存储了分组信息。实际的计算发生在您调用聚合函数(如mean(),sum())或apply(),transform()等方法时。
多列分组: df.groupby(by=['class', 'sex']) 可以创建更细粒度的分组。
对 Series 分组: df['Python'].groupby(df['class']) 可以对 Series 进行分组。
按数据类型分组: df.groupby(df.dtypes, axis=1) 可以按列的数据类型进行分组(通常用于对不同类型列应用不同操作)。
通过字典进行分组: df.groupby(mapping_dict, axis=1) 可以根据字典将列映射到自定义组。
get_group(): g.get_group('组名') 可以直接获取某个特定组的数据。
【1】先分组再获取数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
data = {
"sex": np.random.randint(0, 2, (30, )), # 0:男, 1:女
"class": np.random.randint(1, 4, (30,)),
"python": np.random.randint(0, 151, (30, )),
"java": np.random.randint(0, 151, (30, )),
"golang": np.random.randint(0, 151, (30, )),
"cpp": np.random.randint(0, 151, (30, )),
"scala": np.random.randint(0, 151, (30, ))
}
df = pd.DataFrame(data=data)
df["sex"] = df["sex"].map({0:"男", 1:"女"})
display(df)
sex_python_java = df.groupby(by="sex")[["python", "java"]]
for name, data in sex_python_java:
print(name)
print(data)
也可以根据多列分组:
1
2
3
4
class_sex_python = df.groupby(by=["sex", "class"])[["python"]]
for (sex, class_), data in class_sex_python:
print(sex, class_)
print(data)

【2】对一列值进行分组:
1
2
3
4
res1 = df["golang"].groupby(df["class"])
for item, data in res1:
print(item)
print(data)

也可以对一列值进行多分组:
1
2
3
4
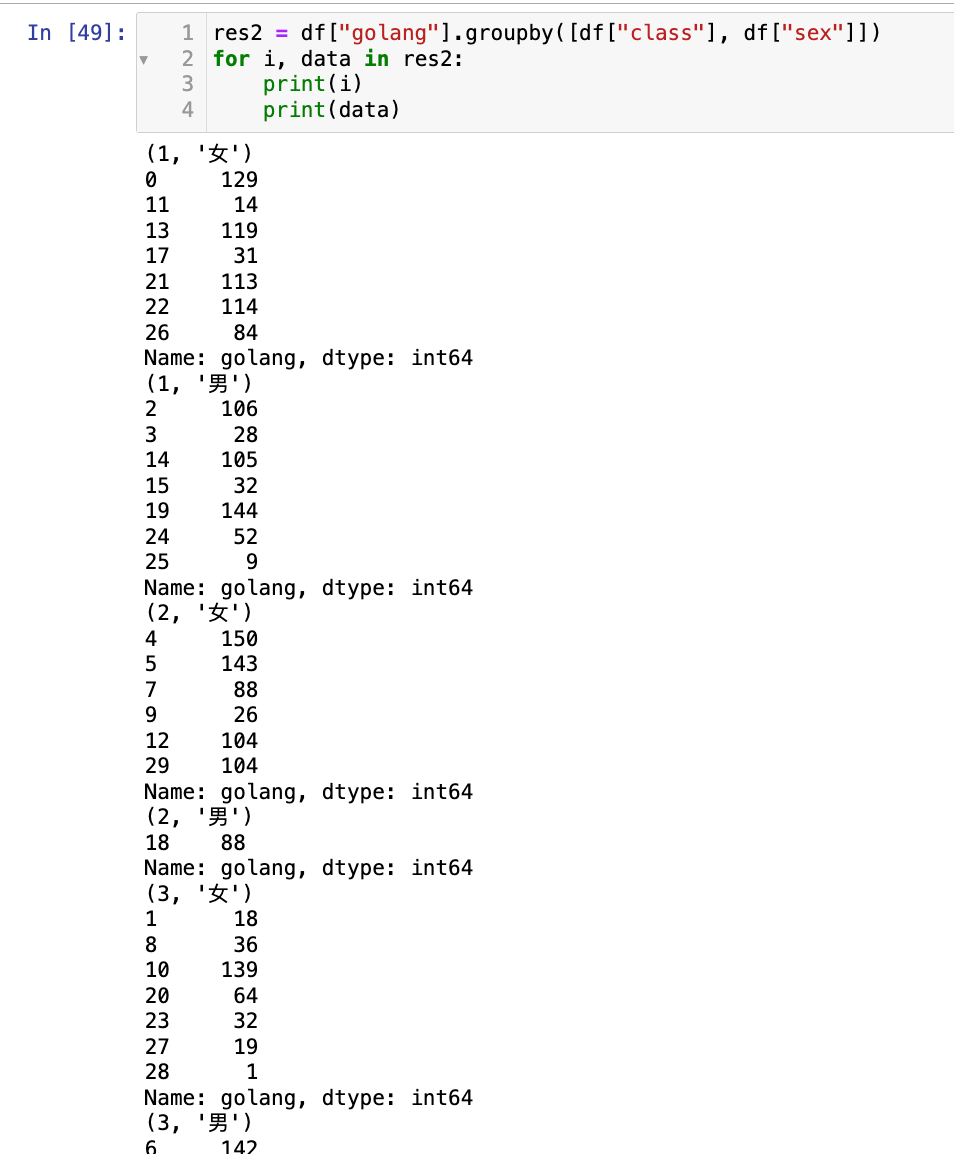
res2 = df["golang"].groupby([df["class"], df["sex"]])
for i, data in res2:
print(i)
print(data)
【3】按照数据类型进行分组:
1
2
3
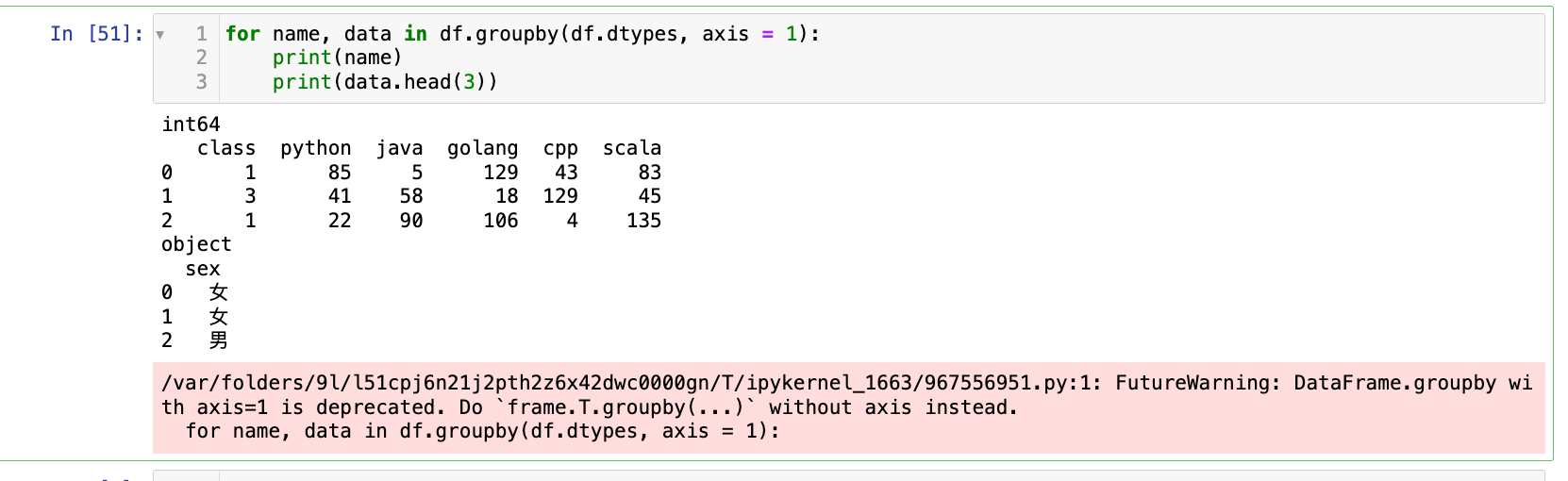
for name, data in df.groupby(df.dtypes, axis = 1):
print(name)
print(data.head(3))
【4】通过字典进行分组:
1
2
3
4
5
6
7
8
9
10
11
12
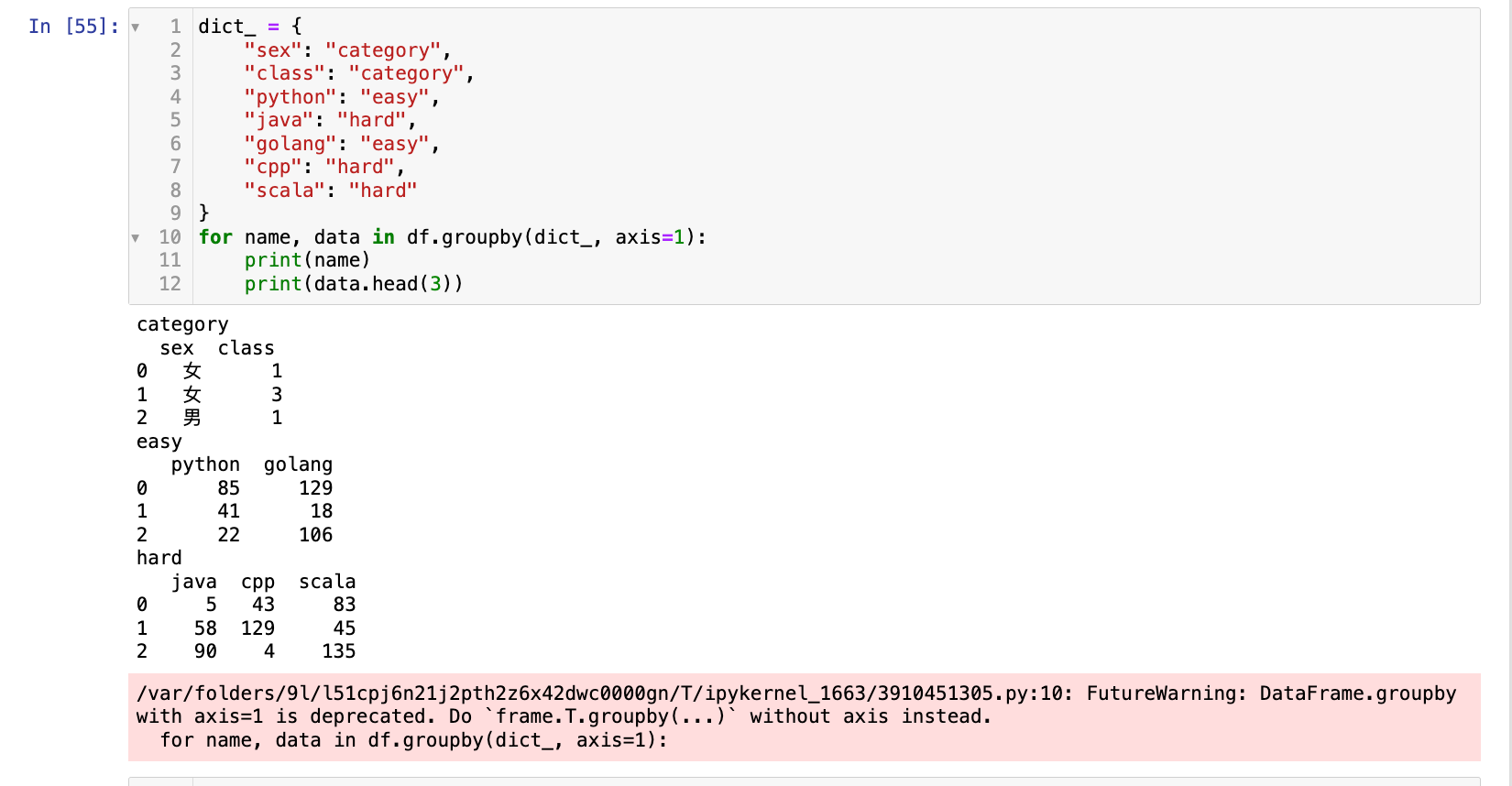
dict_ = {
"sex": "category",
"class": "category",
"python": "easy",
"java": "hard",
"golang": "easy",
"cpp": "hard",
"scala": "hard"
}
for name, data in df.groupby(dict_, axis=1):
print(name)
print(data.head(3))
选择题
-
df.groupby(by='category')返回的对象类型是什么?A. DataFrame B. Series C. GroupBy D. 列表
答案:C
-
在
df.groupby(by=['col1', 'col2'])中,['col1', 'col2']的作用是?A. 仅选择
col1和col2两列。B. 将数据按
col1和col2的唯一组合进行分组。C. 将数据按
col1或col2的唯一值进行分组。D. 报错。
答案:B
编程题
- 创建一个 DataFrame
sales_data,包含'Region','Product_Category','Sales'三列,以及 10 行数据。Region包含'East','West'。Product_Category包含'Electronics','Clothing'。Sales填充随机整数。
- 按
'Region'分组,并遍历每个组,打印组名和该组的前 2 条记录。 - 按
'Region'和'Product_Category'进行多级分组,并获取'East'区域'Electronics'类别的销售数据。 - 打印每一步操作后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
data = {
"Region": np.random.randint(0, 2, (10, )),
"Product_Category": np.random.randint(0, 2, (10, )),
"Sales": np.random.randint(0, 100, (10,))
}
sales_data = pd.DataFrame(data=data)
sales_data["Region"] = sales_data["Region"].map({0:"East", 1:"West"})
sales_data["Product_Category"] = sales_data["Product_Category"].map({0:"Electronics", 1:"Clothing"})
display(sales_data)
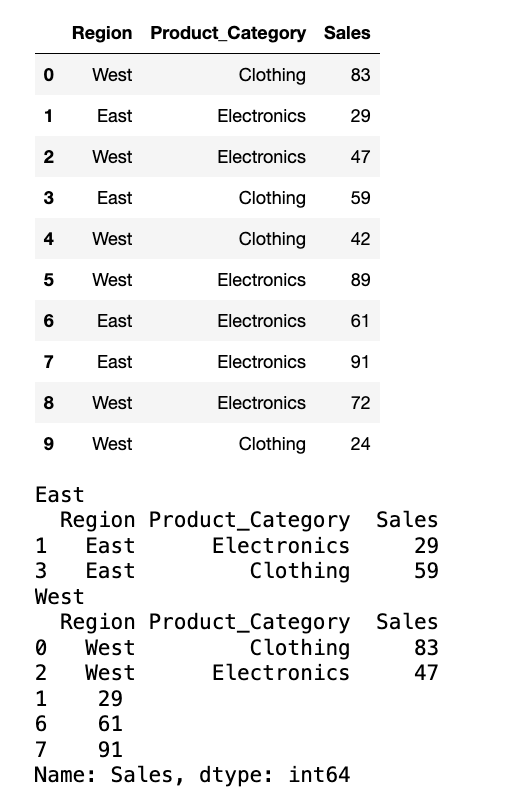
# 按 'Region' 分组,并遍历每个组,打印组名和该组的前 2 条记录。
g1 = sales_data.groupby(by="Region")
for name, data in g1:
print(name)
print(data.head(2))
# 按 'Region' 和 'Product_Category' 进行多级分组,并获取 'East' 区域 'Electronics' 类别的销售数据。
g2 = sales_data.groupby([sales_data.Region, sales_data.Product_Category])
for name, data in g2:
if name[0] == "East" and name[1] == "Electronics":
print(data["Sales"])
2.分组聚合
在创建了 GroupBy 对象后,最常见的操作就是对其应用聚合函数。聚合函数会将每个组的数据汇总成一个单一的值。
- 直接调用聚合函数:
g.mean(): 计算每个组的平均值。g.sum(): 计算每个组的总和。g.max(): 计算每个组的最大值。g.min(): 计算每个组的最小值。g.median(): 计算每个组的中位数。g.std(): 计算每个组的标准差。g.var(): 计算每个组的方差。g.count(): 计算每个组的非NA值数量。g.size(): 计算每个组的元素数量(包括NA值)。g.describe(): 为每个组生成描述性统计信息。
这是“分-组-合”范式中的“应用”和“组合”步骤。
- 应用:
pandas会遍历GroupBy对象中的每个组,并将聚合函数应用于该组的数据(通常是 Series 或 DataFrame 的子集)。- 组合: 将每个组的聚合结果收集起来,并组合成一个新的 Series 或 DataFrame。新的 Series/DataFrame 的索引将是分组键。
选择合适的聚合函数: 根据数据类型和分析目标选择合适的聚合函数。例如,对于分类数据,size() 或 count() 更合适;对于数值数据,可以使用 mean(), sum(), median() 等。
多列聚合: 如果在 groupby() 之后选择了多列(例如 df.groupby(...)[['col1', 'col2']]),那么聚合函数会独立地应用于这些列。
链式操作: df.groupby(...).mean().round(1) 可以在聚合后继续进行操作。
【1】准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
# 准备数据:
data = {
"sex": np.random.randint(0, 2, (30, )), # 0:男, 1:女
"class": np.random.randint(1, 4, (30,)),
"python": np.random.randint(0, 151, (30, )),
"java": np.random.randint(0, 151, (30, )),
"golang": np.random.randint(0, 151, (30, )),
"cpp": np.random.randint(0, 151, (30, )),
"scala": np.random.randint(0, 151, (30, ))
}
df = pd.DataFrame(data=data)
df["sex"] = df["sex"].map({0:"男", 1:"女"})
display(df)

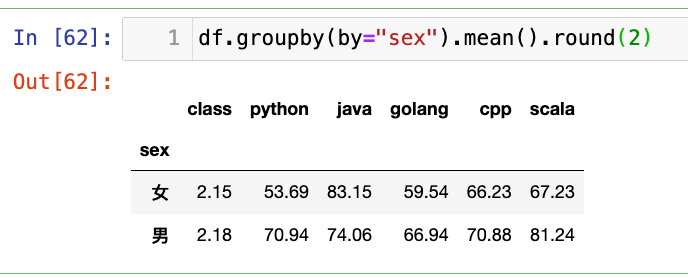
【2】按照性别进行分组,其他列进行均值聚合:
1
df.groupby(by="sex").mean().round(2)
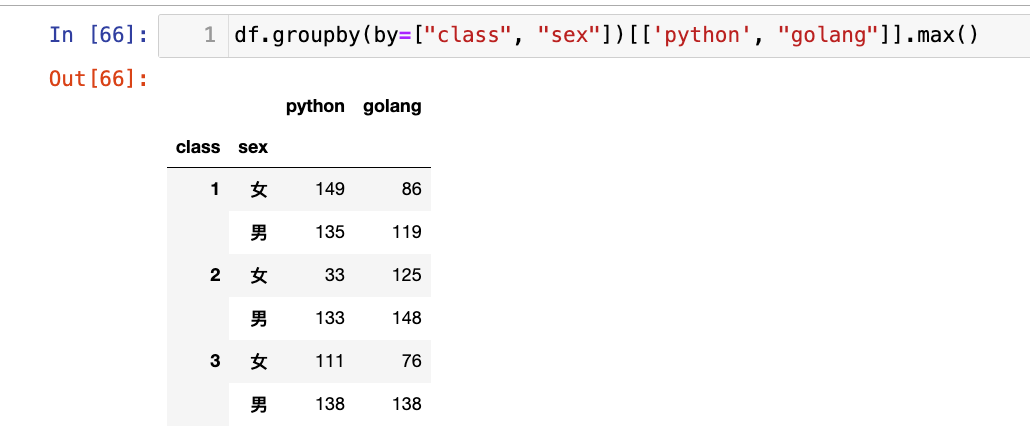
【3】按照班级和性别进行分组,求python和golang的最大值
1
df.groupby(by=["class", "sex"])[['python', "golang"]].max()
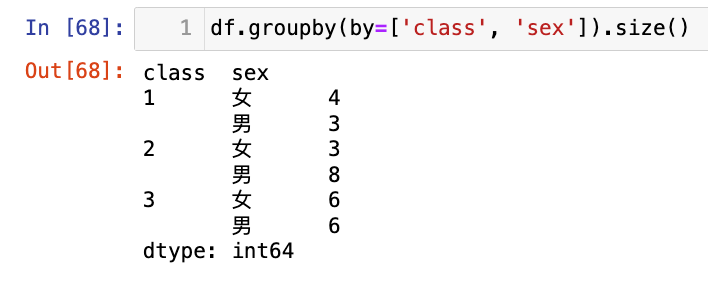
【4】按照班级和性别进行分组,计数聚合,统计人数
1
df.groupby(by=['class', 'sex']).size()
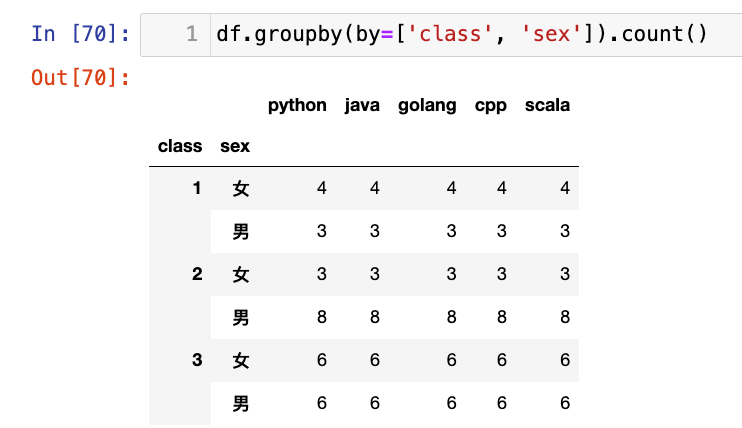
注意区别:
1
df.groupby(by=['class', 'sex']).count()
【5】基本描述性统计聚合:
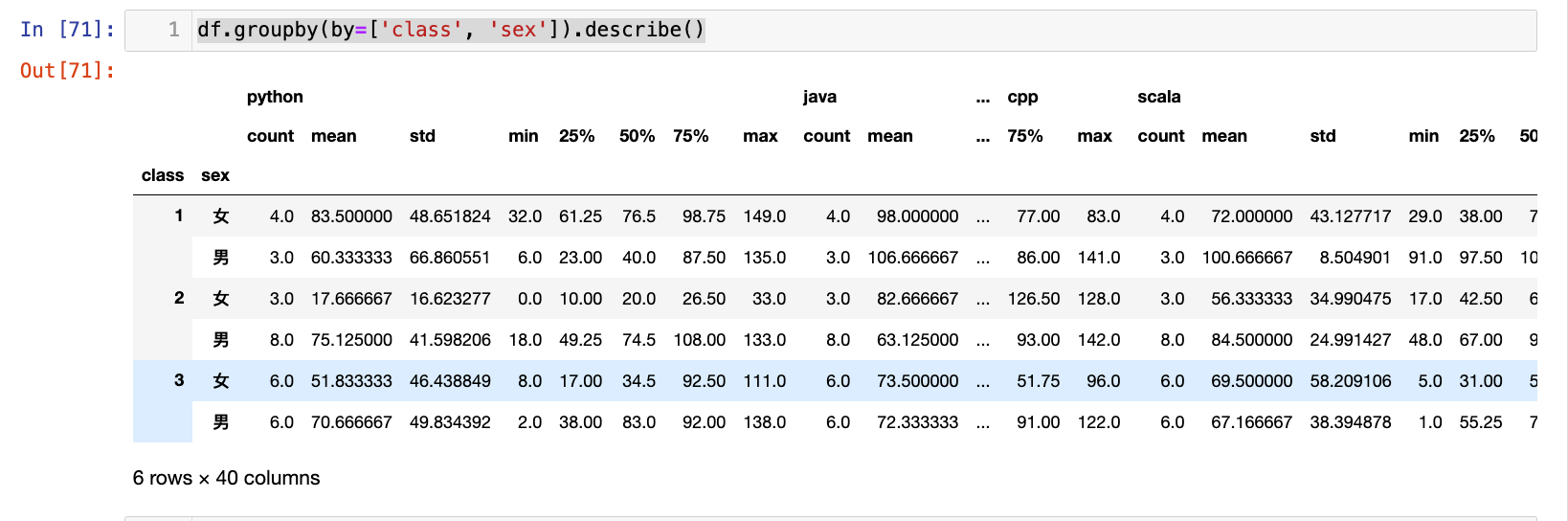
1
df.groupby(by=['class', 'sex']).describe()
选择题
-
给定
df = pd.DataFrame({'A': ['x', 'y', 'x'], 'B': [1, 2, 3]}),执行df.groupby('A')['B'].sum()的结果是什么?A.
Series([4, 2], index=['x', 'y'])B.
Series([1, 2, 3], index=['x', 'y', 'x'])C.
DataFrame形状为(2, 1)。D. 报错。
答案:A
-
df.groupby('category').size()和df.groupby('category').count()的区别是什么?A.
size()计算组中所有元素的数量(包括NaN),count()计算非NaN元素的数量。B.
size()计算非NaN元素的数量,count()计算所有元素的数量。C.
size()只能用于 Series,count()只能用于 DataFrame。D. 它们没有区别。
答案:A
编程题
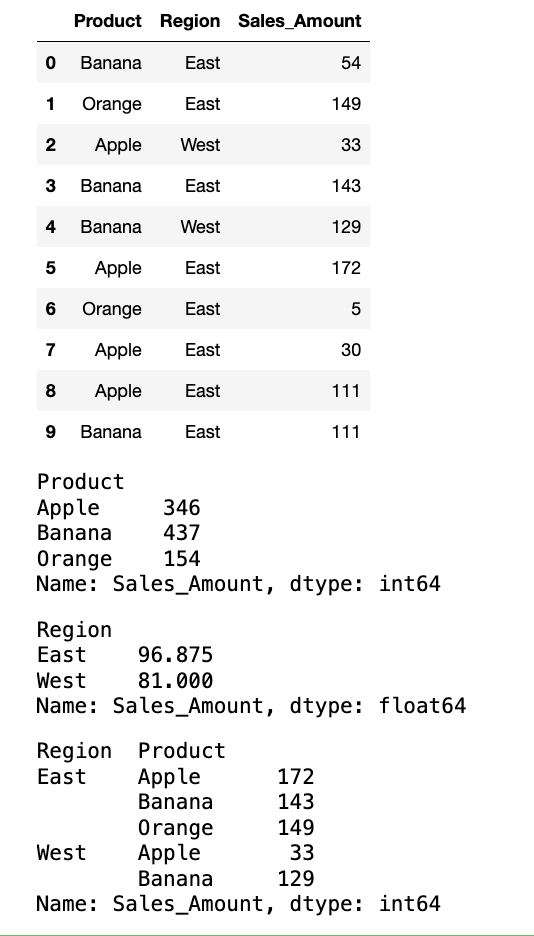
- 创建一个 DataFrame
sales_records,包含'Product','Region','Sales_Amount'三列,以及 10 行数据。 - 计算每个
'Product'的总销售额。 - 计算每个
'Region'的平均销售额。 - 计算每个
'Product'在每个'Region'的最高销售额。 - 打印每一步操作后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
data = {
"Product": np.random.randint(0, 3, (10, )),
"Region": np.random.randint(0, 2, (10, )),
"Sales_Amount": np.random.randint(0, 200, (10, ))
}
df = pd.DataFrame(data=data)
df["Product"] = df["Product"].map({0: "Apple", 1: "Banana", 2: "Orange"})
df["Region"] = df["Region"].map({0: "East", 1: "West"})
display(df)
# 计算每个 'Product' 的总销售额。
display(df.groupby(by=["Product"])["Sales_Amount"].sum())
# 计算每个 'Region' 的平均销售额
display(df.groupby(by=["Region"])["Sales_Amount"].mean())
# 计算每个 'Product' 在每个 'Region' 的最高销售额
display(df.groupby(by=["Region", "Product"])["Sales_Amount"].max())
3.分组聚合 apply, transform
apply() 和 transform() 是 GroupBy 对象上两个非常重要的函数,它们允许您对分组数据执行更复杂或形状保持的计算。
GroupBy.apply(func, *args, **kwargs):- 将任意函数
func应用于每个组。 func会接收每个组的数据(通常是一个 Series 或 DataFrame)作为其第一个参数。apply()是最灵活的,它可以返回:- 一个标量(聚合)。
- 一个 Series(转换,结果长度可能与组长度不同)。
- 一个 DataFrame(转换,结果形状可能与组形状不同)。
- 返回分组结果: 聚合结果的索引是分组键。转换结果的索引通常是原始索引。
- 将任意函数
GroupBy.transform(func, *args, **kwargs):- 将函数
func应用于每个组,并将结果广播回原始 DataFrame 的形状。 func会接收每个组的数据作为其第一个参数。- 关键特点:
transform()返回的 Series 或 DataFrame 的形状必须与原始输入相同。这意味着func必须返回:- 一个标量(会被广播到组中的所有行)。
- 一个与组长度相同的 Series。
- 返回全数据: 结果的索引是原始 DataFrame 的索引。
- 将函数
apply()的原理:apply()的灵活性来自其内部的智能逻辑。它会尝试推断func的返回类型,并相应地组合结果。如果func返回的是标量,它会进行聚合;如果返回的是 Series 或 DataFrame,它会尝试进行转换(例如,按索引对齐)。transform()的原理:transform()的核心是“广播”。它在每个组上执行计算,然后将计算结果(无论是标量还是 Series)“拉伸”或“复制”回原始组的形状。这在需要用组的统计量来修改或创建新特征时非常有用,例如用组均值填充缺失值,或计算每个数据点在其组内的 Z-score。
选择apply还是transform?
选择 apply():
- 当您需要对每个组执行复杂操作,且结果的形状或类型可能与原始组不同时。
- 当您需要对每个组进行自定义聚合,例如计算某个百分位数或执行自定义的统计检验。
- 当您需要返回一个包含多个新列的 DataFrame。
选择 transform():
- 当您需要对每个组执行操作,并将结果广播回原始 DataFrame 的形状时。
- 当您需要用组的聚合值来填充缺失值、标准化数据或创建新的特征列时。
- 当您需要确保操作后 DataFrame 的行数与原始 DataFrame 保持一致时。
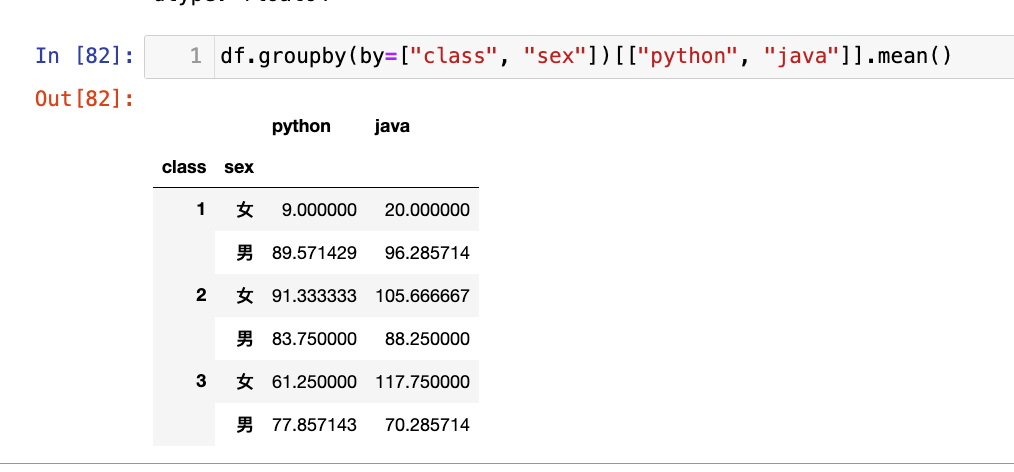
【1】按照班级性别进行分组,对python和java进行均值聚合:
1
2
3
4
5
6
7
8
9
10
11
12
13
data = {
"sex": np.random.randint(0, 2, (30, )), # 0:男, 1:女
"class": np.random.randint(1, 4, (30,)),
"python": np.random.randint(0, 151, (30, )),
"java": np.random.randint(0, 151, (30, )),
"golang": np.random.randint(0, 151, (30, )),
"cpp": np.random.randint(0, 151, (30, )),
"scala": np.random.randint(0, 151, (30, ))
}
df = pd.DataFrame(data=data)
df["sex"] = df["sex"].map({0:"男", 1:"女"})
display(df)
df.groupby(by=["class", "sex"])[["python", "java"]].apply(np.mean)

注意区别:
【2】apply返回的是一个Series:
1
2
3
4
def rank_score(group):
return group.rank(pct=True) # 返回百分比排名
df.groupby(by=["class", "sex"])['python'].apply(rank_score)

【3】transform返回和原df的shape一样。
1
2
3
4
5
6
7
8
9
10
11
def normalization(x): # 归一化
# x是一个Series(某个df的一列)
min_val = x.min()
max_val = x.max()
# 确保分母不能是0
if max_val == min_val:
return x - min_val # 如果所有值都相等,归一化为0
return (x-min_val) / (max_val - min_val)
# 按照班级和性别进行分组,python,java 这2列归一化
df.groupby(by=["class", "sex"])[["python", "java"]].transform(normalization).round(3)
【4】用组均值填充NaN:(transform的经典应用)
1
2
3
4
df_with_nan = df.copy()
df_with_nan.loc[[5, 10], "python"] = None
display(df_with_nan)
df_with_nan.groupby(by=["class", 'sex'])["python"].transform(lambda x: x.fillna(x.mean()))
选择题
-
以下哪个方法在分组聚合后,返回的 DataFrame 形状与原始 DataFrame 形状相同?
A.
df.groupby(...).mean()B.
df.groupby(...).apply(...)(当apply返回标量时)C.
df.groupby(...).transform(...)D.
df.groupby(...).describe()答案:C
-
df.groupby('category')['value'].apply(lambda x: x.max() - x.min())的作用是?A. 计算每个类别的最大值。
B. 计算每个类别的最小值。
C. 计算每个类别中值的范围(最大值减最小值)。
D. 将每个类别中的所有值替换为该类别的范围。
答案:C
编程题
- 创建一个 DataFrame
employee_records,包含'Department','Gender','Salary'三列,以及 15 行数据。Department包含'HR','IT','Sales'。Gender包含'Male','Female'。Salary填充随机整数。
- 使用
apply()方法计算每个部门的男女员工的平均薪资,并打印结果。 - 使用
transform()方法计算每个部门的薪资占该部门总薪资的比例,并将结果作为新列'Salary_Ratio_Dept'添加到 DataFrame 中。 - 使用
transform()方法计算每个部门的薪资的 Z-score,并将结果作为新列'Salary_Zscore_Dept'添加到 DataFrame 中。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
data = {
"Department": np.random.randint(0, 3, (15, )),
"Gender": np.random.randint(0, 2, (15, )),
"Salary": np.random.randint(10000, 50000, (15, ))
}
employee_records = pd.DataFrame(data=data)
employee_records["Department"] = employee_records["Department"].map({0: "HR", 1: "IT", 2: "Sales"})
employee_records["Gender"] = employee_records["Gender"].map({0: "Male", 1: "Female"})
display(employee_records)
# 使用 apply() 方法计算每个部门的男女员工的平均薪资,并打印结果
res1 = employee_records.groupby(by=["Department", "Gender"]).apply(np.mean)
display(res1)
# 使用 transform() 方法计算每个部门的薪资占该部门总薪资的比例,并将结果作为新列 'Salary_Ratio_Dept' 添加到 DataFrame 中。
employee_records["Salary_Ratio_Dept"] = employee_records.groupby(by=["Department"])["Salary"].transform(lambda x: x / x.sum())
display(employee_records)
# 使用 transform() 方法计算每个部门的薪资的 Z-score,并将结果作为新列 'Salary_Zscore_Dept' 添加到 DataFrame 中
employee_records["Salary_Zscore_Dept"] = employee_records.groupby(by=["Department"])["Salary"].transform(lambda x: (x - x.mean())/ x.std())
display(employee_records)
4.分组聚合 agg
agg() 方法是 GroupBy 对象上最强大和灵活的聚合函数之一。它允许您对每个组应用一个或多个聚合函数,甚至可以对不同的列应用不同的聚合函数。
- 基本语法:
g.agg(func)或g.agg(dict)func: 可以是:- 单个函数(例如
np.mean,'sum')。 - 函数名字符串列表(例如
['mean', 'max'])。 - 字典:键是列名,值是单个函数、函数列表或元组
(新列名, 函数)。
- 单个函数(例如
- 应用单个函数或函数列表到所有聚合列:
g.agg(np.max):对所有聚合列应用np.max。g.agg(['max', 'min', 'count']):对所有聚合列应用多个函数。
- 对不同属性应用多种不同统计汇总:
g.agg({'col1': 'sum', 'col2': ['min', 'max']}):对col1求和,对col2求最小和最大值。g.agg({'col1': [('Max_Val', np.max)], 'col2': [('Count', 'count'), ('Median_Val', np.median)]}):使用元组为聚合结果指定新的列名。
agg()方法在底层会高效地遍历每个组,并为每个指定的列和函数执行计算。它的灵活性在于能够处理各种函数签名和返回类型,并智能地组织最终结果 DataFrame 的列名。当使用字典和元组指定新列名时,pandas会在内部构建一个映射,确保输出 DataFrame 的列名清晰且可读。
自定义报告: 生成包含多种统计指标的摘要报告。
多维度分析: 在一个操作中完成多个维度的聚合。
特征工程: 从原始特征中派生出多个聚合特征。
命名聚合: 使用元组为聚合结果指定自定义名称,提高结果的可读性。
准备数据:
1
2
3
4
5
6
7
8
9
10
11
12
data = {
"sex": np.random.randint(0, 2, (30, )), # 0:男, 1:女
"class": np.random.randint(1, 4, (30,)),
"python": np.random.randint(0, 151, (30, )),
"java": np.random.randint(0, 151, (30, )),
"golang": np.random.randint(0, 151, (30, )),
"cpp": np.random.randint(0, 151, (30, )),
"scala": np.random.randint(0, 151, (30, ))
}
df = pd.DataFrame(data=data)
df["sex"] = df["sex"].map({0:"男", 1:"女"})
display(df)
1
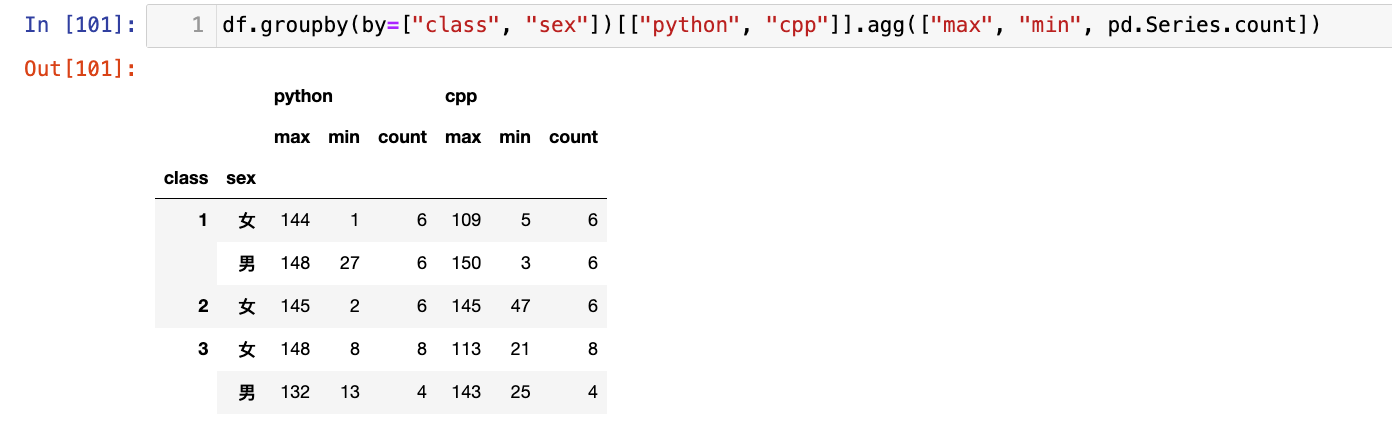
df.groupby(by=["class", "sex"])[["python", "cpp"]].agg(["max", "min", pd.Series.count])
1
2
3
4
df.groupby(by=["class", "sex"])[["python", "cpp"]].agg({
"python": [("最大值", "max"), ("最小值", "min")],
"cpp": [("计数", pd.Series.count), ("中位数", "median")]
})
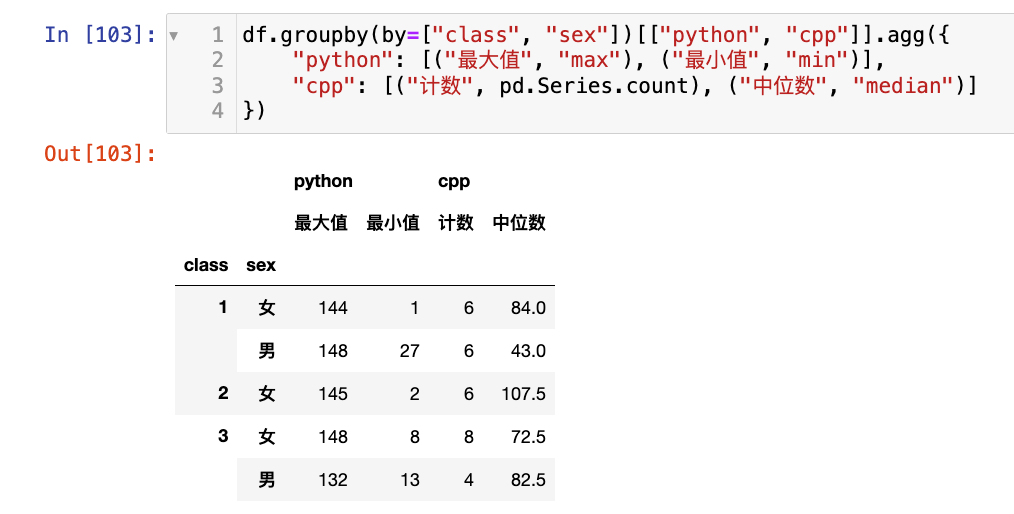
也可以传自定义的函数作为参数。
选择题
-
以下哪个
agg()调用会计算每个组的'Sales'列的总和,并将结果列命名为'Total_Sales'?A.
g.agg({'Sales': 'sum'})B.
g.agg({'Sales': [('Total_Sales', 'sum')]})C.
g.agg('sum', columns='Sales')D.
g.agg(Total_Sales='sum')答案:B
-
df.groupby('category')['value'].agg(['mean', 'median'])的结果是什么?A. 一个 Series,包含每个类别的均值和中位数。
B. 一个 DataFrame,包含两列(’mean’, ‘median’),索引是类别。
C. 一个 DataFrame,包含两列(’value_mean’, ‘value_median’),索引是类别。
D. 报错。
答案:B
编程题
- 创建一个 DataFrame
product_reviews,包含'Product_ID','Rating','Review_Length'三列,以及 20 行数据。Product_ID包含'P1','P2','P3'。Rating填充 1 到 5 的随机整数。Review_Length填充 50 到 500 的随机整数。
- 按
Product_ID分组,并使用agg()计算每个产品的:- 平均评分(命名为
'Avg_Rating')。 - 最高评分(命名为
'Max_Rating')。 - 评论数量(命名为
'Num_Reviews')。
- 平均评分(命名为
- 按
Product_ID分组,并使用agg()对'Rating'列计算中位数,对'Review_Length'列计算平均值。 - 打印每一步操作后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
data = {
"Product_ID": np.random.randint(0, 3, (20, )),
"Rating": np.random.randint(1, 6, (20, )),
"Review_Length": np.random.randint(50, 501, (20, ))
}
df = pd.DataFrame(data=data)
df["Product_ID"] = df["Product_ID"].map({0: "P1", 1: "P2", 2: "P3"})
display(df)
# 分组
g = df.groupby(by="Product_ID")
# 平均评分(命名为 'Avg_Rating')
display(g.agg({
"Rating": [("Avg_Rating", "mean"), ("Max_Rating", "max")],
"Review_Length": [("Num_Reviews", pd.Series.count)]
}))
display(g.agg({
"Rating":"median",
"Review_Length": "mean"
}))
5.透视表 pivot_table
pivot_table() 函数是 pandas 中用于创建电子表格风格的透视表(pivot table)的强大工具。它允许对数据进行分组、聚合和重塑,以多维方式汇总数据。透视表本质上是一种特殊形式的 groupby 聚合操作,结合了 unstack 的功能。
关于pandas的unstack函数参考博客:pandas-数据转换和数据重塑
- 基本语法:
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)data: 要透视的 DataFrame。values: 字符串或字符串列表,指定要聚合的列。index: 字符串或字符串列表,指定用作新 DataFrame 行索引的列。columns: 字符串或字符串列表,指定用作新 DataFrame 列索引的列。aggfunc: 聚合函数。可以是单个函数(例如np.mean,'sum'),函数列表,或字典(键是values中的列名,值是函数或函数列表)。默认是np.mean。fill_value: 当透视表中出现NaN值时,用于填充的值。margins: 布尔值,如果为True,则添加行/列的总计(“All”)标签。margins_name: 总计标签的名称。
pivot_table()的工作流程可以概括为:
- 分组: 根据
index和columns参数指定的列,将数据拆分成组。- 聚合: 对每个组中
values列的数据应用aggfunc指定的聚合函数。- 重塑: 将
index列的值作为新的行索引,columns列的值作为新的列索引,聚合结果填充到相应的单元格中。它在内部实现了
groupby、聚合和unstack的组合操作,但以更简洁和用户友好的方式呈现。
多维度数据汇总: 快速生成按多个维度(例如,按地区、按产品、按月份)汇总的销售报告。
交叉分析: 比较不同类别之间的数据差异。
数据探索: 快速了解数据在不同维度上的分布和趋势。
缺失值处理: 使用 fill_value 参数在透视时填充 NaN。
总计计算: 使用 margins=True 方便地添加总计行和列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
data = {
"sex": np.random.randint(0, 2, (30, )), # 0:男, 1:女
"class": np.random.randint(1, 4, (30,)),
"python": np.random.randint(0, 151, (30, )),
"java": np.random.randint(0, 151, (30, )),
"golang": np.random.randint(0, 151, (30, )),
"cpp": np.random.randint(0, 151, (30, )),
"scala": np.random.randint(0, 151, (30, ))
}
df = pd.DataFrame(data=data)
df["sex"] = df["sex"].map({0:"男", 1:"女"})
display(df)
# 自定义一个计数的函数
def count_non_nan(x):
return len(x.dropna())
df1 = df.pivot_table(values=["python", "java", "cpp"], index=["class", "sex"], aggfunc={
"python": [("最大值", "max")],
"java": [("最小值", "min"), ("中位数", "median")],
"cpp": [("最小值", "min"), ("均值", "mean"), ("计数", count_non_nan)]
})
display(df1)

也可以添加列分组:
1
2
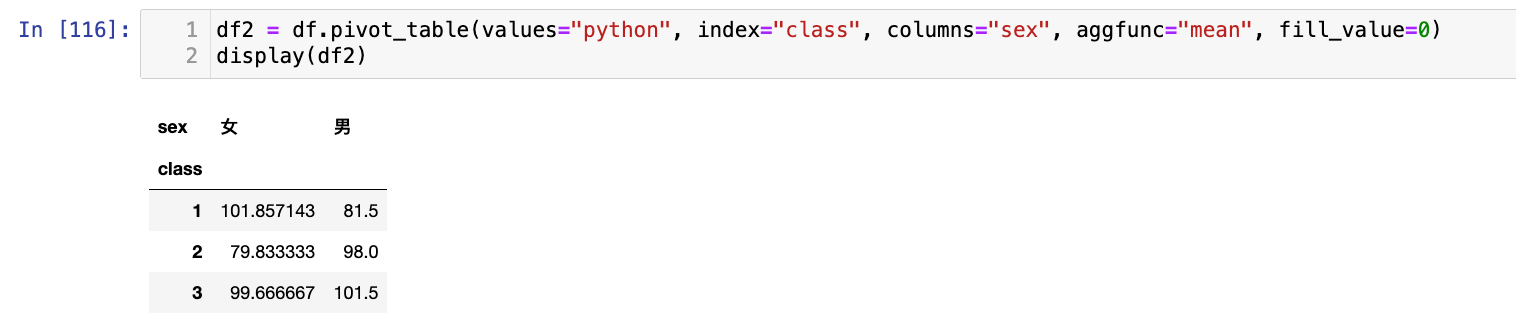
df2 = df.pivot_table(values="python", index="class", columns="sex", aggfunc="mean", fill_value=0)
display(df2)
添加总计:
1
2
3
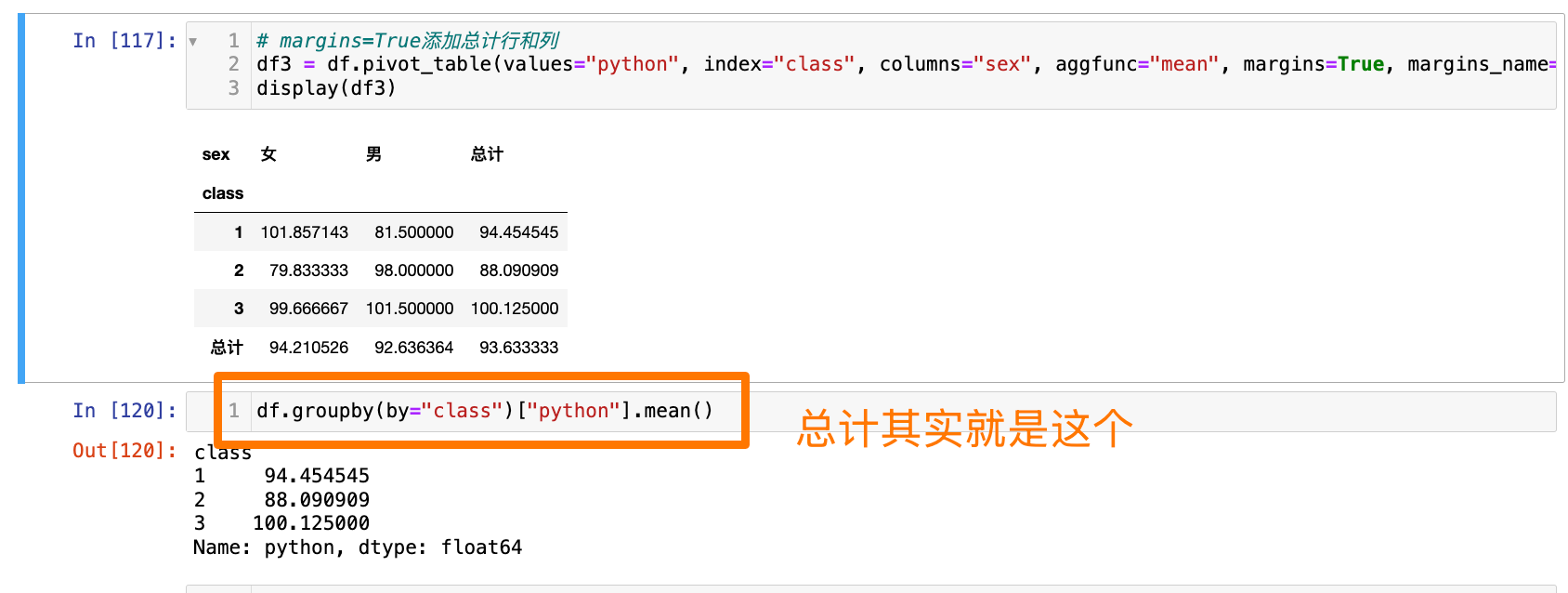
# margins=True添加总计行和列
df3 = df.pivot_table(values="python", index="class", columns="sex", aggfunc="mean", margins=True, margins_name="总计")
display(df3)
选择题
-
以下哪个函数可以用于创建电子表格风格的透视表,同时进行分组和聚合?
A.
df.groupby()B.df.pivot()C.pd.pivot_table()D.df.unstack()答案:C
-
在
pd.pivot_table()中,index参数的作用是?A. 指定要聚合的列。 B. 指定用作新 DataFrame 列索引的列。 C. 指定用作新 DataFrame 行索引的列。 D. 指定聚合函数。
答案:C
编程题
- 创建一个 DataFrame
sales_transactions,包含'Date','Region','Product','Amount'四列,以及 15 行数据。Date包含 3 个不同的日期。Region包含'North','South','East','West'。Product包含'A','B','C'。Amount填充随机整数。
- 创建一个透视表,显示每个
Region在每个Product上的总销售额。 - 创建一个透视表,显示每个
Date在每个Region上的平均销售额,并添加总计行和列。 - 创建一个透视表,显示每个
Region的Amount的最大值和最小值,以及每个Product的Amount的总和。 - 打印每一步操作后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 准备数据:
dates = pd.to_datetime(['2025-01-01', '2025-01-02', '2025-01-03'])
data = {
'Date': np.random.choice(dates, size=15),
'Region': np.random.choice(['North', 'South', 'East', 'West'], size=15),
'Product': np.random.choice(['A', 'B', 'C'], size=15),
'Amount': np.random.randint(100, 1000, size=15)
}
df = pd.DataFrame(data=data)
display(df)
# 创建一个透视表,显示每个 Region 在每个 Product 上的总销售额
p1 = df.pivot_table(values="Amount", index="Region", columns="Product", aggfunc="sum", fill_value=0)
display(p1)
# 创建一个透视表,显示每个 Date 在每个 Region 上的平均销售额,并添加总计行和列
p2 = df.pivot_table(values="Amount", index="Date", columns="Region", aggfunc="mean", margins=True, fill_value=0)
display(p2)
# 创建一个透视表,显示每个 Region 的 Amount 的最大值和最小值,以及每个 Product 的 Amount 的总和。
p3 = df.pivot_table("Amount", index="Region", columns="Product", aggfunc=["max", "min", "sum"], fill_value=0)
display(p3)