数据清洗是数据分析流程中非常耗时但至关重要的一步。它涉及处理重复数据、缺失值、异常值以及不一致的数据格式等问题。pandas 提供了丰富的工具来高效地执行这些任务。
1.重复数据过滤
重复数据是指在数据集中出现多次的完全相同或部分相同的记录。处理重复数据是确保数据质量和分析准确性的重要步骤。
df.duplicated(subset=None, keep='first'):- 返回一个布尔 Series,指示每一行是否是重复的。
True表示该行是重复的(之前出现过)。subset: 可选参数,指定要检查重复的列的子集。如果为None,则检查所有列。keep: 指定如何标记重复项。'first'(默认):将第一次出现的重复项标记为False,其余标记为True。'last':将最后一次出现的重复项标记为False,其余标记为True。False:将所有重复项(包括第一次/最后一次出现)都标记为True。
df.drop_duplicates(subset=None, keep='first', inplace=False):- 删除重复的行。
inplace: 布尔值,如果为True,则直接修改原始 DataFrame 并返回None;如果为False(默认),则返回一个新的 DataFrame。- 参数
subset和keep的含义与duplicated()相同。
duplicated()和drop_duplicates()的底层实现通常会使用哈希表来高效地识别重复行。对于每一行,它会计算一个哈希值(或基于subset列的哈希值),并将其存储在哈希表中。当遇到相同的哈希值时,就认为是重复项。keep参数决定了在识别重复项时,哪个副本被认为是“原始”的或“非重复”的。这些操作通常会返回新的 DataFrame(除非
inplace=True),因为删除行会改变 DataFrame 的结构,需要重新构建。
只想根据某些关键列来判断重复时,subset 参数非常有用。例如,在客户数据中,可能允许姓名重复,但如果姓名和邮箱地址都重复,则可能认为是同一个客户的重复记录。
判断是否存在重复数据:
1
2
3
4
5
data = {"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'], 'price': [10, 20, 10, 15, 20, 0, np.nan]}
df = pd.DataFrame(data=data)
display(df)
is_dup = df.duplicated()
print(is_dup)

删除重复数据:
1
2
3
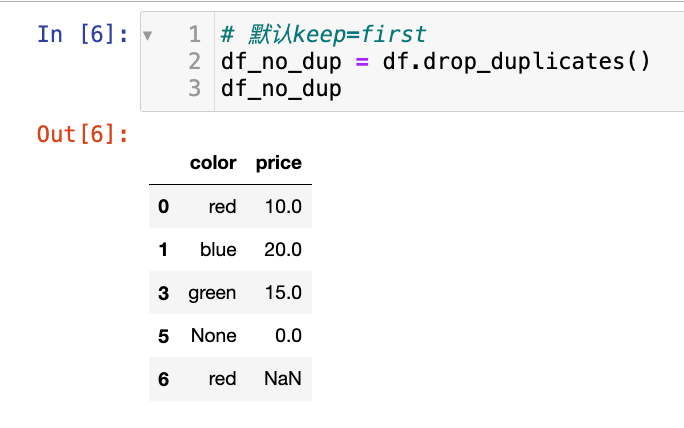
# 默认keep=first
df_no_dup = df.drop_duplicates()
df_no_dup
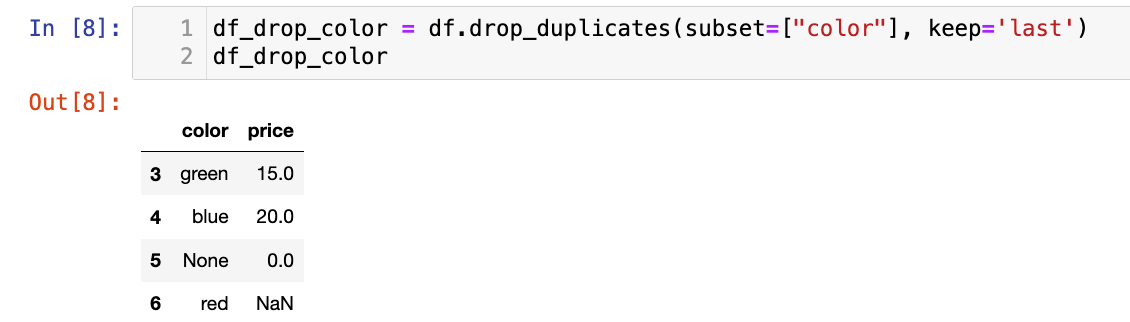
根据color列判断重复,保留最后一个重复项
1
2
df_drop_color = df.drop_duplicates(subset=["color"], keep='last')
df_drop_color
选择题
-
给定
df = pd.DataFrame({'A': [1, 2, 1], 'B': [10, 20, 10]}),执行df.drop_duplicates(keep='last')后,df的内容是什么?A.
DataFrame包含[1, 2, 1]和[10, 20, 10]。B.
DataFrame包含[2, 1]和[20, 10]。C.
DataFrame包含[1, 2]和[10, 20]。D.
DataFrame包含[1, 2, 1]和[10, 20, 10],但顺序不同。答案:B
-
df.duplicated()方法的keep='False'参数的作用是?A. 不删除任何重复项。
B. 删除所有重复项,包括第一次出现的。
C. 将所有重复项(包括第一次/最后一次出现)都标记为
True。D. 报错。
答案:C,
df.duplicated()方法的keep='False'参数的作用是:keep='False'会将所有重复行(包括第一次和最后一次出现)标记为 True。例如,对于重复的行,所有出现都会被标记为重复。
编程题
- 创建一个 DataFrame
orders,包含'OrderID','CustomerID','Product','Quantity'四列,并包含一些重复的OrderID和CustomerID组合。 - 找出所有完全重复的行。
- 删除所有完全重复的行,只保留第一次出现的记录。
- 找出并删除那些
CustomerID和Product都重复的记录,保留最后一次出现的记录。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
orderID = [1, 2, 1, 10, 9, 8, 5, 10]
customerID = [1, 99, 1, 10, 88, 8, 55, 10]
product = ["Apple", "Banana", "Orange", "Grapes", "Flower", "Milk", "Shoes", "Hat"]
quantity = np.random.randint(10, 50, (8, ))
order_dict = {"OrderID": orderID, "CustomerID": customerID, "Product": product, "Quantity": quantity}
orders = pd.DataFrame(data=order_dict)
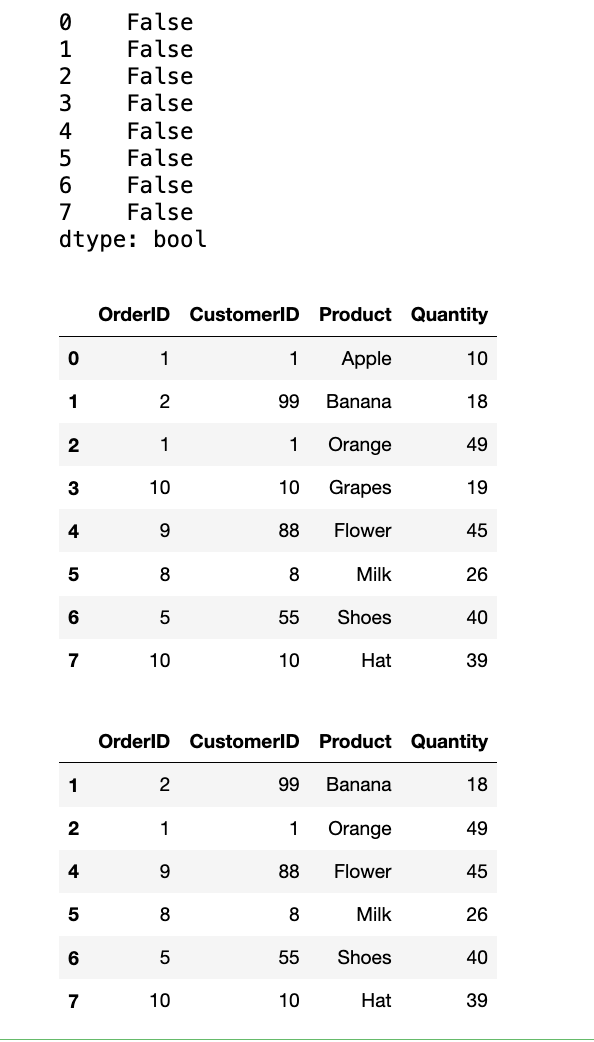
# 找出所有完全重复的行
dup_line_all = orders.duplicated()
display(dup_line_all)
# 删除所有完全重复的行,只保留第一次出现的记录
orders = orders.drop_duplicates() # 默认keep=first
display(orders)
# 找出并删除那些 CustomerID 和 Product 都重复的记录,保留最后一次出现的记录
orders = orders.drop_duplicates(subset=["OrderID", "CustomerID"], keep="last")
display(orders)
2.空数据过滤
空数据(缺失值)是真实世界数据中普遍存在的问题。pandas 使用 NaN(Not a Number)来表示缺失值,并提供了一系列工具来检测、删除和填充这些缺失值。
df.isnull()/df.isna():- 返回一个布尔 DataFrame,其中缺失值的位置为
True,非缺失值的位置为False。 isnull()和isna()是等价的。
- 返回一个布尔 DataFrame,其中缺失值的位置为
df.notnull()/df.notna():- 返回一个布尔 DataFrame,其中非缺失值的位置为
True,缺失值的位置为False。
- 返回一个布尔 DataFrame,其中非缺失值的位置为
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False):- 删除包含缺失值的行或列。
axis: 指定删除行 (0或'index') 还是列 (1或'columns')。how: 指定删除策略。'any'(默认):如果行/列中至少有一个NaN,则删除。'all':如果行/列中所有值都是NaN,则删除。
thresh: 整数,要求行/列中至少有多少个非NaN值才保留。subset: 列表,指定只在这些列中查找NaN来决定是否删除行。
df.fillna(value=None, method=None, axis=None, limit=None, inplace=False):- 填充缺失值。
value: 用于填充缺失值的值(标量、字典、Series 或 DataFrame)。method: 填充方法。'ffill'或'pad':使用前一个有效观测值填充。'bfill'或'backfill':使用后一个有效观测值填充。
axis: 填充方向(0或'index'沿着行填充,1或'columns'沿着列填充)。limit: 整数,限制连续填充的缺失值数量。
缺失值的处理是数据预处理的关键步骤。
pandas在底层对NaN值进行了特殊优化,使其在计算时能够被正确识别和处理(例如,sum()会默认跳过NaN)。
dropna()通过遍历行或列,检查NaN的存在性,并根据how和thresh参数来决定是否保留。fillna()则根据指定的value或method来替换NaN。ffill和bfill方法涉及到在内存中进行前向或后向填充,这在时间序列数据中非常有用。这些操作通常返回新的 DataFrame(除非
inplace=True),因为它们会改变 DataFrame 的内容或结构。
【缺失值处理策略】
- 删除: 当缺失值占比较小或数据量足够大时,可以直接删除包含缺失值的行或列。
- 填充:
- 常数填充: 用 0、平均值、中位数、众数等填充。
- 插值填充: 使用
'ffill','bfill'或更复杂的插值方法(如线性插值interpolate())。 - 模型预测填充: 使用机器学习模型预测缺失值。
- 标记: 有时,缺失本身就是一种信息,可以创建一个新的布尔列来标记缺失值的位置。
【1】判断是否存在空数据:
1
2
3
4
data = {"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'], 'price': [10, 20, 10, 15, 20, 0, np.nan]}
df = pd.DataFrame(data=data)
display(df)
df.isnull()

【2】删除空数据:
1
2
3
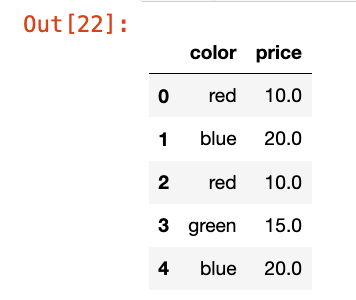
# 只要有值是nan就删除
drop_na_df = df.dropna(how="any")
drop_na_df
【3】填充空数据:
1
2
3
4
5
6
7
8
9
10
data = {
"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price': [10, 20, 10, 15, 20, 0, np.nan],
'col3': [10, 20, np.nan, np.nan, np.nan, np.nan, np.nan],
'col4': [10, 20, np.nan, np.nan, np.nan, np.nan, np.nan]
}
df = pd.DataFrame(data=data)
display(df)
df_fill_ = df.fillna(value=111)
display(df_fill_)
也可以用前一个有效值/后一个有效值填充:
现在可以直接用
df.ffill()或者df.bfill()进行填充。

1
2
3
4
5
display(df)
df_fill_f = df.ffill()
display(df_fill_f) # 用前一个值进行填充
df_fill_b = df.bfill()
display(df_fill_b) # 用后一个值进行填充
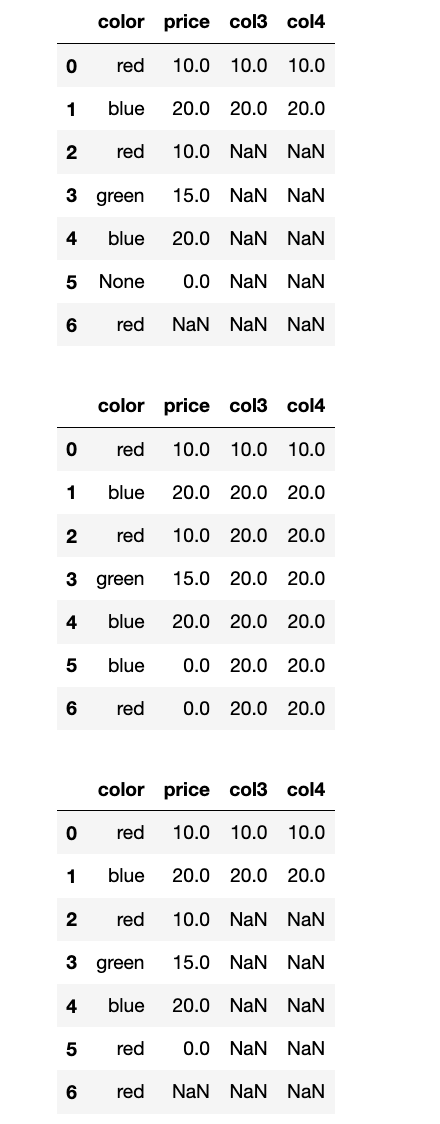
用均值填充:
1
2
3
4
5
display(df)
# price这一列的填充(用均值)
display(np.mean(df.price))
df_mean_fill = df.fillna(value=df["price"].mean())
display(df_mean_fill)
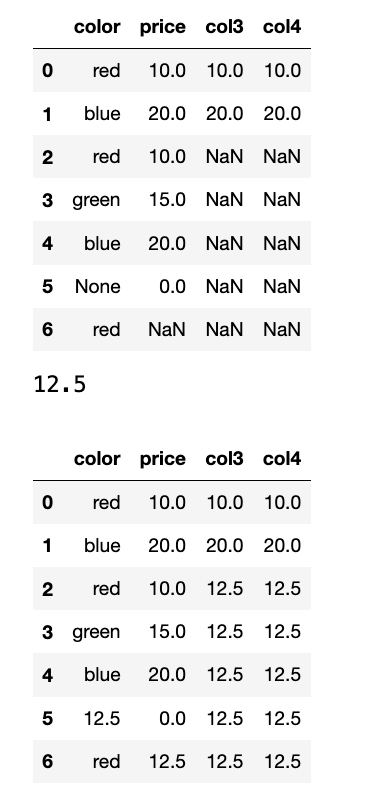
选择题
-
给定
df = pd.DataFrame({'A': [1, np.nan], 'B': [3, 4]}),执行df.dropna(how='all')后,df的内容是什么?A.
DataFrame包含[1, np.nan]和[3, 4]。B.
DataFrame包含[1]和[3]。C.
DataFrame包含[1, np.nan]和[3, 4],但顺序不同。D. 报错。
答案:A,
df.dropna(how='all')会删除所有列均为 NaN 的行。 -
以下哪个方法用于使用前一个有效观测值填充缺失值?
A.
df.fillna(value=0)B.
df.fillna(method='bfill')C.
df.fillna(method='ffill')D.
df.dropna()答案:C,
df.fillna(value=0):用 0 填充缺失值。df.fillna(method='bfill'):用后一个有效值填充(后向填充)。df.fillna(method='ffill'):用前一个有效值填充(前向填充)。df.dropna():删除包含缺失值的行。
编程题
- 创建一个 DataFrame
sensor_readings,包含'Temperature','Humidity','Pressure'三列,以及 5 行数据。在'Temperature'和'Humidity'列中随机插入一些np.nan值。 - 检查 DataFrame 中是否存在任何缺失值。
- 删除所有包含至少一个缺失值的行。
- 重新创建原始 DataFrame,并使用每列的均值来填充该列的缺失值。
- 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
t = [38, 26, np.nan, np.nan, 21]
humid = [90, np.nan, 90, 80, np.nan]
pressure = [89, 90, 65, 89, 28]
# 创建df:'Temperature', 'Humidity', 'Pressure' 三列,以及 5 行数据
s_data = {"Temperature": t, "Humidity": humid, "Pressure": pressure}
df = pd.DataFrame(data=s_data)
display(df)
# 检查 DataFrame 中是否存在任何缺失值
display(df.isnull())
# 删除所有包含至少一个缺失值的行
df_drop_na = df.dropna(how="any")
display(df_drop_na)
# 重新创建原始 DataFrame,并使用每列的均值来填充该列的缺失值
df_new = pd.DataFrame()
df_new["Temperature"] = df["Temperature"].fillna(df["Temperature"].mean()).round(2)
df_new["Humidity"] = df["Humidity"].fillna(df["Humidity"].mean()).round(2)
df_new["Pressure"] = df["Pressure"]
display(df_new)
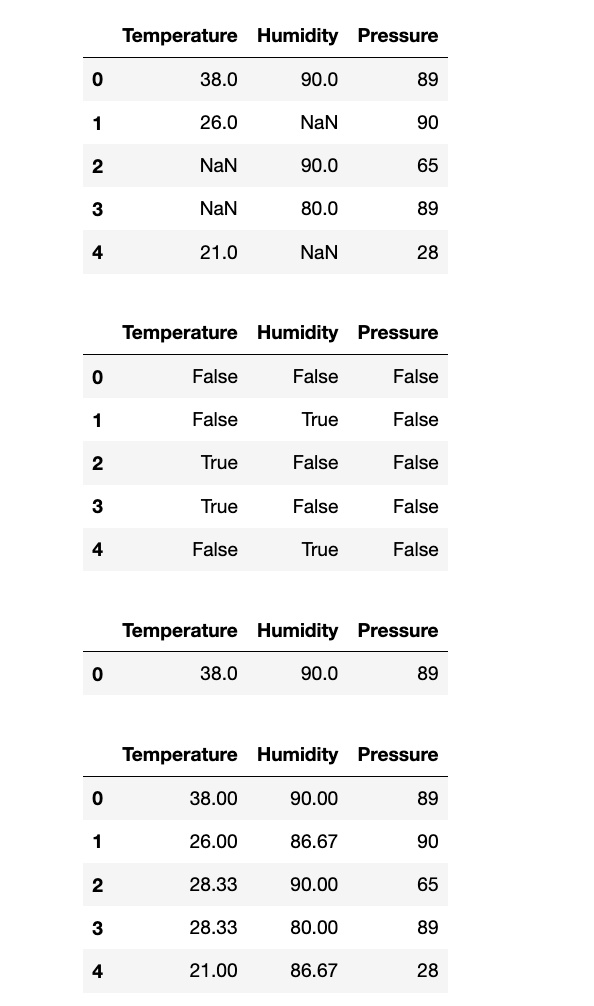
3.指定行或者列过滤
除了基于条件过滤,我们还可以直接通过列名或行索引来删除指定的行或列。
- 删除列:
del df['ColumnName']:直接删除指定的列。这是 Python 原生的del关键字,会直接修改 DataFrame。df.drop(labels, axis=1, inplace=False):删除指定的列。labels: 要删除的列名(单个字符串或列表)。axis=1(或'columns'):表示删除列。inplace: 布尔值,如果为True,则直接修改原始 DataFrame。
- 删除行:
df.drop(labels, axis=0, inplace=False):删除指定的行。labels: 要删除的行索引(单个值或列表)。axis=0(或'index'):表示删除行。
删除行或列涉及到 DataFrame 内部数据结构的重组。
- 删除列: 当删除一列时,
pandas会从内部的 Series 字典中移除对应的 Series,并更新列索引。这个操作通常比较高效,因为 Series 本身是独立的。- 删除行: 当删除行时,
pandas需要创建一个新的 DataFrame,将未被删除的行复制到新的内存空间中。这是因为 DataFrame 的行通常是连续存储的,删除中间的行会破坏这种连续性,需要重新排列。因此,删除行通常会涉及数据复制。
inplace=True 是一个方便的参数,它允许函数直接修改原始 DataFrame,而不需要返回新的 DataFrame。这可以节省内存,但在链式操作中需要谨慎使用,因为它会改变原始对象。在现代 pandas 实践中,更推荐返回新 DataFrame,然后将其赋值给变量,以提高代码的可读性和可预测性。
【1】使用del 删除指定的列,会改变原来的df:
1
2
3
4
5
6
7
8
9
10
11
data = {
"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price': [10, 20, 10, 15, 20, 0, np.nan],
'col3': [10, 20, np.nan, np.nan, 80, np.nan, np.nan],
'col4': [10, 20, 90, 80, np.nan, np.nan, np.nan]
}
df = pd.DataFrame(data=data)
display(df)
# del df[""]
del df["col4"]
display(df)
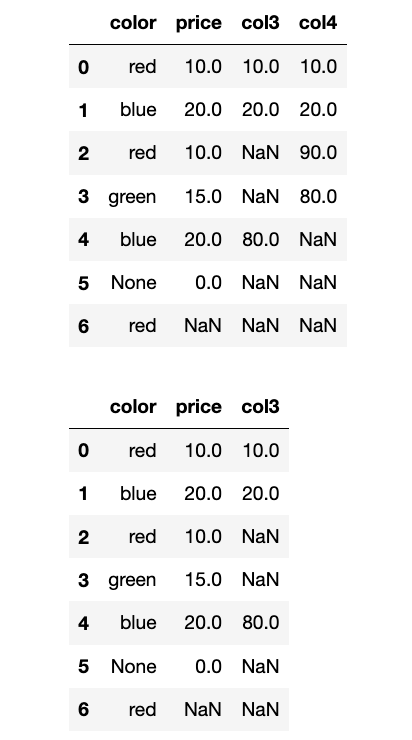
【2】df.drop()删除一列,会返回新的df:
1
2
df_drop_col3 = df.drop(labels=["col3"], axis=1)
display(df_drop_col3, df)
也可以删除多列:
1
2
3
4
5
6
7
8
9
10
11
12
data = {
"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price': [10, 20, 10, 15, 20, 0, np.nan],
'col3': [10, 20, np.nan, np.nan, 80, np.nan, np.nan],
'col4': [10, 20, 90, 80, np.nan, np.nan, np.nan],
"col5": np.random.randint(0, 101, (7, ))
}
df = pd.DataFrame(data=data)
display(df)
# 删除col3,col5这2列:
df_ = df.drop(labels=["col3", "col5"], axis=1)
display(df_, df)

【3】删除行:
1
2
3
4
5
6
7
8
9
10
11
data = {
"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price': [10, 20, 10, 15, 20, 0, np.nan],
'col3': [10, 20, np.nan, np.nan, 80, np.nan, np.nan],
'col4': [10, 20, 90, 80, np.nan, np.nan, np.nan],
"col5": np.random.randint(0, 101, (7, ))
}
df = pd.DataFrame(data=data)
display(df)
df_ = df.drop(labels=[0, 1, 4], axis=0)
display(df_, df)
【4】inplace=True会直接修改原来的df
1
2
3
4
5
6
7
8
9
10
11
data = {
"color": ['red', 'blue', 'red', 'green', 'blue', None, 'red'],
'price': [10, 20, 10, 15, 20, 0, np.nan],
'col3': [10, 20, np.nan, np.nan, 80, np.nan, np.nan],
'col4': [10, 20, 90, 80, np.nan, np.nan, np.nan],
"col5": np.random.randint(0, 101, (7, ))
}
df = pd.DataFrame(data=data)
display(df)
df.drop(labels=[0, 1, 4], axis=0, inplace=True)
display(df)
选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),以下哪个操作会删除'B'列并修改原始 DataFrame?A.
df.drop(columns='B')B.
del df['B']C.
df.drop(labels='B', axis=1, inplace=False)D.
df.drop('B', axis=0)答案:B
-
df.drop(labels=[0, 2], axis=0)的作用是什么?A. 删除列名为
0和2的列。B. 删除行索引为
0和2的行。C. 删除第 0 列和第 2 列。
D. 删除第 0 行和第 2 行。
答案:B
编程题
- 创建一个 DataFrame
inventory,包含'Item','Category','Stock'三列和 6 行数据。 - 删除
'Category'列。 - 删除行索引为 2 和 4 的行。
- 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
item = ["Apple", "Banana", "Orange", "Hat", "Shoes", "Flower"]
category = ["fruit", "fruit", "fruit", "clothes", "clothes", "dec"]
stock = np.random.randint(0, 151, (6, ))
data = {"Item": item, "Category": category, "Stock": stock}
df = pd.DataFrame(data=data)
display(df)
# 删除 'Category' 列。
del df["Category"]
display(df)
# 删除行索引为 2 和 4 的行。
df_ = df.drop(labels=[2, 4], axis=0)
display(df_, df)
4.函数 filter 使用
df.filter() 方法提供了一种灵活的方式来根据索引或列名进行筛选,支持精确匹配、模糊匹配和正则表达式匹配。
- 基本语法:
df.filter(items=None, like=None, regex=None, axis=None)items: 列表,用于精确匹配行索引或列标签。只保留列表中存在的标签。like: 字符串,用于模糊匹配行索引或列标签。保留包含该字符串的标签。regex: 字符串,用于正则表达式匹配行索引或列标签。保留符合正则表达式的标签。axis: 指定在哪个轴上进行过滤。0(或'index'):在行索引上过滤。1(或'columns'):在列标签上过滤。None(默认):如果提供了items,则默认为columns;如果提供了like或regex,则默认为index。为了明确起见,建议始终指定axis。
filter()方法在底层会遍历指定轴上的所有标签,并根据items、like或regex参数提供的条件进行匹配。匹配成功的标签会被保留,不匹配的则被过滤掉。这个操作会返回一个新的 DataFrame,其中只包含满足条件的行或列。
filter 的实用场景
- 选择特定模式的列: 例如,选择所有以
_id结尾的列,或所有包含temp的列。 - 选择特定模式的行: 例如,选择所有以
user_开头的用户 ID 的行。 - 批量重命名前的预筛选: 在对大量列进行操作前,先用
filter筛选出感兴趣的列。
【1】使用items精确筛选列标签:
1
2
3
4
5
6
7
8
data = np.array([
[3, 7, 1],
[2, 8, 256]
])
df = pd.DataFrame(data=data, index=["dog_A", "dog_B"], columns=["China_ID", "America_Code", "France_key"])
display(df)
df1 = df.filter(items=["China_ID", "France_key"])
display(df1)

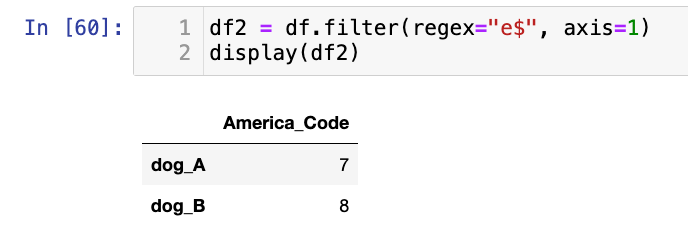
【2】正则表达式筛选列标签:(以e结尾的列名)
1
2
df2 = df.filter(regex="e$", axis=1)
display(df2)
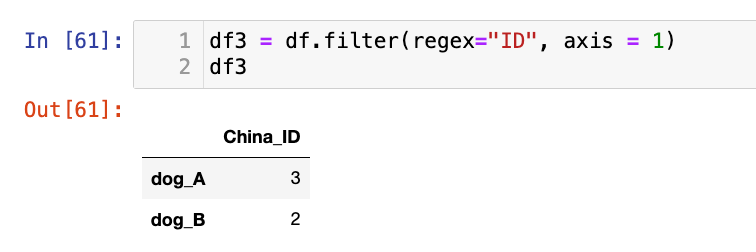
还有比如,包含ID的列名:
1
2
df3 = df.filter(regex="ID", axis = 1)
df3
1
2
df6 = df.filter(regex="China|America", axis=1)
df6

【3】like模糊匹配:
1
2
df4 = df.filter(like="og", axis=0)
df4

1
2
df5 = df.filter(like="B", axis=0)
df5

选择题
-
给定
df = pd.DataFrame({'col_A': [1], 'col_B': [2], 'another_col': [3]}),执行df.filter(like='col', axis=1)的结果是什么?A. 包含
col_A,col_B,another_col三列。B. 包含
col_A,col_B两列。C. 包含
col_A一列。D. 报错。
答案:A
-
df.filter(regex='^C', axis=0)的作用是?A. 选择所有以
C开头的列。B. 选择所有以
C开头的行索引。C. 选择所有包含
C的列。D. 选择所有包含
C的行索引。答案:B
编程题
- 创建一个 DataFrame
log_data,包含'user_id_123','event_type','timestamp','user_id_456'四列,以及 5 行数据。 - 使用
df.filter()筛选出所有列名中包含'user_id'的列。 - 使用
df.filter()筛选出所有行索引中包含数字的行(假设行索引是默认整数索引)。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
uid123 = np.arange(0, 5)
event_type = list("ABCDE")
time = ["2025-07-23"] * 5
uid456 = np.arange(-1, 4)
log_data = pd.DataFrame(data={
"user_id_123": uid123,
"event_type": event_type,
"timestamp": time,
"user_id_456": uid456
})
display(log_data)
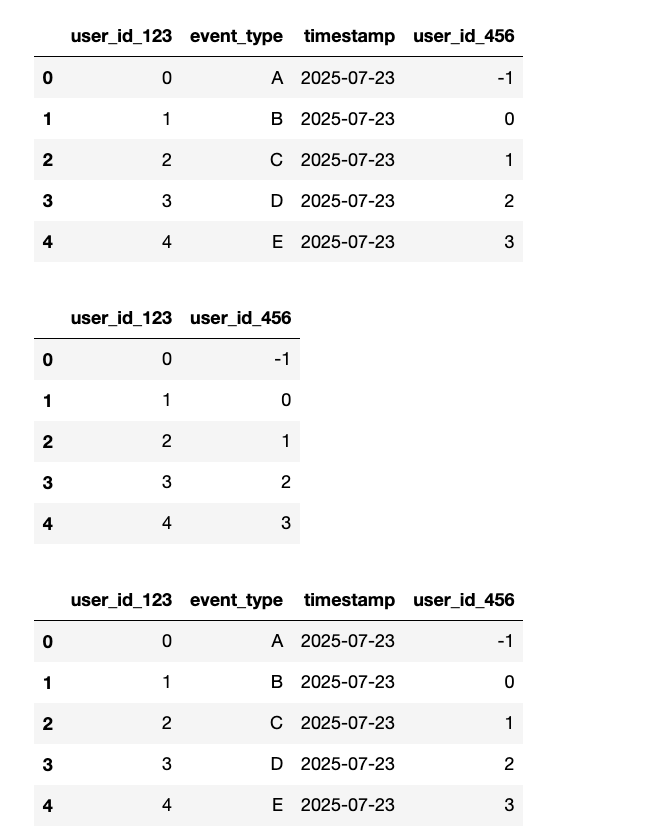
# 使用 df.filter() 筛选出所有列名中包含 'user_id' 的列。
res1 = log_data.filter(regex="user_id", axis=1)
display(res1)
# 使用 df.filter() 筛选出所有行索引中包含数字的行(假设行索引是默认整数索引)。
res2 = log_data.filter(regex=r"\d+", axis=0)
display(res2)
5.异常值过滤
异常值(Outliers)是数据集中与大多数数据点显著不同的观测值。它们可能是数据输入错误、测量误差,也可能是真实但罕见的事件。识别和处理异常值是数据清洗的关键步骤,因为异常值会对统计分析和机器学习模型的性能产生负面影响。
- 3\(\sigma\) 原则(经验法则):
- 对于服从正态分布的数据,约 99.7% 的数据点落在均值 (\(\mu\)) 的 pm3 倍标准差 (\(\sigma\)) 范围内。
- 因此,任何超出 (\(\mu−3\sigma,\mu+3\sigma\)) 范围的数据点都可以被视为异常值。
- 计算:
df.mean():计算均值。df.std():计算标准差。
- 条件筛选: 一旦识别出异常值,可以使用布尔索引来选择或删除它们。
df[condition]:选择满足条件的行。df.drop(labels=index_to_drop, axis=0):根据行索引删除异常值行。
- 其他异常值检测方法:
- IQR (Interquartile Range) 方法: 对于非正态分布数据更鲁棒。异常值通常定义为小于 \(Q_1−1.5*IQR\) 或大于 \(Q_3+1.5*IQR\)的数据点,其中\(Q_1\) 是第一四分位数,\(Q_3\) 是第三四分位数,\(IQR=Q_3−Q_1\)。
- Z-score 方法: 衡量数据点距离均值有多少个标准差。通常,Z-score 超过 2 或 3 的数据点被视为异常值。
- 可视化方法: 箱线图(Box Plot)、散点图等可以直观地帮助识别异常值。
- 基于模型的方法: 孤立森林(Isolation Forest)、局部异常因子(Local Outlier Factor, LOF)等机器学习算法。
异常值过滤的原理是基于统计学或数据分布的假设。
- 3\(\sigma\) 原则: 假设数据近似服从正态分布,那么超出 3 倍标准差范围的数据点出现的概率非常低,因此被认为是异常的。
- IQR 方法: 这种方法不依赖于正态分布假设,而是基于数据的四分位数,因此对偏斜数据更具鲁棒性。它关注数据集中间 50% 的范围。
- 布尔索引的应用: 一旦识别出异常值的条件,就可以将其转换为布尔 Series 或 DataFrame,然后利用
pandas的布尔索引功能来高效地选择或删除这些数据点。
【异常值的处理策】
- 删除: 最简单直接,但可能丢失信息,尤其是在样本量较小或异常值本身有意义时。
- 转换: 对异常值进行数学变换(如对数变换),使其更接近正态分布。
- 替换/填充: 用均值、中位数、或更复杂的插值方法替换异常值。
- 不处理: 如果异常值是真实且重要的,可能需要保留它们,但要在模型选择时考虑使用对异常值不敏感的模型(如基于树的模型)。
比如下面这个例子:
1
2
3
4
5
6
7
df2 = pd.DataFrame(data = np.random.randn(10000,3)) # 正态分布数据
display(df2)
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
index = df2[cond].index # 不满足条件的行索引
df3 = df2.drop(labels=index,axis = 0) # 根据行索引,进行数据删除
display(df3)
