在数据分析和机器学习的工作流程中,数据转换和重塑是至关重要的步骤。它们允许我们以不同的方式组织和修改数据,以适应特定的分析需求或模型输入格式。pandas 库提供了丰富而强大的功能来高效地完成这些任务。
1.数据转换
数据转换是指对数据进行修改,使其从一种形式变为另一种形式,通常是为了清洗、标准化或创建新特征。
1.1 轴和元素替换
在数据处理过程中,我们经常需要修改 DataFrame 的索引标签或替换数据中的特定值。pandas 提供了 rename() 方法用于重命名轴标签,以及 replace() 方法用于替换数据值。
- 重命名轴索引 (
df.rename(mapper=None, index=None, columns=None, axis=None, inplace=False))mapper: 一个字典或函数,用于指定旧标签到新标签的映射。index: 字典或函数,用于重命名行索引。columns: 字典或函数,用于重命名列索引。axis: 可选参数,指定要重命名的轴(0或'index'用于行,1或'columns'用于列)。如果同时提供了index和columns参数,则无需指定axis。inplace: 布尔值,如果为True,则直接修改原始 DataFrame;如果为False(默认),则返回一个新的 DataFrame。
- 替换值 (
df.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad'))to_replace: 要被替换的值,可以是单个值、列表、字典、正则表达式或 Series。value: 替换后的值,可以是单个值、列表、字典或 Series。- 如果
to_replace是单个值、列表或 Series,value可以是单个值或与to_replace长度相同的列表。 - 如果
to_replace是字典,则字典的键是被替换的值,值是替换后的值。这允许进行多对多的替换。
- 如果
inplace: 布尔值,是否直接修改原始 DataFrame。regex: 布尔值,如果为True,则to_replace可以是正则表达式。
rename()的原理:rename()方法实际上是在不改变底层数据的情况下,创建了一个新的索引对象。如果inplace=False,它会创建一个新的 DataFrame,并将旧索引替换为新索引。如果inplace=True,它会直接修改 DataFrame 对象的索引属性。这个操作通常非常高效,因为它只涉及元数据的修改,而不涉及大量数据的复制。
replace()的原理:replace()方法的实现更为复杂,因为它涉及到遍历数据并根据条件进行替换。
- 当替换单个值或列表时,
pandas会在底层对数据进行逐元素比较和替换。- 当使用字典进行替换时,
pandas会构建一个查找表,然后遍历数据,如果元素在查找表中,则进行替换。replace()总是返回一个新的 DataFrame(除非inplace=True),因为数据内容发生了变化。
拓展:rename() 和 replace() 的使用场景
rename()拓展:- 统一命名规范: 将不规范的列名(例如,包含空格或特殊字符)重命名为符合 Python 变量命名规范的名称。
- 多语言支持: 将英文列名翻译成中文列名,方便本地化分析。
- 函数映射重命名: 当重命名规则比较复杂时,可以传入一个函数,例如将所有列名转换为小写:
df.rename(columns=str.lower)。
replace()拓展:- 处理缺失值: 将特定的错误值(例如,
-999)替换为np.nan,以便后续进行缺失值处理。 - 数据标准化: 将分类变量的文本值替换为数值编码(例如,
'Male'替换为0,'Female'替换为1)。 - 模糊匹配替换: 结合
regex=True参数,可以根据正则表达式替换匹配的字符串。例如,df['text_col'].replace(r'[^a-zA-Z\s]', '', regex=True)可以移除文本中的所有非字母和非空格字符。
- 处理缺失值: 将特定的错误值(例如,
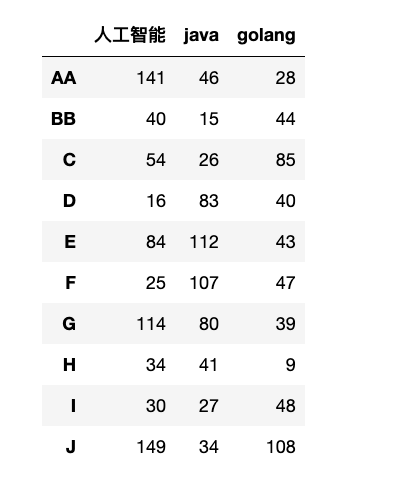
【1】重命名轴索引:
1
2
df_rename = df.rename(index={"A":"AA", "B":"BB"}, columns={"python": "人工智能"} )
display(df_rename)
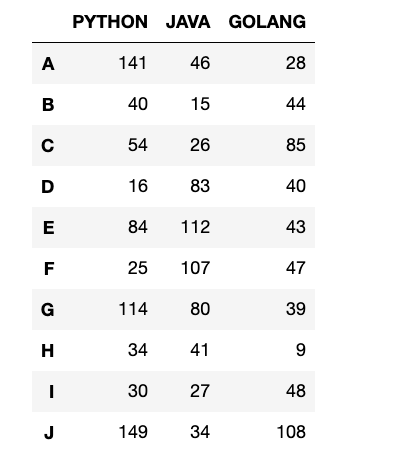
【2】使用函数重命名列
比如:将所有的列名转换为大写:
1
2
df_upper = df.rename(columns=str.upper)
display(df_upper)
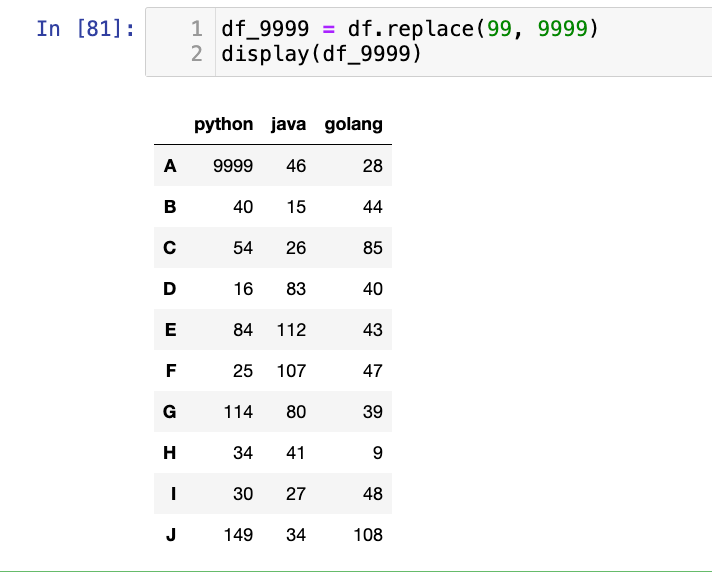
【3】单个值替换为其他值:
无论有几个99,都把99变成9999
1
2
df_9999 = df.replace(99, 9999)
display(df_9999)
1
2
df_2048 = df.replace([99, 8888], 7777)
display(df_2048)
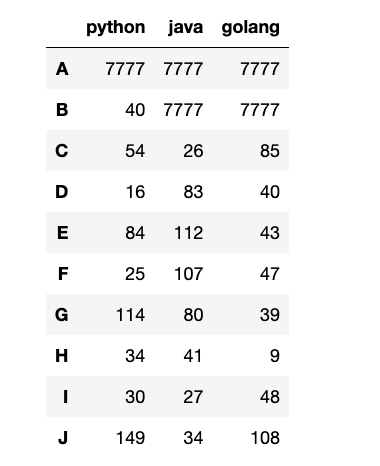
1
2
df_mul = df.replace({99: np.nan, 8888: 6666})
display(df_mul)
注意:下面这个写法也可以:
df.replace([0, 1], [np.nan, 100]): 使用两个列表,分别指定要替换的值和替换后的值,0 替换为np.nan,1 替换为 100
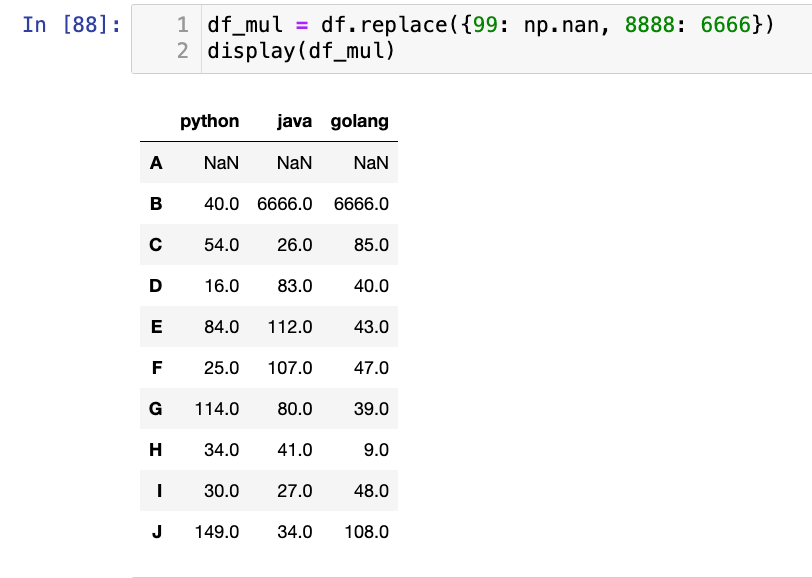
1
2
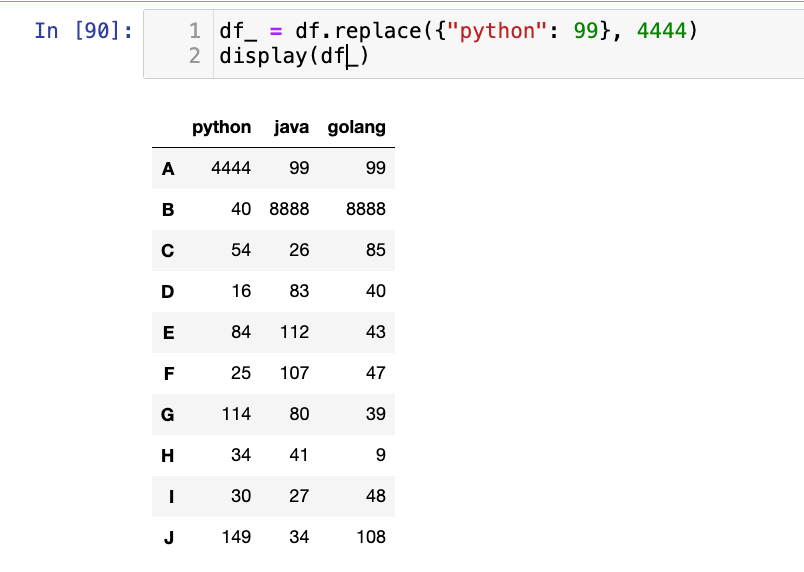
df_ = df.replace({"python": 99}, 4444)
display(df_)
【4】使用正则表达式替换:
1
2
3
4
5
6
7
data = {"text": ["Hello world", "Python is great", "123 Test"]}
df_text = pd.DataFrame(data=data)
display(df_text)
# 移除数字和特殊字符
# [^a-zA-Z\s]:除了字母和空白字符之外的任意单个字符
res = df_text.replace(r"[^a-zA-Z\s]", '', regex=True)
display(res)

选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),执行df.rename(columns={'A': 'Col_A'}, inplace=True)后,df.columns的结果是什么?A.
Index(['A', 'B'], dtype='object')B.
Index(['Col_A', 'B'], dtype='object')C.
Index(['Col_A', 'Col_B'], dtype='object')D. 报错
答案:B
-
要将 DataFrame 中所有值为
0的元素替换为np.nan,并同时将所有值为1的元素替换为100,以下哪个replace()调用是正确的?A.
df.replace(0, np.nan).replace(1, 100)B.
df.replace({0: np.nan, 1: 100})C.
df.replace([0, 1], [np.nan, 100])D. B 和 C 都是正确的。
答案:D
编程题
- 创建一个 DataFrame
exam_results,包含'Student_ID','Math_Score','English_Score'三列,以及 5 行数据。Student_ID填充[101, 102, 103, 104, 105]。Math_Score和English_Score填充随机整数,其中Math_Score的103号学生分数为0,English_Score的105号学生分数为np.nan。
- 使用
rename()方法将'Math_Score'列重命名为'数学成绩',将'English_Score'列重命名为'英语成绩'。 - 使用
replace()方法将所有0分替换为60分,并将所有np.nan替换为50分。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
stu_id = np.arange(101, 106)
s1 = np.random.randint(0, 151, (5, ))
s2 = np.random.randint(0, 151, (5, ))
data = {"Student_ID": stu_id, "Math_Score": s1, "English_Score": s2}
exam_results = pd.DataFrame(data=data)
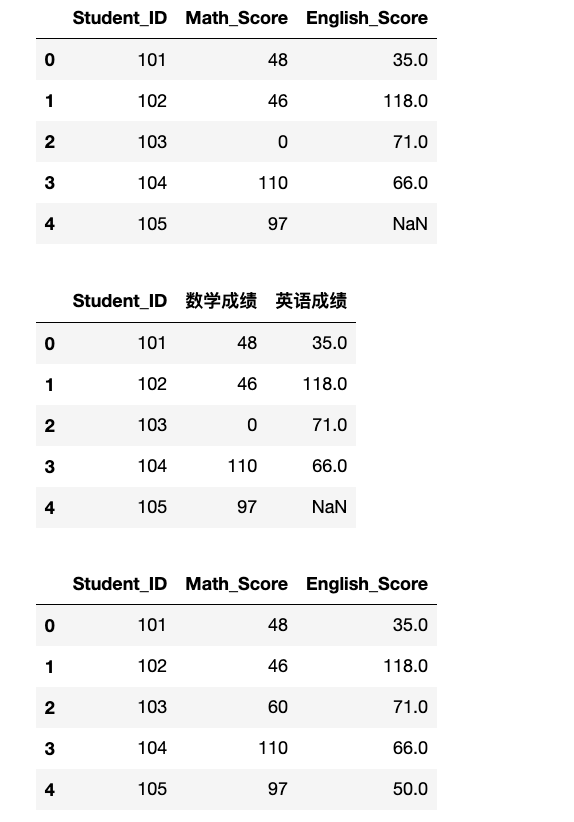
# Math_Score 的 103 号学生分数为 0,English_Score 的 105 号学生分数为 np.nan。
exam_results.loc[exam_results["Student_ID"] == 103, "Math_Score"] = 0
exam_results.loc[exam_results["Student_ID"] == 105, "English_Score"] = np.nan
display(exam_results)
# 使用 rename() 方法将 'Math_Score' 列重命名为 '数学成绩',将 'English_Score' 列重命名为 '英语成绩'。
exam_results_rename = exam_results.rename(columns={"Math_Score": "数学成绩", "English_Score": "英语成绩"})
display(exam_results_rename)
# 使用 replace() 方法将所有 0 分替换为 60 分,并将所有 np.nan 替换为 50 分。
exam_results_rep = exam_results.replace({0: 60, np.nan: 50})
display(exam_results_rep)
1.2 map Series元素改变
Series.map() 方法是 Series 独有的,用于对 Series 中的每个元素应用一个映射函数或字典。它非常适合进行一对一的元素转换。
- 基本语法:
Series.map(arg, na_action=None)arg: 可以是一个字典(用于值替换)、一个 Series(用于基于索引的对齐和替换)或一个函数(用于对每个元素进行转换)。na_action: 字符串,如果设置为'ignore',则在映射过程中跳过NaN值,否则NaN值也会被映射(如果arg是字典且NaN不在字典中,则结果仍为NaN)
Series.map()的核心原理是逐元素应用和索引对齐(如果arg是 Series)。
- 字典映射: 当
arg是字典时,map()会遍历 Series 中的每个值。如果该值作为键存在于字典中,则将其替换为字典中对应的值;如果不存在,则替换为NaN。- 函数映射: 当
arg是函数时,map()会将 Series 中的每个元素作为参数传递给该函数,并将函数的返回值作为新 Series 中对应位置的值。- Series 映射: 当
arg是另一个 Series 时,map()会根据调用 Series 的值与argSeries 的索引进行匹配。如果调用 Series 的某个值与argSeries 的索引匹配,则使用argSeries 中对应索引的值进行替换。
map()总是返回一个新的 Series,因为它创建了一个转换后的数据副本。
拓展:map() 的使用场景
- 分类变量编码: 将文本分类变量映射为数值编码。例如,将
'Male'映射为0,'Female'映射为1。 - 数据清洗: 将特定编码(如错误代码)映射为更具可读性的描述。
- 数据转换: 对数值数据应用数学函数(如取对数、平方根),或者根据条件进行转换(如将分数转换为等级)。
- 基于字典的批量查找: 当需要根据 Series 中的值去查找另一个字典中的信息时,
map()比循环更高效。
【1】字典映射,不改变原先的df
1
2
3
4
5
6
7
data = np.random.randint(0, 151, (10, 3))
df=pd.DataFrame(data=data, columns=["python", "java", "golang"], index=list("ABCDEFGHIJ"))
df.iloc[4, 2] = np.nan
display(df)
golang_map = df["golang"].map({128:"Hello", 108:"world", 124: "AI"})
display(golang_map) # 其他值变为NaN

【2】隐式函数映射(lambda函数)
1
2
3
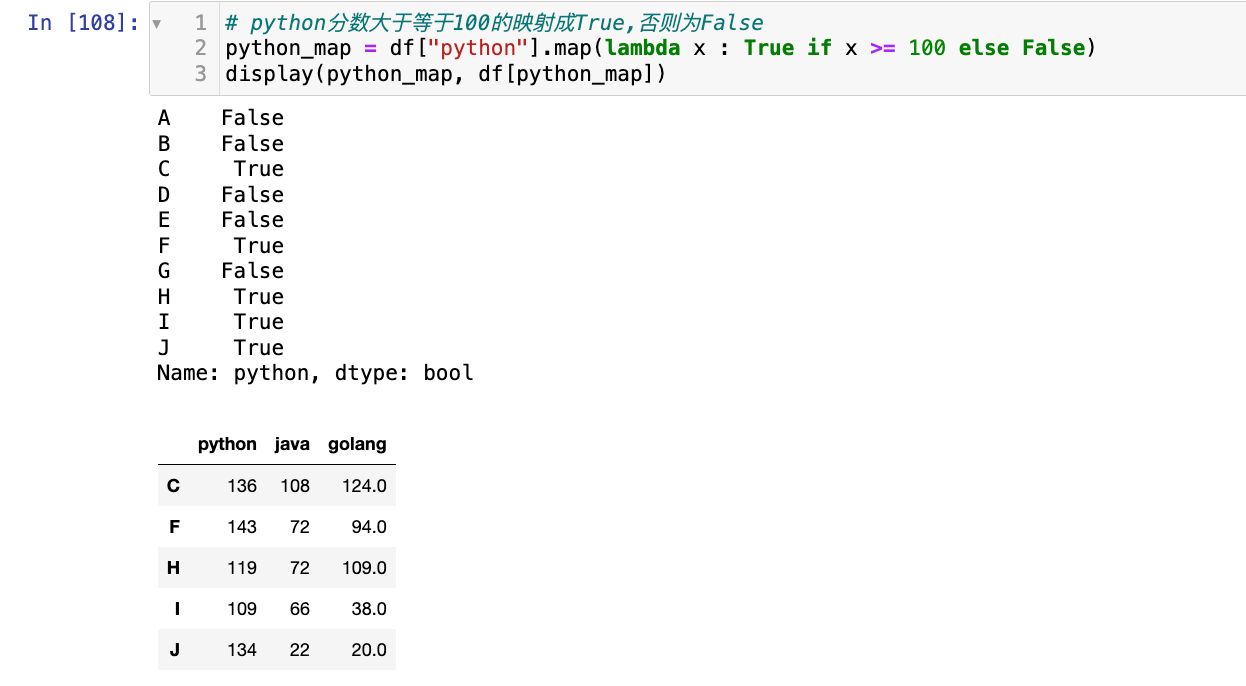
# python分数大于等于100的映射成True,否则为False
python_map = df["python"].map(lambda x : True if x >= 100 else False)
display(python_map, df[python_map])
【3】显式函数映射:
1
2
3
4
5
6
7
8
9
10
11
12
13
def convert_java(x):
# 处理NaN
if pd.isna(x):
return np.nan
if x % 3 == 0:
return "能被3整除"
elif x % 3 == 1:
return "余1"
else:
return "余2"
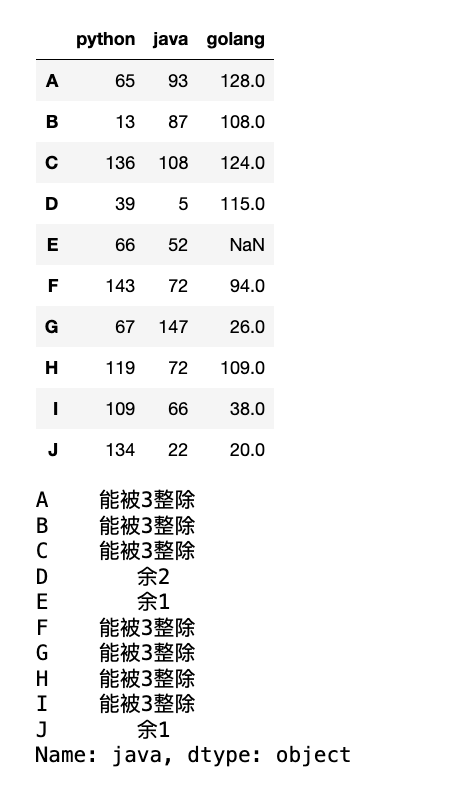
java_map = df.java.map(convert_java)
display(df, java_map)
【4】使用Series进行映射:(基于索引对齐)
1
2
3
4
df.python = np.random.randint(0, 10, (10, ))
s = pd.Series(index=[9, 8, 7, 6, 5], data=["A", "B", "C", "D", "E"])
display(s, df)
df.python.map(s)

选择题
-
给定
s = pd.Series([1, 2, 3]),执行s.map({1: 'one', 2: 'two'})后,s的结果是什么?A.
Series([1, 2, 3])B.
Series(['one', 'two', 3])C.
Series(['one', 'two', np.nan])D. 报错
答案:C, map 对未匹配的值返回 NaN
-
以下关于
Series.map()的说法,哪一项是错误的?A. 它可以接受字典作为映射参数。
B. 它可以接受函数作为映射参数。
C. 它可以直接修改原始 Series。
D. 它可以用于将 Series 中的值映射到新的值。
答案:C,
Series.map()返回一个新的 Series,不会修改原始 Series(除非将结果赋值回原 Series,例如s = s.map(...))。
编程题
- 创建一个 Series
product_status,包含'in_stock','out_of_stock','pre_order','in_stock'等字符串。 - 使用
map()方法将这些字符串状态映射为数值编码:'in_stock'映射为1'out_of_stock'映射为0'pre_order'映射为2
- 创建一个 Series
temperatures,包含一些浮点数温度值。使用map()方法将温度值转换为其对应的摄氏度(假设原始是华氏度,公式 \(C=(F−32)*5/9\))。 - 打印每一步操作后的 Series。
1
2
3
4
5
6
7
8
9
10
11
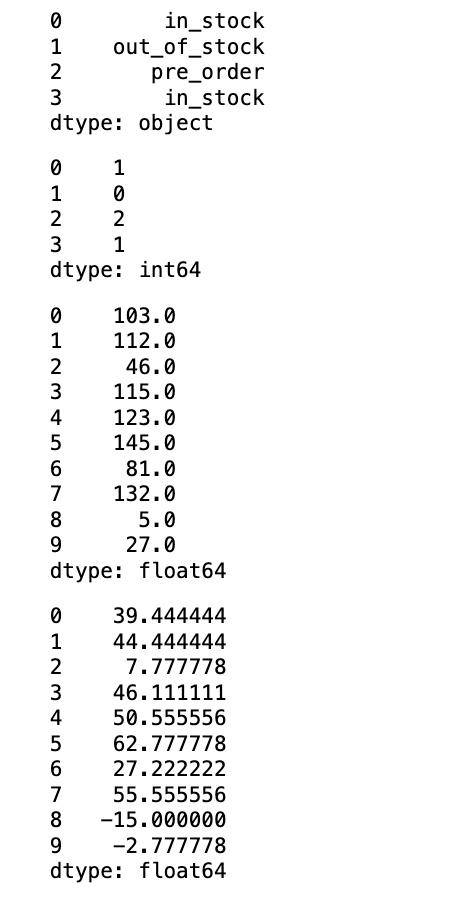
product_status = pd.Series(["in_stock", "out_of_stock", "pre_order", "in_stock"])
display(product_status)
# 映射为数值编码
res_pro_status = product_status.map({"in_stock": 1, "out_of_stock": 0, "pre_order": 2})
display(res_pro_status)
temperature = pd.Series(np.random.randint(0, 151, (10, )))
temperature = temperature.astype(float)
display(temperature)
res_t = temperature.map(lambda x: (x - 32) * 5 / 9)
display(res_t)
1.3 apply 元素改变
apply() 方法是 pandas 中一个非常通用的函数,它既支持 Series 也支持 DataFrame。它允许您将一个函数应用到 Series 的每个元素,或 DataFrame 的每一行/每一列。
- Series 上的
apply():- 行为与
Series.map()类似,都是逐元素应用函数。 Series.apply(func, args=(), **kwargs)func: 要应用的函数,它将接收 Series 中的每个元素作为输入。
- 行为与
- DataFrame 上的
apply():- 这是
apply()最强大的用法之一。它允许您将函数应用到 DataFrame 的每一行或每一列。 DataFrame.apply(func, axis=0, args=(), **kwargs)func: 要应用的函数。- 如果
axis=0(默认,按列应用),func将接收 DataFrame 的每一列(一个 Series)作为输入。 - 如果
axis=1(按行应用),func将接收 DataFrame 的每一行(一个 Series)作为输入。
- 如果
axis: 指定应用函数的轴。- 函数的返回值可以是标量、Series 或 DataFrame。
- 这是
applymap()DataFrame 专有DataFrame.applymap(func):这是一个 DataFrame 独有的方法,用于将函数逐元素地应用到 DataFrame 的所有元素上。- 它类似于 Series 上的
map(),但作用于整个 DataFrame。
apply()的原理:apply()方法在底层会迭代 Series 的每个元素或 DataFrame 的每一行/每一列,并将它们作为 Series 对象传递给用户定义的函数。虽然它比纯 Python 循环更高效,但它仍然在 Python 层面进行迭代,因此在处理非常大的数据集时,如果操作可以通过矢量化(如 NumPy 函数或 UFuncs)完成,那么矢量化操作通常会更快。applymap()的原理:applymap()则是对 DataFrame 中的每个单独的标量元素进行操作。它在底层会遍历 DataFrame 的所有单元格,并将每个单元格的值传递给函数。它比apply(axis=0/1)更底层,因为它不处理 Series 对象,而是直接处理标量。这些方法通常返回一个新的 Series 或 DataFrame,因为它们创建了转换后的数据副本。
拓展:apply() 和 applymap() 的使用场景
apply()拓展:- 行/列聚合计算: 计算每行或每列的复杂统计量(例如,中位数、众数、自定义加权平均)。
- 条件转换: 根据行或列的整体属性进行复杂的数据转换。
- 特征工程: 从多列数据中生成新的特征。例如,计算每行的总分,或根据多列的组合判断一个状态。
- 文本处理: 对包含文本的列应用自定义的文本清洗函数。
applymap()拓展:- 数值转换: 对 DataFrame 中所有数值元素进行统一的数学变换(如取对数、加常数)。
- 格式化输出: 将 DataFrame 中的所有数值格式化为字符串(例如,保留两位小数)。
- 条件着色: 在 Jupyter Notebook 中,可以结合
style.applymap对 DataFrame 的每个单元格进行条件着色。
【1】Series应用apply函数:
1
2
3
4
5
6
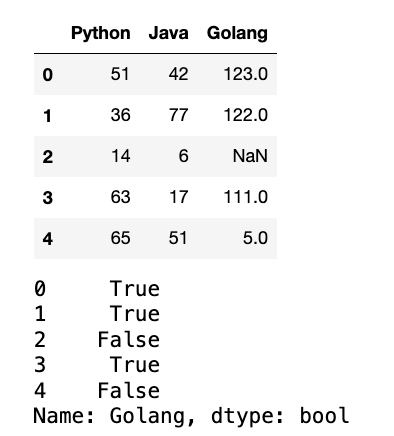
data = np.random.randint(0, 151, (5, 3))
df = pd.DataFrame(data = data, columns=["Python", "Java", "Golang"])
df.iloc[2, 2] = np.nan
display(df)
golang_apply = df.Golang.apply(lambda x :True if x is not None and x > 90 else False)
display(golang_apply)
【2】DataFrame应用apply:
1
2
3
4
display(df)
# 计算每一列的中位数
median_df = df.apply(lambda x : x.median(), axis = 0)
display(median_df)
也可以自定义方法:
1
2
3
4
5
6
7
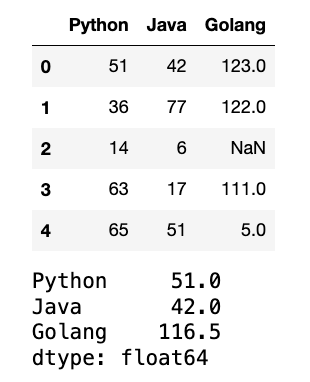
8
# 求每行均值和非空计数
def analyze_row(row):
mean_val = row.mean()
count_val = row.count()
return pd.Series([mean_val.round(1), count_val], index=["Mean", "Count"])
row_analyze = df.apply(analyze_row, axis=1)
display(row_analyze)
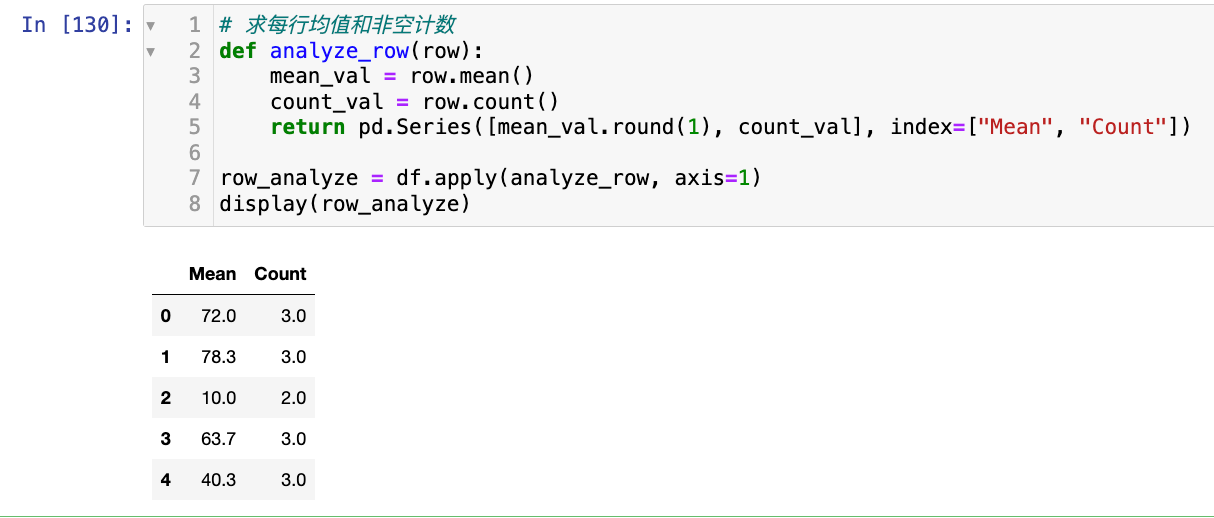
【3】applymap:DataFrame专有的函数:
1
2
3
# df中每个元素做+10的处理(非空)
df_ = df.applymap(lambda x : x + 10 if pd.notna(x) else x)
display(df_)
可以直接用map方法,作用在df上:
1
2
3
# df中每个元素做+10的处理(非空)
df_ = df.map(lambda x : x + 100 if pd.notna(x) else x)
display(df_)
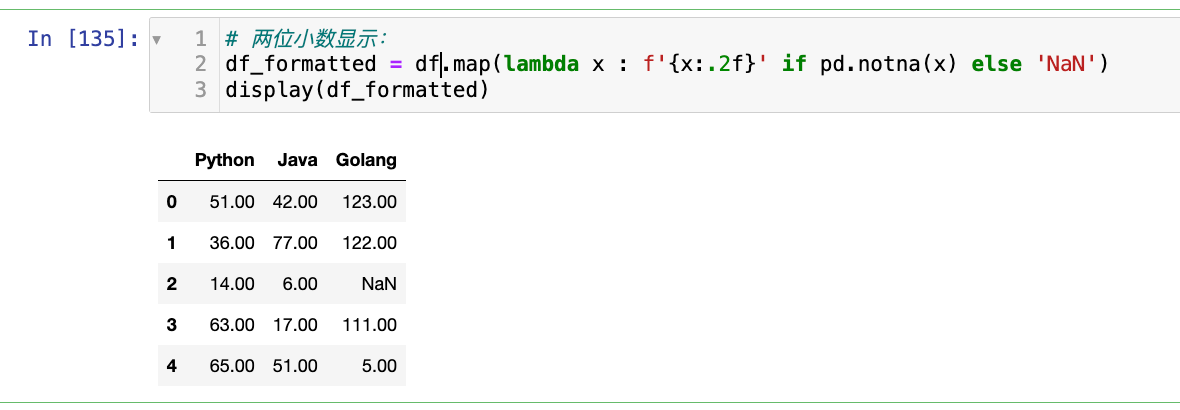
【4】格式化单元格的显示:
1
2
3
# 两位小数显示:
df_formatted = df.map(lambda x : f'{x:.2f}' if pd.notna(x) else 'NaN')
display(df_formatted)
选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),执行df.apply(lambda x: x.sum(), axis=0)的结果是什么?A.
Series([4, 6], index=['A', 'B'])B.
Series([3, 7], index=["A", "B"])C.
DataFrame形状为(2, 2)。D. 报错。
答案:B
-
以下哪个方法是 DataFrame 独有的,用于将函数逐元素地应用到 DataFrame 的所有元素上?
A.
Series.map()B.
DataFrame.apply()C.
DataFrame.applymap()D.
Series.apply()答案:C
编程题
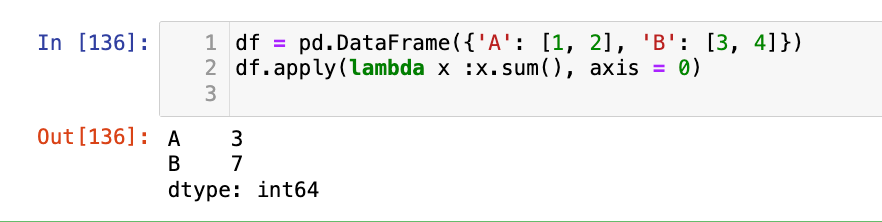
- 创建一个 DataFrame
student_scores,包含'Math','Science','English'三列,以及 5 行随机整数分数。 - 使用
apply()方法计算每名学生的总分(即每行的和),并将结果作为新列'Total_Score'添加到 DataFrame 中。 - 使用
apply()方法计算每门课程的平均分和标准差,并打印结果。 - 使用
applymap()方法将 DataFrame 中所有分数大于 90 的元素替换为'Excellent',否则保持原样。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
data = np.random.randint(0, 151, (5, 3))
df = pd.DataFrame(data=data, columns=["Math", "Science", "English"])
display(df)
# 使用 apply() 方法计算每名学生的总分(即每行的和),并将结果作为新列 'Total_Score' 添加到 DataFrame 中。
df["Total_Score"] = df.apply(lambda x: x.sum(), axis = 1)
display(df)
# 使用 apply() 方法计算每门课程的平均分和标准差,并打印结果
course_info_mean = pd.DataFrame(df.apply(lambda x: x.mean(), axis = 0))
course_info_std = pd.DataFrame(df.apply(lambda x: x.std(), axis = 0))
course_info = pd.merge(course_info_mean, course_info_std, left_index=True, right_index=True)
course_info = course_info.rename({"0_x": "Mean", "0_y": "Std"}, axis=1)
course_info = course_info.loc["Math": "English"]
display(course_info)
# 使用 applymap() 方法将 DataFrame 中所有分数大于 90 的元素替换为 'Excellent',否则保持原样
df_ = df.map(lambda x: "Excellent" if x > 90 else x)
display(df_)
1.4 transform 变形金刚
关于transform 函数可以参考博客:pandas超级重要函数-transform函数
transform() 方法是 pandas 中一个非常强大的数据转换工具,它与 apply() 类似,但有一个关键区别:transform() 返回的 Series 或 DataFrame 的形状必须与原始输入相同。这意味着 transform() 通常用于执行那些对每个组(或整个 Series/DataFrame)进行计算,并将结果广播回原始形状的操作。
- 基本语法:
Series.transform(func, *args, **kwargs)或DataFrame.transform(func, axis=0, *args, **kwargs)func: 要应用的函数。可以是 NumPy UFuncs、Python 函数、函数列表或字典。- 当
func是一个函数时,它将被应用到 Series 或 DataFrame 的每个组(如果使用了groupby)或整个 Series/DataFrame。 - 当
func是一个函数列表时,会对每个函数执行计算,并返回一个 DataFrame,其中每个函数的结果作为一列。 - 当
func是一个字典时,键是列名,值是函数或函数列表,表示对特定列应用特定的转换。
transform()的核心原理是广播(Broadcasting)。当transform()应用一个函数时,它会:
- 执行计算: 对整个 Series/DataFrame 或每个分组执行
func。- 广播结果: 将计算结果(通常是聚合值或转换值)广播回原始 Series/DataFrame 的形状。
例如,如果对一列数据计算均值,
transform(np.mean)会将该均值复制到该列的所有位置。如果对分组数据计算均值,则每个分组的均值会广播回该分组的所有行。这种广播机制使得transform()在进行特征工程(如用组均值填充缺失值、标准化数据)时非常有用。
transform() 的使用场景
- 填充缺失值: 用组的均值/中位数填充缺失值:
df.groupby('category')['value'].transform(lambda x: x.fillna(x.mean()))。 - 特征标准化/归一化: 对每个组的数据进行标准化:
df.groupby('category')['value'].transform(lambda x: (x - x.mean()) / x.std())。 - 创建新特征: 例如,计算每个销售记录占其所在地区总销售额的比例:
df['sales_ratio'] = df.groupby('region')['sales'].transform(lambda x: x / x.sum())。 - 滑动窗口计算: 结合
rolling()方法进行滑动窗口的均值、标准差等计算,并将结果广播回原始形状。
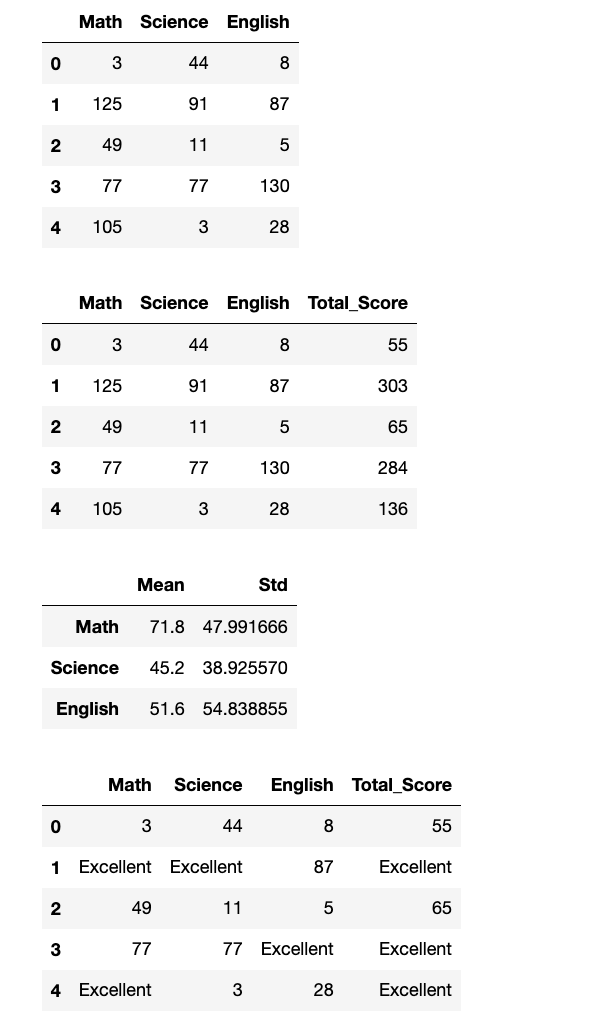
【1】一列执行多个运算:
1
2
3
4
5
6
7
data = np.random.randint(0, 11, (10, 3))
df = pd.DataFrame(data=data, columns=["python", "java", "golang"])
df.iloc[4, 2] = np.nan
display(df)
# 对python列同时执行平方根和指数
res1 = df["python"].transform([np.sqrt, np.exp])
display(res1)
【2】多列执行不同计算:
自定义一个转换函数:
1
2
3
4
5
6
7
8
9
10
11
12
data = np.random.randint(0, 11, (10, 3))
df = pd.DataFrame(data=data, columns=["python", "java", "golang"])
df.iloc[4, 2] = np.nan
def costom_transform(col_series):
if col_series.mean() > 5:
return col_series * 10
else:
return col_series *(-10)
df_trans = df.transform({"python": costom_transform, "java": np.exp, "golang": np.sqrt})
display(df_trans)
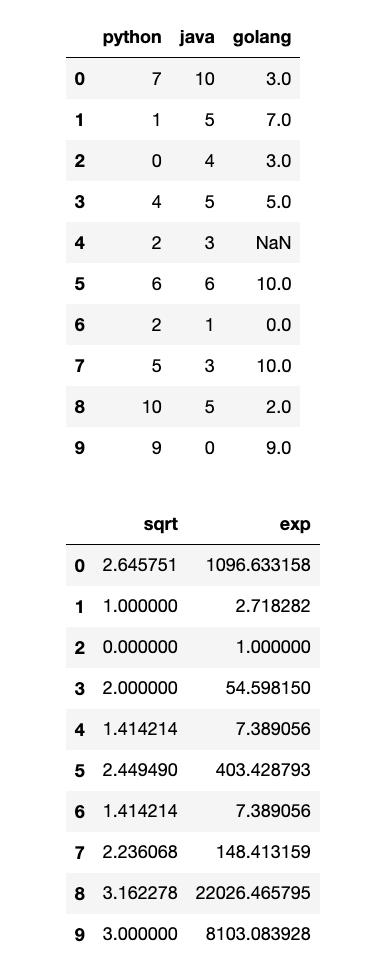
【3】结合groupby使用,非常常用:
1
2
3
4
5
6
7
8
9
data = {"Group": ["A", "A", "B", "B", "A", "B"], "Value": [10, 20, 30, 40, 15, 35]}
df_grouped = pd.DataFrame(data=data)
# 假设有一些缺失值
df_grouped.loc[1, "Value"] = np.nan
df_grouped.loc[4, "Value"] = np.nan
display(df_grouped)
# 用组均值填充缺失值:
df_new = df_grouped.groupby("Group")["Value"].transform(lambda x : x.fillna(x.mean()))
display(df_new)
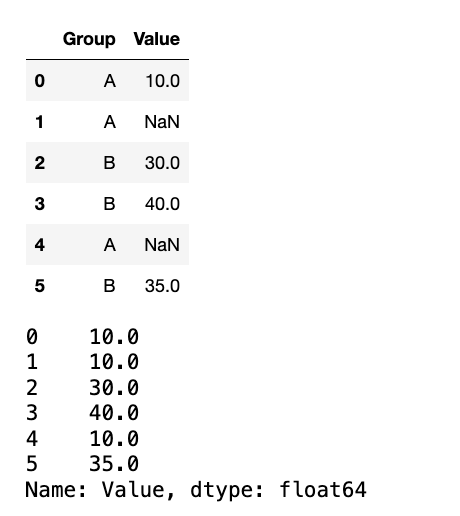
计算每组的Z-Score:
1
2
df_Z_Score = df_grouped.groupby("Group")["Value"].transform(lambda x: (x - x.mean())/ x.std())
display(df_Z_Score)
选择题
-
df.transform()方法返回的 DataFrame 的形状与原始 DataFrame 的形状:A. 总是相同。 B. 总是不同。 C. 取决于应用的函数。 D. 取决于
axis参数。答案:A
-
以下哪个场景最适合使用
df.groupby('category')['value'].transform(lambda x: x.mean())?A. 计算每个类别的总和。
B. 将每个类别中的所有值替换为该类别的均值。
C. 计算整个 DataFrame 的均值。
D. 删除每个类别中的异常值。
答案:B
编程题
-
创建一个 DataFrame
sales_data,包含'Region','Product','Price'三列,以及 8 行数据。-
Region包含'East','West'。 -
Product包含'A','B','C'。 -
Price填充随机整数。 -
参考的data:
1 2 3 4 5
data = { 'Region': np.random.choice(['East', 'West'], size=8), 'Product': np.random.choice(['A', 'B', 'C'], size=8), 'Price': np.random.randint(10, 101, size=8) }
-
-
使用
transform()方法计算每个区域的平均价格,并将该平均价格广播回原始 DataFrame 的'Avg_Region_Price'列。 -
使用
transform()方法对'Price'列应用多个转换:计算其平方根和自然对数,并将结果作为新的 DataFrame 打印。 -
假设
'Price'列有缺失值。使用transform()方法,用每个区域的'Price'中位数来填充该区域的缺失值。 -
打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
data = {
'Region': np.random.choice(['East', 'West'], size=8),
'Product': np.random.choice(['A', 'B', 'C'], size=8),
'Price': np.random.randint(10, 101, size=8)
}
sales_data = pd.DataFrame(data=data)
display(sales_data)
# 使用 transform() 方法计算每个区域的平均价格,并将该平均价格广播回原始 DataFrame 的 'Avg_Region_Price' 列。
sales_data["Avg_Region_Price"] = sales_data.groupby("Region")["Price"].transform(lambda x: x.mean())
display(sales_data)
# 使用 transform() 方法对 'Price' 列应用多个转换:计算其平方根和自然对数,并将结果作为新的 DataFrame 打印。
res = sales_data["Price"].transform([np.sqrt, np.exp])
display(res)
# 假设 'Price' 列有缺失值。使用 transform() 方法,用每个区域的 'Price' 中位数来填充该区域的缺失值。
# 设置3个缺失值
sales_data.loc[[2, 5, 6], "Price"] = np.nan
sales_data["Price"] = sales_data.groupby("Region")["Price"].transform(lambda x: x.fillna(x.median()))
display(sales_data)
1.5 重排随机抽样哑变量
本节涵盖了数据转换中几个重要的实用技巧:数据重排、随机抽样和哑变量(独热编码)的创建。
- 数据重排 (
df.take(indices, axis=0))df.take()方法根据提供的整数位置索引来选择行或列。它不是就地操作,而是返回一个副本。indices: 一个整数数组,包含要选择的行或列的索引。这些索引可以是重复的,也可以是乱序的。axis: 指定在哪个轴上进行选择(0或'index'用于行,1或'columns'用于列)。np.random.permutation(n): NumPy 函数,用于生成一个从0到n-1的随机排列数组。这在需要随机打乱 DataFrame 的行时非常有用。
- 随机抽样 (
df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None))df.sample()方法用于从 DataFrame 中随机抽取样本。n: 要抽取的样本数量。frac: 要抽取的样本比例(0 到 1 之间的浮点数)。n和frac只能指定一个。replace: 布尔值,是否允许有放回抽样(即同一个样本可以被抽取多次)。默认为False(无放回抽样)。random_state: 整数或np.random.RandomState对象,用于设置随机种子,确保结果可复现。axis: 指定在哪个轴上抽样(0或'index'用于行,1或'columns'用于列)。
- 哑变量 / 独热编码 (
pd.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False))- 定义: 哑变量(Dummy Variables)或独热编码(One-Hot Encoding)是一种将分类变量转换为数值格式的方法。对于一个有 k 个类别的分类变量,它会被转换为 k 个二进制(0 或 1)列。每个新列代表一个类别,如果原始数据属于该类别,则对应列为 1,否则为 0。
data: 要进行独热编码的 Series 或 DataFrame。prefix: 字符串,为新创建的哑变量列添加前缀。prefix_sep: 字符串,前缀和原始列名之间的分隔符。dummy_na: 布尔值,如果为True,则为NaN值也创建一个哑变量列。columns: 列表,指定要进行独热编码的列名。如果为None,则对所有object或category类型的列进行编码。drop_first: 布尔值,如果为True,则删除第一个哑变量列。这可以避免多重共线性问题(当一个分类变量的所有类别都可以通过其他类别线性组合表示时)。
take()和permutation():take()依赖于 NumPy 的底层索引机制,通过直接从内存中获取指定位置的数据来构建新的 DataFrame。np.random.permutation()则是生成一个随机的整数序列,这个序列用于take()来实现数据的随机重排。
sample():sample()在底层会生成随机的整数索引,然后使用这些索引通过take()或类似的机制来抽取样本。replace参数决定了抽样时是否将已抽取的样本放回池中,这会影响样本的独立性。
get_dummies(): 独热编码的原理是将一个分类特征的每个类别视为一个独立的二元特征。在底层,pandas会遍历原始分类列的唯一值,为每个唯一值创建一个新列,然后遍历原始数据,根据每个元素的值在新列中标记 0 或 1。这个过程通常会增加 DataFrame 的列数。
这些方法的使用场景
- 数据重排:
- 洗牌: 在机器学习中,在训练模型之前对数据集进行洗牌(Shuffle)是常见的操作,以消除数据中的顺序偏差。
- 交叉验证: 创建随机的训练集和测试集。
- 随机抽样:
- 创建训练集/测试集: 从大型数据集中抽取一部分作为训练集,一部分作为测试集。
- A/B 测试: 随机抽取用户进行实验。
- 性能测试: 在大数据集上进行快速原型开发时,可以抽取小样本进行测试。
- 哑变量 / 独热编码:
- 机器学习模型输入: 大多数机器学习模型(如线性回归、支持向量机、神经网络)不能直接处理文本分类变量,需要将其转换为数值格式。独热编码是常用的转换方法。
- 避免序数关系: 当分类变量之间没有内在的顺序关系时(例如,颜色:红、绿、蓝),独热编码比简单的整数编码(例如,红=1,绿=2,蓝=3)更合适,因为它避免了模型错误地推断出类别之间的序数关系。
【1】数据重排:
1
2
3
4
5
6
7
8
9
data = np.random.randint(0, 10, (10, 3))
df = pd.DataFrame(data=data, columns=["python", "java", "golang"], index=list("ABCDEFGHIJ"))
display(df)
# 数据重排
ran_permutation = np.random.permutation(10)
display(ran_permutation) # 随机排列的索引
# 根据随机排列的索引重排df
df_ran = df.take(ran_permutation)
display(df_ran)

一般生成随机排列索引传的参数和原df一致,否则数据重排索引就容易对不上:
1
2
index_ran = np.random.permutation(15)
df.take(index_ran) # IndexError: indices are out-of-bounds
【2】随机抽样
随机抽取5行:
1
df.sample(n=5, random_state=42) # random_state确保可复现,是随机种子

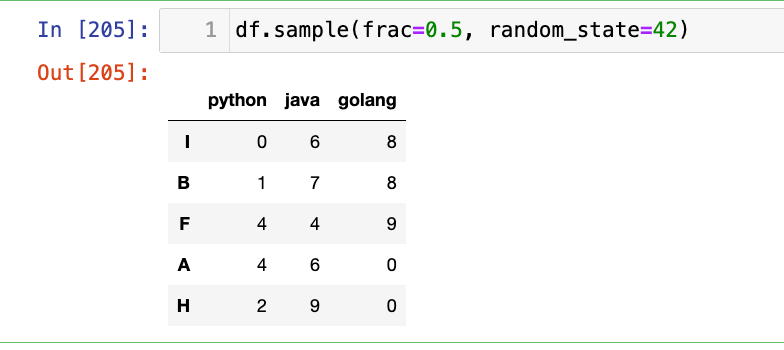
随机抽取50%的数据:
1
df.sample(frac=0.5, random_state=42)
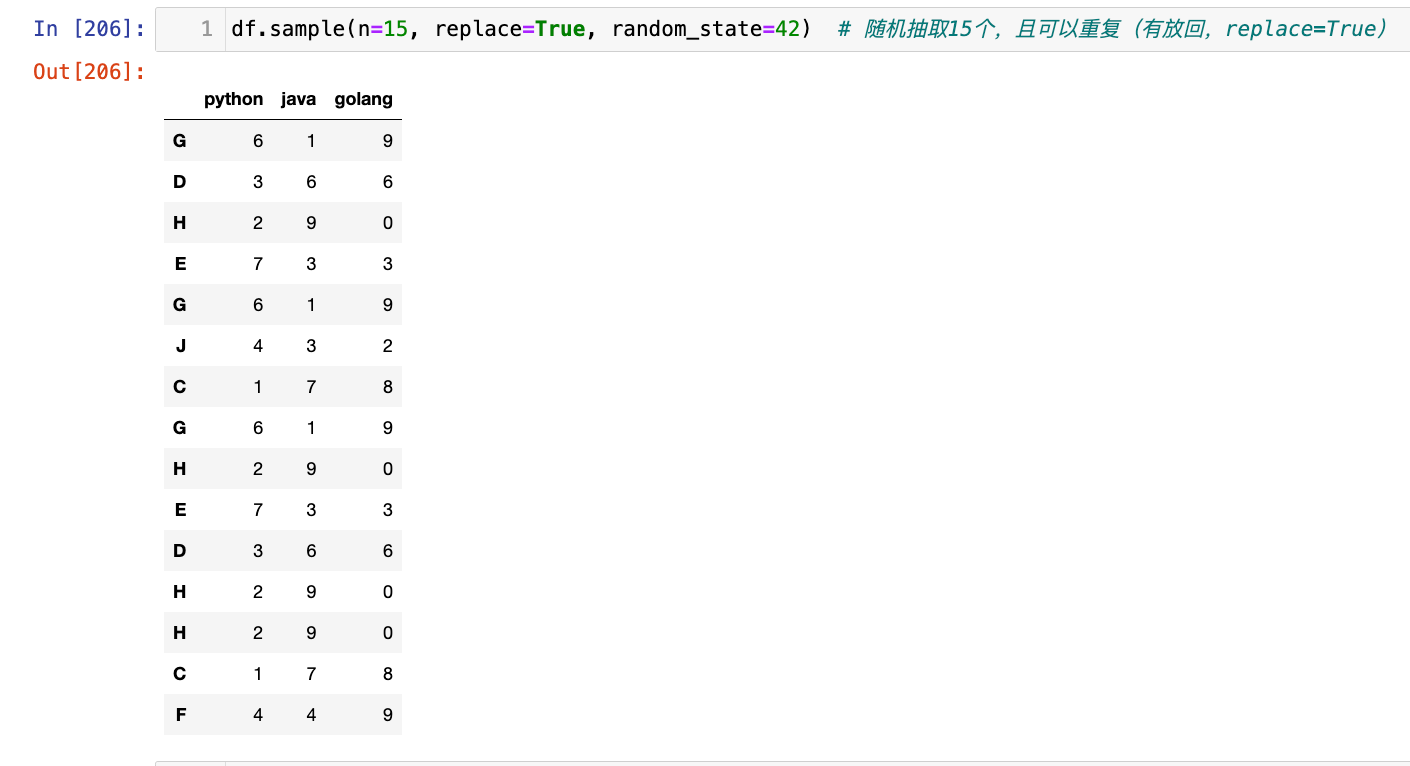
有放回的抽样(replace=True)
1
df.sample(n=15, replace=True, random_state=42) # 随机抽取15个,且可以重复(有放回,replace=True)
【3】哑变量/独热编码
1
2
3
4
5
6
7
8
9
10
11
12
data={
"key": ['b', 'b', 'a', 'c', 'a', 'b'],
"city": ["LA", "NY", "NY", "SF", "LA", "NY"],
"value": [1, 2, 3, 4, 5, 6]
}
df = pd.DataFrame(data=data)
display(df)
# 对key,city进行独热编码
# `prefix`: 字符串,为新创建的哑变量列添加前缀
# `prefix_sep`: 字符串,前缀和原始列名之间的分隔符。
get_dummies_df = pd.get_dummies(df, columns=["key", "city"], prefix=",", prefix_sep="")
display(get_dummies_df)

【4】避免多重共线性:
1
2
3
# 删除第一个哑变量列。这可以避免多重共线性问题(当一个分类变量的所有类别都可以通过其他类别线性组合表示时)。
get_dummies_df_first = pd.get_dummies(df, columns=["key", "city"], drop_first=True)
display(df, get_dummies_df_first)

【5】为NaN值创建哑变量:
1
2
3
4
5
df_na = pd.DataFrame({"category": ["A", "B", "A", np.nan, "C"]})
display(df_na)
with_dum = pd.get_dummies(df_na, dummy_na=True)
no_dum = pd.get_dummies(df_na)
display(with_dum, no_dum)

选择题
-
要从一个 DataFrame
df中随机抽取 10% 的行,以下哪个方法是正确的?A.
df.sample(n=0.1)B.
df.sample(frac=0.1)C.
df.take(np.random.randint(0, len(df), size=int(len(df)*0.1)))D. B 和 C 都是正确的。
答案:D
-
独热编码(One-Hot Encoding)的主要目的是什么?
A. 减少数据集的维度。
B. 将数值型数据转换为分类数据。
C. 将分类变量转换为数值格式,以便机器学习模型处理。
D. 处理缺失值。
C
编程题
- 创建一个 DataFrame
customer_data,包含'CustomerID','Gender','City'三列,以及 8 行数据。Gender包含'Male','Female'。City包含'NY','LA','SF','NY','LA','SF','NY','LA'。
- 对
customer_data进行随机重排。 - 从
customer_data中随机抽取 3 行,要求有放回抽样。 - 对
Gender和City列进行独热编码,并删除第一个哑变量列。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
data = {
"CustomerID": np.arange(0, 8),
"Gender": ["Male", "Female", "Female", "Male", "Male", "Female", "Male", "Female"],
"City": ["NY", "LA", "SF", "NY", "LA", "SF", "NY", "LA"]
}
customer_data = pd.DataFrame(data=data)
display(customer_data)
# 对 customer_data 进行随机重排。
indices = np.random.permutation(8)
df_take = customer_data.take(indices)
display(df_take)
# 从 customer_data 中随机抽取 3 行,要求有放回抽样。
customer_data_sample = customer_data.sample(n=3, replace=True)
display(customer_data_sample)
# 对 Gender 和 City 列进行独热编码,并删除第一个哑变量列。
dum = pd.get_dummies(customer_data, columns=["Gender", "City"], drop_first=True)
display(dum)

2.数据重塑
数据重塑(Reshaping)是指改变 DataFrame 的结构,通常是从“宽格式”转换为“长格式”,或从“长格式”转换为“宽格式”,以及处理多层索引。
2.1转置 (T)
转置是数据重塑中最简单的操作之一,它将 DataFrame 的行和列互换。
- 基本语法:
df.T- 返回一个 DataFrame,其行是原始 DataFrame 的列,其列是原始 DataFrame 的行。
- 原始 DataFrame 的列索引将成为新 DataFrame 的行索引。
- 原始 DataFrame 的行索引将成为新 DataFrame 的列索引。
df.T操作与 NumPy 数组的转置类似,通常不复制数据,而是返回原始 DataFrame 的一个视图。它通过改变 DataFrame 内部的元数据(如shape和strides)来实现,使得数据在逻辑上被“旋转”了。这意味着对转置后的 DataFrame 进行修改会影响到原始 DataFrame。
拓展:转置的使用场景
- 数据可视化: 有时,为了更好地绘制图表(例如,将时间序列作为 X 轴,不同指标作为 Y 轴),需要将数据进行转置。
- 模型输入: 某些机器学习模型可能要求输入数据的特征在行或列中,转置可以帮助调整数据格式。
- 方便的数据检查: 当 DataFrame 有很多列但只有几行时,转置可以使其更易于在控制台查看。
选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),执行df.T后,df.T.iloc[0, 1]的值是什么?A.
1B.2C.3D.4答案:B
2.2 堆叠/非堆叠 (stack / unstack)
stack() 和 unstack() 是 pandas 中处理多层索引(MultiIndex)和在“长格式”与“宽格式”之间转换数据的强大工具。
Series.unstack(level=-1, fill_value=None):- 将 Series 的最内层行索引(或指定
level的索引)旋转(pivot)为新的列。 - 如果 Series 是多层索引,
unstack()会将指定level的索引从行索引转换为列索引。 level: 整数或级别名称,指定要旋转的索引级别。默认是-1(最内层)。fill_value: 当旋转后出现NaN值时,用于填充的值。- 结果通常是 DataFrame。
- 将 Series 的最内层行索引(或指定
DataFrame.unstack(level=-1, fill_value=None):- 将 DataFrame 的最内层行索引(或指定
level的索引)旋转为新的列。 - 如果 DataFrame 的行索引是多层索引,
unstack()会将指定level的索引从行索引转换为列索引。 - 如果 DataFrame 的列索引是多层索引,
unstack()也可以通过指定level将列索引转换为行索引。 - 结果通常是 DataFrame。
- 将 DataFrame 的最内层行索引(或指定
DataFrame.stack(level=-1, dropna=True):- 将 DataFrame 的最内层列索引(或指定
level的索引)旋转(pivot)为新的行(最内层行索引)。 level: 整数或级别名称,指定要堆叠的列索引级别。默认是-1(最内层)。dropna: 布尔值,如果为True(默认),则删除所有NaN值。- 结果通常是 Series(如果只有一列),或带有 MultiIndex 的 Series。
- 将 DataFrame 的最内层列索引(或指定
stack()和unstack()的核心是索引的层次化操作。它们通过重新排列数据的索引级别来实现形状的转换。
unstack(): 将一个索引级别从行索引移动到列索引。这通常会导致 DataFrame 变得“更宽”(更多列)。如果原始数据中没有对应的组合,就会出现NaN。stack(): 将一个列索引级别移动到行索引。这通常会导致 DataFrame 变得“更长”(更多行)。它将宽格式的数据转换为长格式,这在某些数据分析和可视化库(如seaborn)中更受欢迎。这些操作通常会返回新的 DataFrame 或 Series,因为它们会改变数据的结构和内存布局。
多层索引 (MultiIndex)
在 pandas 中,多层索引允许您在 DataFrame 或 Series 的一个或两个轴上拥有多个索引级别。这在处理具有层次结构的数据时非常有用,例如时间序列数据(年-月-日)、实验数据(实验组-处理-重复)等。
- 创建 MultiIndex:
pd.MultiIndex.from_product([list1, list2, ...])是创建 MultiIndex 的常用方法,它会生成所有可能的组合。 - 多层索引的访问: 可以使用元组来访问多层索引的特定级别。例如,
df.loc[('A', '期中')]。
【1】最内层行索引变成列:
1
2
3
4
5
6
data = np.random.randint(0, 100, (20, 3))
index = pd.MultiIndex.from_product([list("ABCDEFGHIJ"), ["期中", "期末"]])
df = pd.DataFrame(data=data, index=index, columns=["java", "python", "golang"])
display(df, df.shape)
df_unstack = df.unstack(level=-1)
display(df_unstack)

【2】最内层列索引旋转成行:
1
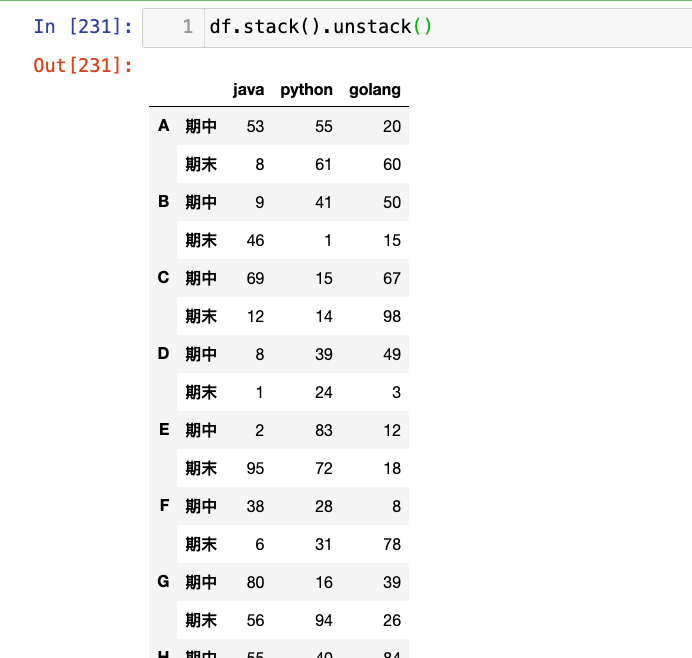
df.stack()

【3】stack().unstack()可以恢复原始形状:
1
df.stack().unstack()
【4】指定level进行stack/unstack
1
2
3
4
5
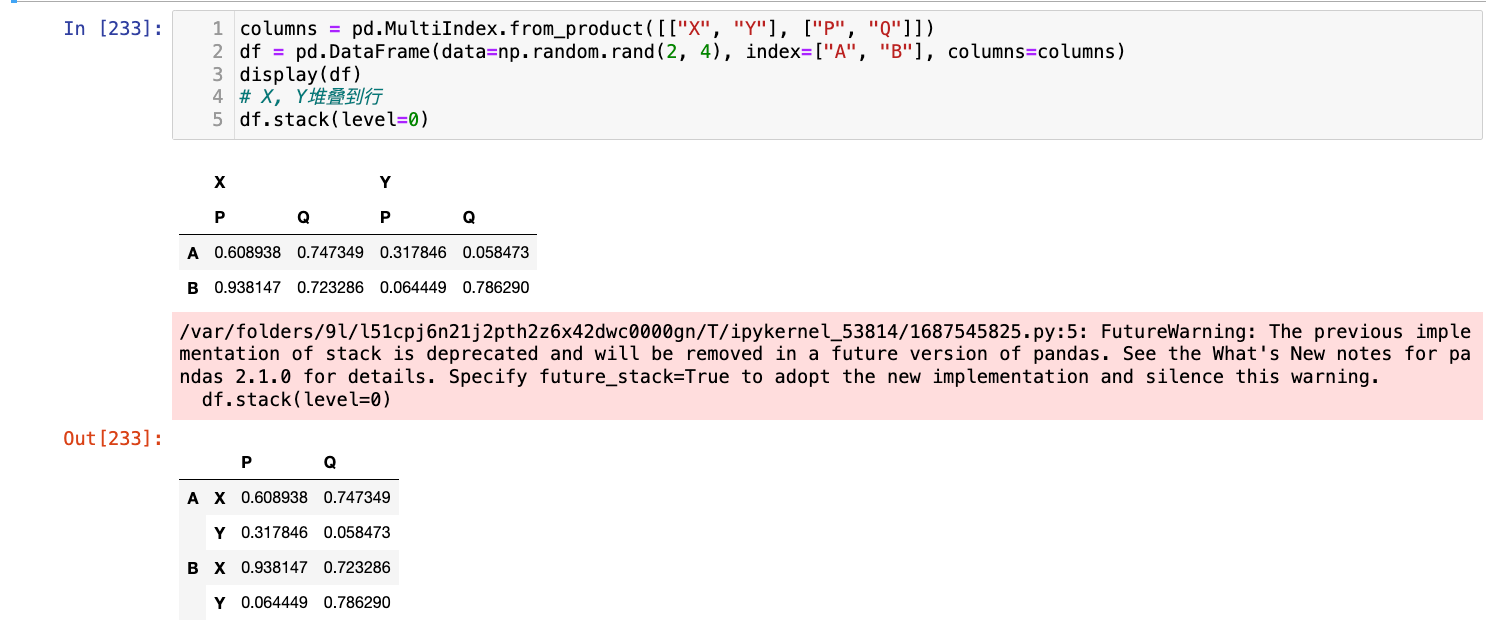
columns = pd.MultiIndex.from_product([["X", "Y"], ["P", "Q"]])
df = pd.DataFrame(data=np.random.rand(2, 4), index=["A", "B"], columns=columns)
display(df)
# X, Y堆叠到行
df.stack(level=0)
选择题
-
给定一个 DataFrame
df_multi,其行索引是pd.MultiIndex.from_product([['A', 'B'], [1, 2]]),列是'Value'。执行df_multi.unstack(level=0)的结果是什么?A. 将行索引
1, 2旋转为列。B. 将行索引
A, B旋转为列。C. 将列
'Value'旋转为行。D. 报错。
答案:B
-
df.stack()方法默认将哪个索引级别旋转为行?A. 最外层行索引。 B. 最内层行索引。 C. 最外层列索引。 D. 最内层列索引。
答案:D
编程题
- 创建一个 DataFrame
sales_data_multi,行索引包含两层:'Region'(例如'North','South') 和'Month'(例如'Jan','Feb'),列为'Product_A','Product_B',并填充随机销售额。 - 使用
unstack()方法将'Month'索引从行旋转到列。 - 使用
stack()方法将'Product_A'和'Product_B'列旋转回行索引。 - 打印每一步操作后的 DataFrame 及其形状。
1
2
3
4
5
6
7
8
9
10
11
12
13
columns = ["Product_A", "Product_B"]
region=["North", "South"]
month = ["Jan", "Feb"]
index = pd.MultiIndex.from_product([region, month], names=["Region", "Month"])
data = np.random.randint(100, 1001, size=(4, 2))
df = pd.DataFrame(data=data, index=index, columns=columns)
display(df)
# 使用 unstack() 方法将 'Month' 索引从行旋转到列。
unstack = df.unstack()
display(unstack)
# 使用 stack() 方法将 'Product_A' 和 'Product_B' 列旋转回行索引。
sta = unstack.stack(0)
display(sta)

2.3 多层索引 DataFrame 数学计算
当 DataFrame 具有多层索引时,pandas 的数学和统计函数可以利用这些层次结构进行更细粒度的计算。您可以使用 level 参数来指定在哪个索引级别上执行聚合操作。
- 基本语法:
df.agg_func(level=None, axis=0)agg_func: 任何聚合函数,如mean(),sum(),max(),min(),std(),count()等。level: 整数或级别名称,指定要进行聚合的索引级别。- 如果
level未指定,则聚合将应用于整个 DataFrame(如果axis=None)或沿着非聚合轴的每个完整标签组合。 - 如果指定了
level,则聚合将在该级别上进行,并返回一个包含该级别标签作为索引的 Series 或 DataFrame。
- 如果
当对多层索引 DataFrame 进行聚合并指定
level参数时,pandas会执行以下操作:
- 分组: 在内部,
pandas会根据指定level的所有唯一标签组合对数据进行分组。- 聚合: 对每个分组的数据执行聚合函数。
- 结果构建: 返回一个新的 Series 或 DataFrame,其索引是聚合所依据的
level标签。这类似于
groupby()操作,但通常更简洁,尤其是在只需要对一个或几个级别进行聚合时。
多层索引计算的使用场景
- 分层统计: 计算不同层次的平均值、总和等。例如,计算每个学生在所有科目上的平均分,或每个科目在所有学生中的平均分。
- 数据透视: 结合
unstack()和聚合函数,可以实现复杂的数据透视表。 - 时间序列分析: 对按年、月、日分层的时间序列数据进行聚合。
1
2
3
4
5
6
7
8
9
10
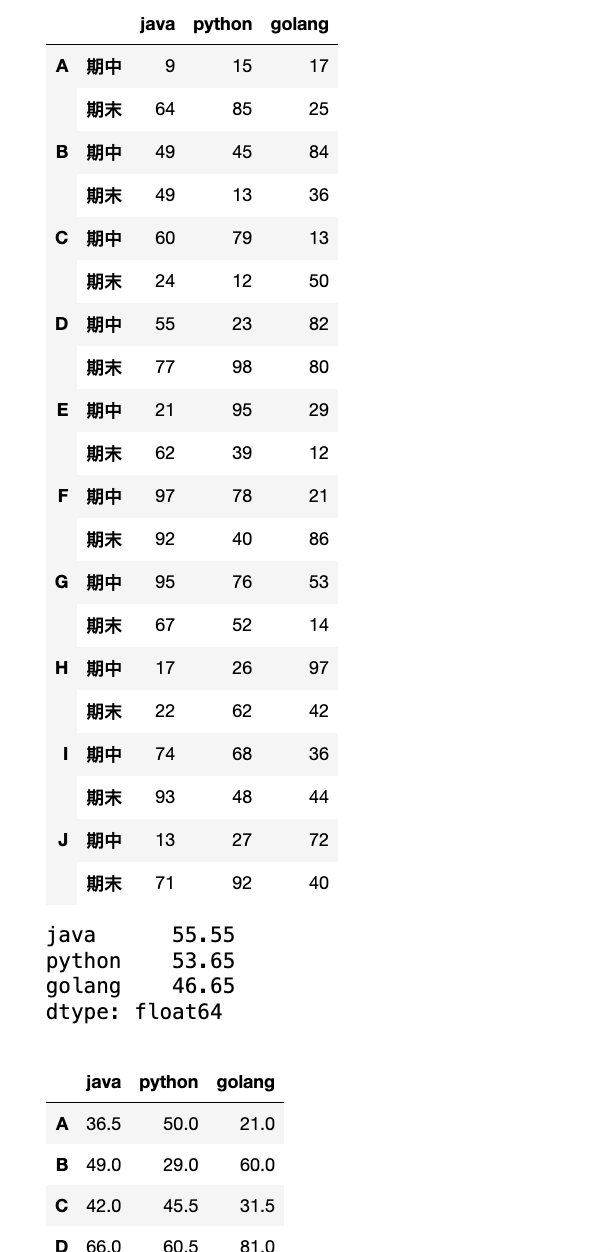
data = np.random.randint(0, 100, (20, 3))
index = pd.MultiIndex.from_product([list("ABCDEFGHIJ"), ["期中", "期末"]])
df = pd.DataFrame(data=data, index=index, columns=["java", "python", "golang"])
display(df)
# 计算各个学科的均分
res = df.mean()
display(res)
# 每个人期中期末均分
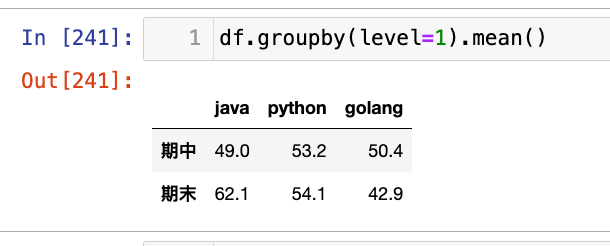
res1 = df.groupby(level=0).mean()
display(res1)
1
df.groupby(level=1).mean()