分箱操作(Binning),也称为面元划分或离散化,是将连续数据转换为分类(离散)对应物的过程。这在统计分析和机器学习中非常有用,例如将连续的年龄数据划分为“儿童”、“青少年”、“成年人”、“老年人”等类别。
分箱操作主要分为等距分箱和等频分箱。
1. 等宽分箱 (pd.cut)
等宽分箱(Equal-width binning)是将数据值的范围划分为大小相等的区间。每个区间(或“箱”)的宽度是相同的。
- 基本语法:
pd.cut(x, bins, right=True, labels=None, include_lowest=False, duplicates='raise')x: 要进行分箱的 Series 或一维数组。bins: 指定分箱的边界。- 整数
N:将数据范围划分为N个等宽的区间。 - 序列(列表或 NumPy 数组):指定自定义的区间边界。例如
[0, 60, 90, 150]。
- 整数
right: 布尔值,如果为True(默认),则区间是右闭合的(即(a, b])。如果为False,则区间是左闭合的(即[a, b))。labels: 列表或布尔值,用于指定分箱后每个区间的标签。如果为False,则返回整数指示分箱。include_lowest: 布尔值,如果为True,则第一个区间包含最小值(左闭合)。
pd.cut()的原理是根据数据的最大值和最小值,或者用户指定的边界,将整个数据范围划分为等宽的子区间。然后,它遍历每个数据点,判断其落在哪个区间内,并将其分配到对应的箱中。
- 优点: 简单直观,易于理解和实现。
- 缺点: 如果数据分布不均匀,可能会导致某些箱中数据点很多,而另一些箱中数据点很少,甚至为空。异常值可能会对箱的宽度产生很大影响。
自定义区间: bins 参数可以非常灵活地定义任意宽度的区间,这在根据业务规则进行分箱时非常有用(例如,年龄段、收入等级)。
有意义的标签: 使用 labels 参数可以为每个分箱后的类别赋予有意义的名称,提高可读性。
处理边界: right 和 include_lowest 参数可以精确控制区间的开闭情况,避免数据点落在区间边界时的歧义。
【1】平均分-分箱:
1
2
3
4
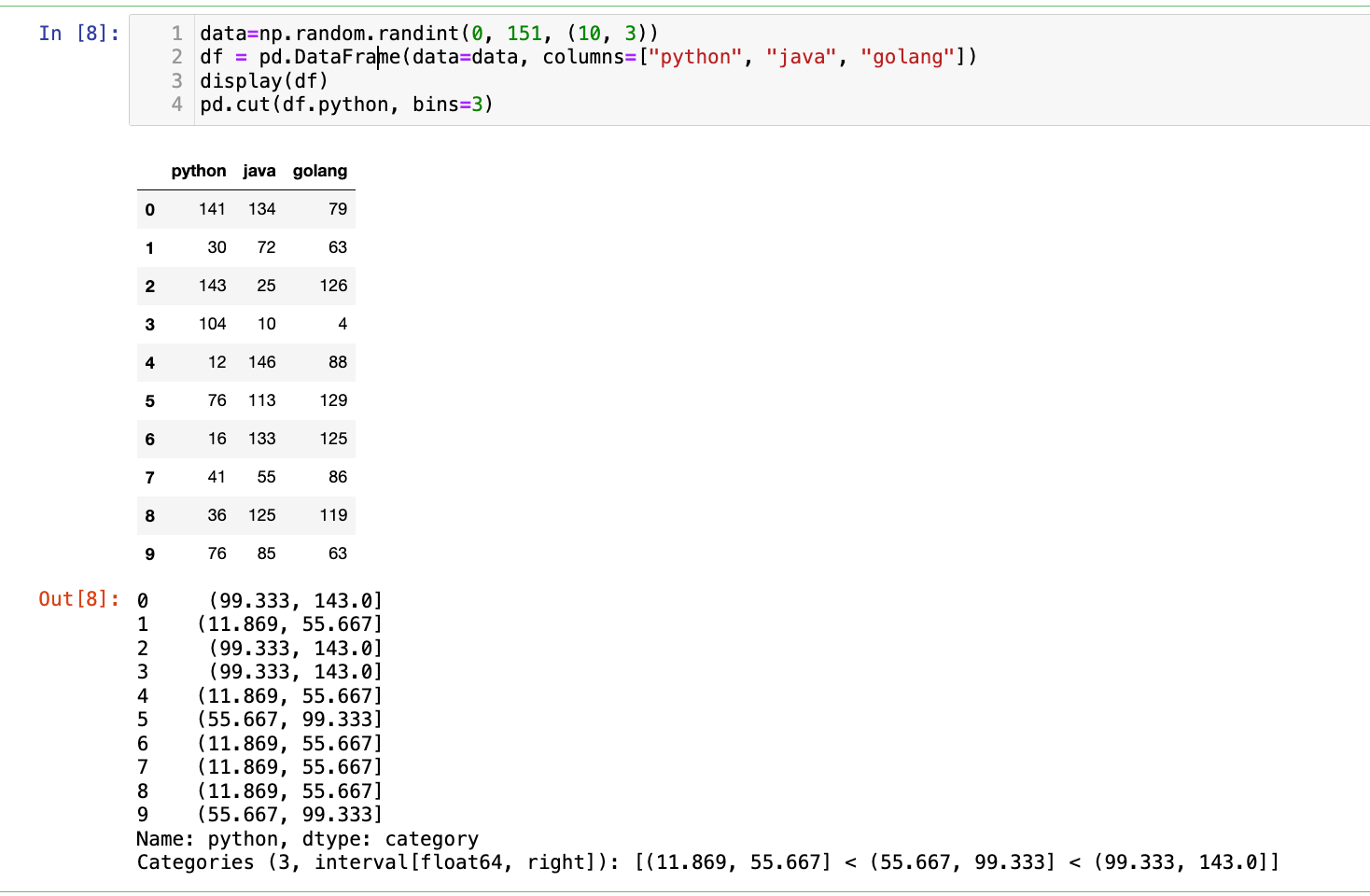
data=np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, columns=["python", "java", "golang"])
display(df)
pd.cut(df.python, bins=3)
1
2
3
4
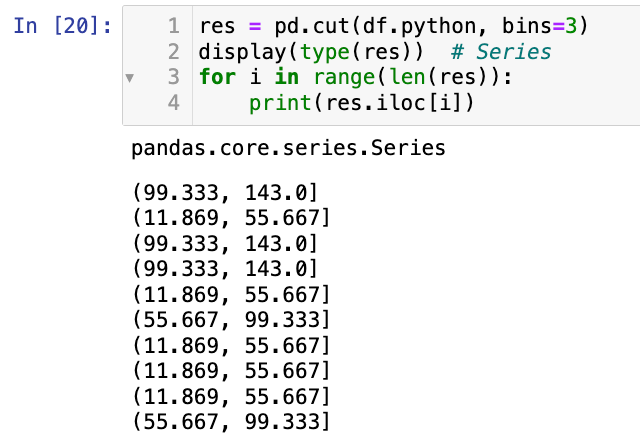
res = pd.cut(df.python, bins=3)
display(type(res)) # Series
for i in range(len(res)):
print(res.iloc[i])
【2】指定宽度分箱,并且添加标签(每个区间的名字):
1
2
3
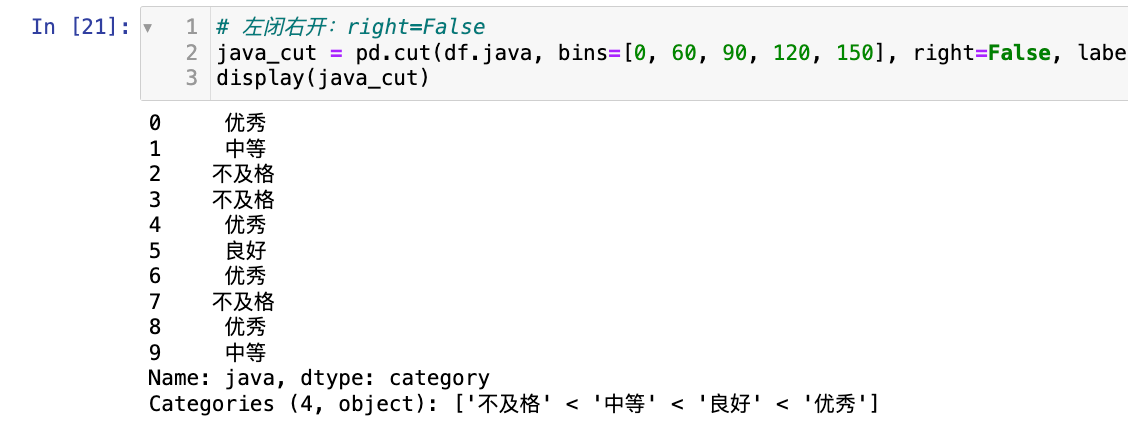
# 左闭右开:right=False
java_cut = pd.cut(df.java, bins=[0, 60, 90, 120, 150], right=False, labels=["不及格", "中等", "良好", "优秀"])
display(java_cut)
选择题
-
给定
s = pd.Series([10, 70, 120, 40]),执行pd.cut(s, bins=[0, 50, 100, 150], labels=['Low', 'Medium', 'High'])后,s的结果是什么?A.
Series(['Low', 'Medium', 'High', 'Low'])B.
Series(['Low', 'Medium', 'High', 'Low'], categories=['Low', 'Medium', 'High'])C.
Series(['Low', 'Medium', 'High', 'Low'], dtype='category')D.
Series(['Low', 'Medium', 'High', 'Low'], categories=['Low', 'Medium', 'High'], dtype='category')答案:C,结果是一个分类类型的 Series,值为
['Low', 'Medium', 'High', 'Low'],数据类型为 category,类别为['Low', 'Medium', 'High']。选项 C 正确地描述了结果:Series(['Low', 'Medium', 'High', 'Low'], dtype='category')。选项 D 错误,因为 pd.cut 的结果不会显式指定 categories 作为 Series 的构造参数,而是通过dtype='category'隐式包含类别信息。 -
pd.cut()方法中的right=False参数表示什么?A. 区间是右闭合的(例如
(a, b])。B. 区间是左闭合的(例如
[a, b))。C. 分箱后的标签会反转顺序。
D. 不会包含最小值。
答案:B。默认情况下,
right=True,区间为右闭合(a, b](不包含左端点 a,包含右端点 b)。
编程题
- 创建一个 Series
ages,包含 20 个随机整数,范围在 1 到 80 之间。 - 使用
pd.cut()将ages分箱为 4 个等宽的区间,并为每个区间指定标签:'Young','Adult','Middle-aged','Senior'。 - 使用
pd.cut()将ages分箱为自定义区间:[0, 18), [18, 35), [35, 60), [60, 80],并指定标签:'Child','Young Adult','Adult','Elderly'。 - 打印每一步操作后的 Series 及其每个类别的计数
1
2
3
4
5
6
7
8
9
ages = pd.Series(data=np.random.randint(1, 81, (20,)))
display(ages)
# 使用 pd.cut() 将 ages 分箱为 4 个等宽的区间,并为每个区间指定标签:'Young', 'Adult', 'Middle-aged', 'Senior'
res1 = pd.cut(ages, bins=4, labels=["Young", "Adult", "Middle-aged", "Senior"])
display(res1, res1.value_counts())
# 使用 pd.cut() 将 ages 分箱为自定义区间:[0, 18), [18, 35), [35, 60), [60, 80],
# 并指定标签:'Child', 'Young Adult', 'Adult', 'Elderly'。
res2 = pd.cut(ages, bins=[0, 18, 35, 60, 80], right=False, labels=["Child", "Young Adult", "Adult", "Elderly"])
display(res2, res2.value_counts())
2.等频分箱 (pd.qcut)
等频分箱(Equal-frequency binning),也称为基于分位数的分箱,是将数据划分为具有大致相等数量数据点的区间。每个区间(或“箱”)包含的数据点数量是大致相同的。
- 基本语法:
pd.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')x: 要进行分箱的 Series 或一维数组。q: 指定分箱的数量或分位点。- 整数
N:将数据划分为N个等频的区间(四分位数为q=4)。 - 序列(列表或 NumPy 数组):指定自定义的分位点(例如
[0, 0.25, 0.5, 0.75, 1])。
- 整数
labels: 列表或布尔值,用于指定分箱后每个区间的标签。retbins: 布尔值,如果为True,则返回分箱的实际边界。duplicates: 字符串,当分位点有重复值时如何处理。'raise'(默认):如果分位点有重复值,则引发错误。'drop':如果分位点有重复值,则丢弃重复的分位点。
pd.qcut()的原理是首先计算数据的分位数,然后根据这些分位数作为边界来创建箱。例如,如果q=4,它会计算 25%、50% 和 75% 的分位数,然后用这些分位数作为边界来划分数据。
- 优点: 确保每个箱中都有大致相等数量的数据点,这对于处理偏斜数据或需要平衡每个类别大小的场景非常有用。
- 缺点: 区间的宽度可能不相等,这使得解释性不如等宽分箱直观。
duplicates='drop': 当数据中存在大量重复值时,可能会导致某些分位点重合。此时,duplicates='drop' 参数可以避免错误,它会删除重复的分位点,从而可能导致实际的箱数少于 q。
结合 value_counts(): 分箱后,通常会结合 value_counts() 来检查每个箱中数据点的实际数量,以验证分箱是否达到预期效果。
1
2
3
display(df)
df1 = pd.qcut(df.python, q = 4, labels=["差", "中", "良", "优"])
display(df1, df1.value_counts())

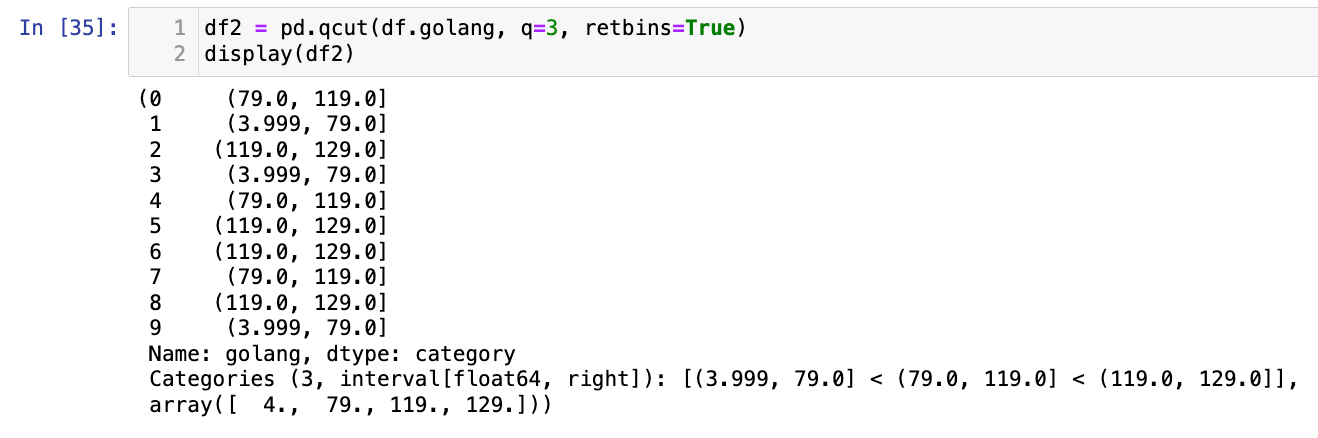
也可以返回分箱的边界:
1
2
df2 = pd.qcut(df.golang, q=3, retbins=True)
display(df2)
选择题
-
给定
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]),执行pd.qcut(s, q=2, labels=['Low', 'High'])后,'Low'类别中包含哪些值?A.
[1, 2, 3, 4, 5]B.
[1, 2, 3, 4]C.
[1, 2, 3, 4, 5, 6]D.
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]答案:A
-
以下哪个方法在分箱时会确保每个箱中包含大致相等数量的数据点?
A.
pd.cut()B.pd.qcut()C.df.groupby()D.df.bins()答案:B
编程题
- 创建一个 Series
income,包含 50 个随机整数,范围在 20000 到 100000 之间。 - 使用
pd.qcut()将income分箱为 5 个等频的区间,并为每个区间指定标签:'Very Low','Low','Medium','High','Very High'。 - 打印分箱后的 Series 及其每个类别的计数。
- 使用
pd.qcut()将income分箱为基于自定义分位点[0, 0.1, 0.5, 0.9, 1]的区间,并打印分箱结果和实际的分箱边界。
1
2
3
4
5
6
7
8
9
10
data = np.random.randint(20000, 100000, (50, ))
income = pd.Series(data=data)
display(income)
# 使用 pd.qcut() 将 income 分箱为 5 个等频的区间,
# 并为每个区间指定标签:'Very Low', 'Low', 'Medium', 'High', 'Very High'。
s1 = pd.qcut(income, q=5, labels=["Very Low", "Low", "Medium", "High", "Very High"])
display(s1, s1.value_counts())
# 使用 pd.qcut() 将 income 分箱为基于自定义分位点 [0, 0.1, 0.5, 0.9, 1] 的区间,并打印分箱结果和实际的分箱边界
s2 = pd.qcut(income, q=[0, 0.1, 0.5, 0.9], retbins=True)
display(s2)