pandas 提供了多种功能来将 Series 和 DataFrame 对象组合在一起,这些操作在数据分析中非常常见,例如合并来自不同来源的数据。
1.concat 数据串联
pd.concat() 函数用于沿着某个轴将 pandas 对象(Series 或 DataFrame)串联(concatenate)起来。它提供了灵活的方式来堆叠数据。
- 基本语法:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None)objs: 要串联的pandas对象的序列(列表或元组)。axis: 指定串联的轴。axis=0(默认):按行串联(垂直堆叠)。要求所有对象除了连接轴之外的其他轴的长度必须相同(即列数相同)。axis=1:按列串联(水平堆叠)。要求所有对象除了连接轴之外的其他轴的长度必须相同(即行数相同)。
join: 指定如何处理其他轴上的索引。'outer'(默认):取所有索引的并集(联合),不匹配的位置填充NaN。'inner':取所有索引的交集,只保留所有对象中都存在的索引。
ignore_index: 布尔值,如果为True,则不使用原始索引,而是生成新的整数索引。这在串联后不关心原始索引时很有用。keys: 列表,为串联后的结果创建一个分层索引(MultiIndex),用于标识来自哪个原始对象的数据。
df.append(other, ignore_index=False)方法:append是pd.concat在axis=0上的一个便捷方法,用于在 DataFrame 后面追加行。- 注意:
append方法在未来的pandas版本中可能会被弃用,推荐使用pd.concat()。
pd.concat()的核心原理是索引对齐和数据复制。它会根据指定的axis和join策略,创建一个新的 DataFrame。
- 索引对齐: 在串联之前,
pandas会根据join参数('outer'或'inner')对非连接轴上的索引进行对齐。- 数据复制: 串联操作总是返回一个新的 DataFrame,这意味着数据会被复制到新的内存空间中。这是因为原始 DataFrame 可能在内存中不连续,或者它们的索引需要重新排列以适应新的组合。
concat 的灵活应用
- 分块处理大数据: 可以分批读取数据,然后使用
concat逐块合并。 - 时间序列数据: 串联不同时间段的传感器数据或股票价格。
- 特征工程: 将新生成的特征列与现有 DataFrame 进行水平串联。
【1】行串联(axis=0)
1
2
3
4
5
6
7
# 行索引不同的两个DF
df1 = pd.DataFrame(data=np.random.randint(0, 51, (5, 3)), index=list("ABCDE"), columns=["python", "java", "golang"])
df2 = pd.DataFrame(data=np.random.randint(0, 51, (5, 3)), index=list("FGHIJ"), columns=["Python", "java", "golang"])
# 列不同的df,行索引和df1相同
df3 = pd.DataFrame(data=np.random.randint(100, 200, (5, 2)), index=list("ABCDE"), columns=["java", "cpp"])
concat_axis_0 = pd.concat([df1, df2], axis=0) # axis=0是默认的,不写也可以
concat_axis_0
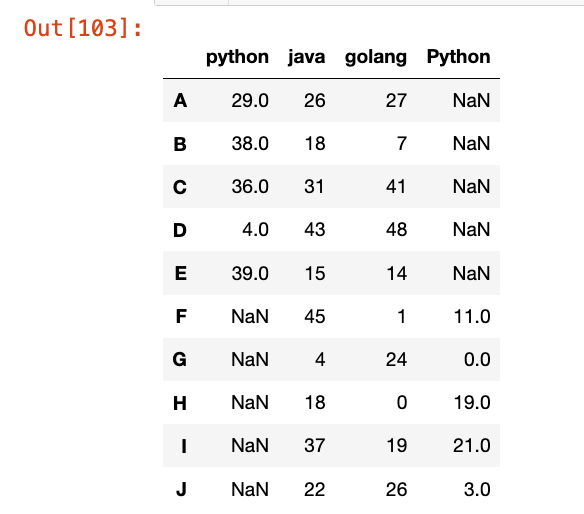
【2】重新生成索引:
1
2
reset_index = pd.concat([df1, df2], ignore_index=True)
reset_index
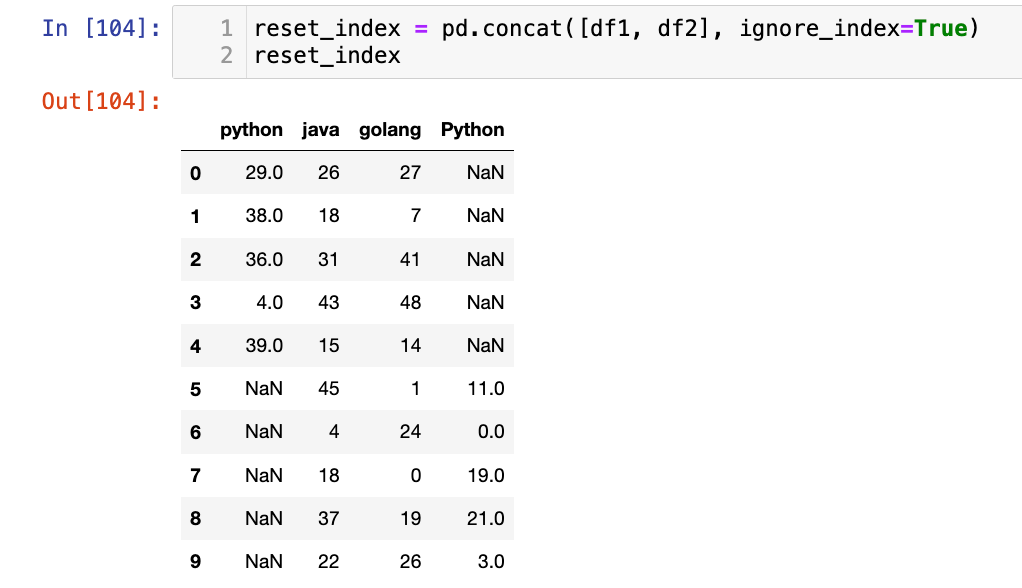
【3】创建分层索引:
1
2
concat_with_keys = pd.concat([df1, df2], keys=["df1_data", "df2_data"])
concat_with_keys
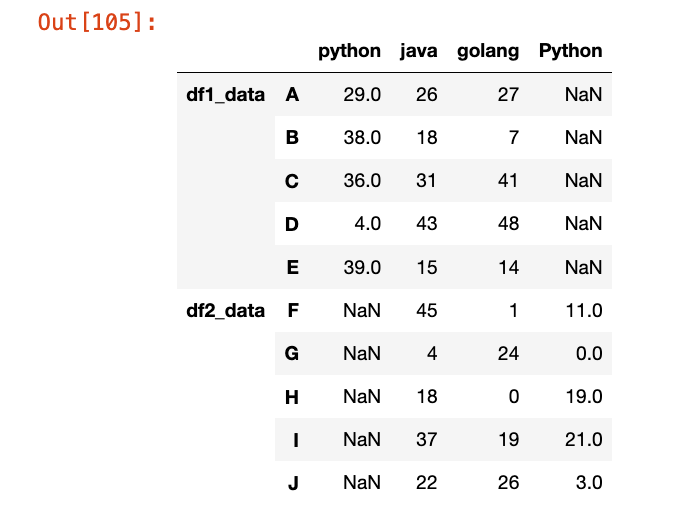

【4】列串联(axis=1)
1
2
col_concat = pd.concat([df1, df3], axis=1)
col_concat
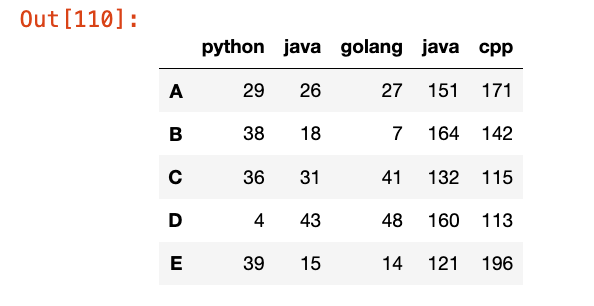
默认outer join
如果行索引不完全匹配,会填充NaN,例如:
1
2
3
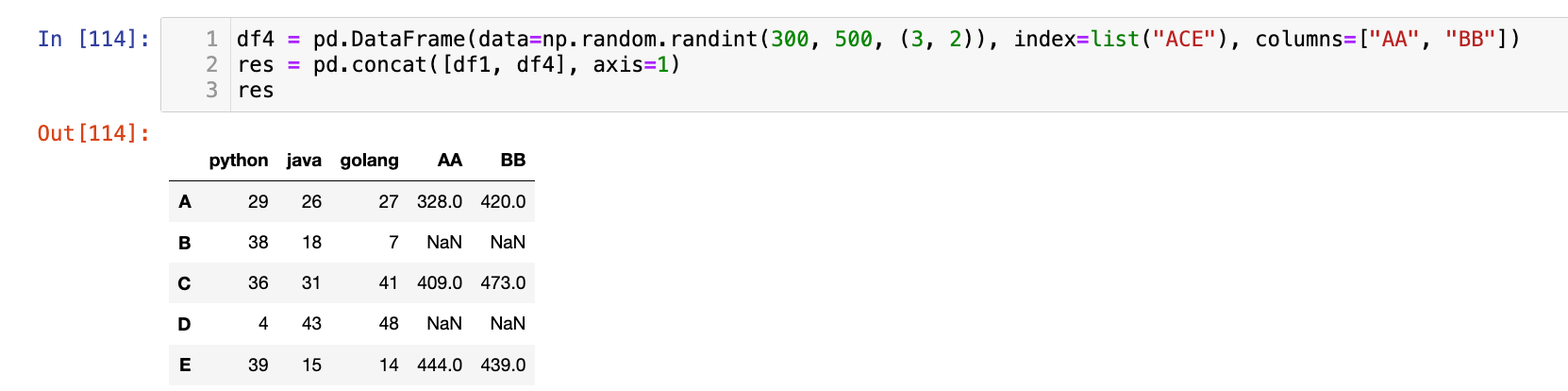
df4 = pd.DataFrame(data=np.random.randint(300, 500, (3, 2)), index=list("ACE"), columns=["AA", "BB"])
res = pd.concat([df1, df4], axis=1)
res
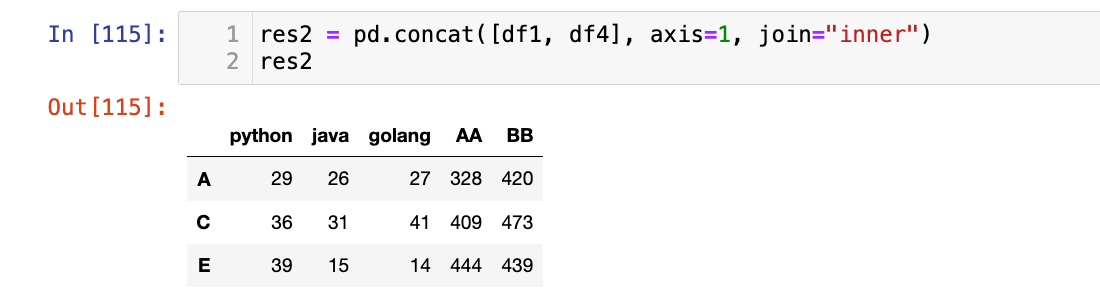
【5】使用inner join:
1
2
res2 = pd.concat([df1, df4], axis=1, join="inner")
res2
选择题
-
给定
df_a = pd.DataFrame({'col1': [1, 2]}, index=['x', 'y'])和df_b = pd.DataFrame({'col2': [3, 4]}, index=['y', 'z']),执行pd.concat([df_a, df_b], axis=1)的结果是什么?A.
DataFrame形状为(2, 2),包含x, y行和col1, col2列。B.
DataFrame形状为(3, 2),包含x, y, z行和col1, col2列,不匹配处为NaN。C.
DataFrame形状为(2, 4),包含x, y行和col1, col2, col1, col2列。D. 报错。
答案:B
-
以下哪项是
pd.concat()和df.append()的共同点?A. 它们都只能沿着行方向进行串联。
B. 它们都返回原始 DataFrame 的视图。
C. 它们都支持
join参数来处理索引对齐。D. 它们都返回一个新的 DataFrame。
答案:D
2.插入 (insert)
在 pandas 中,插入列比插入行更直接。
- 插入列 (
df.insert(loc, column, value, allow_duplicates=False)):loc: 整数,指定新列插入的位置(索引)。例如loc=0在第一列插入,loc=1在第二列插入。column: 字符串,新列的名称。value: 新列的值,可以是标量、Series、NumPy 数组或列表。如果value是 Series,pandas会根据行索引自动对齐数据。allow_duplicates: 布尔值,如果为True,则允许插入与现有列名重复的列。默认为False。
- 插入行:
pandas没有直接的insert_row()方法来在指定位置插入行。- 最常见的做法是使用
pd.concat()结合切片操作来实现:将 DataFrame 分割成两部分,在中间插入新行,然后重新合并。 df.append()可以用于在 DataFrame 末尾追加行(但如前所述,推荐使用pd.concat)。
列插入: DataFrame 的列实际上是 Series 对象的字典。当您插入一列时,
pandas会创建一个新的 Series,并将其添加到 DataFrame 的内部列字典中,同时更新 DataFrame 的列索引。由于列是独立的 Series,插入一列通常不会导致大量数据复制,除非需要重新组织内存布局。行插入(复杂性): DataFrame 的行是其索引。在中间插入行意味着需要重新分配内存并复制整个 DataFrame 的数据,因为 DataFrame 的数据通常是按行(或列)连续存储的。因此,
pandas不提供直接的行插入方法,而是鼓励使用更通用的concat,它在底层会处理必要的内存重组。
【插入多列】
虽然 df.insert() 每次只能插入一列,但您可以通过循环或多次调用来插入多列。或者,更常见和高效的做法是,先创建包含所有新列的 DataFrame,然后使用 pd.concat(axis=1) 将其与原始 DataFrame 合并
1
2
3
4
5
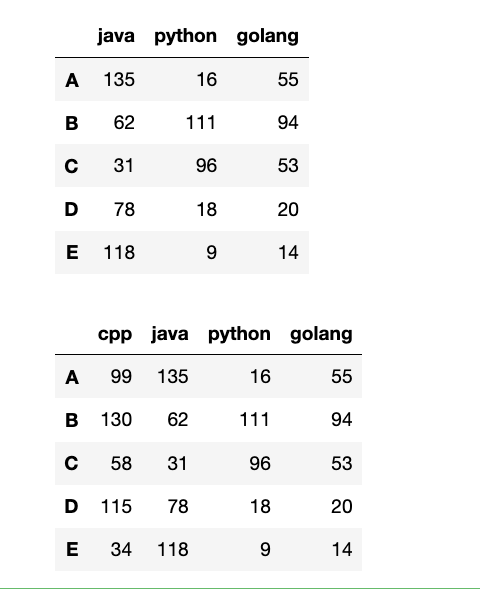
data = np.random.randint(0, 151, (5, 3))
df = pd.DataFrame(data = data, columns=["java", "python", "golang"], index=list("ABCDE"))
display(df)
df.insert(0, "cpp", np.random.randint(0, 151, (5, )))
display(df)
插入一个Series作为新的一列,自动对齐索引:
1
2
3
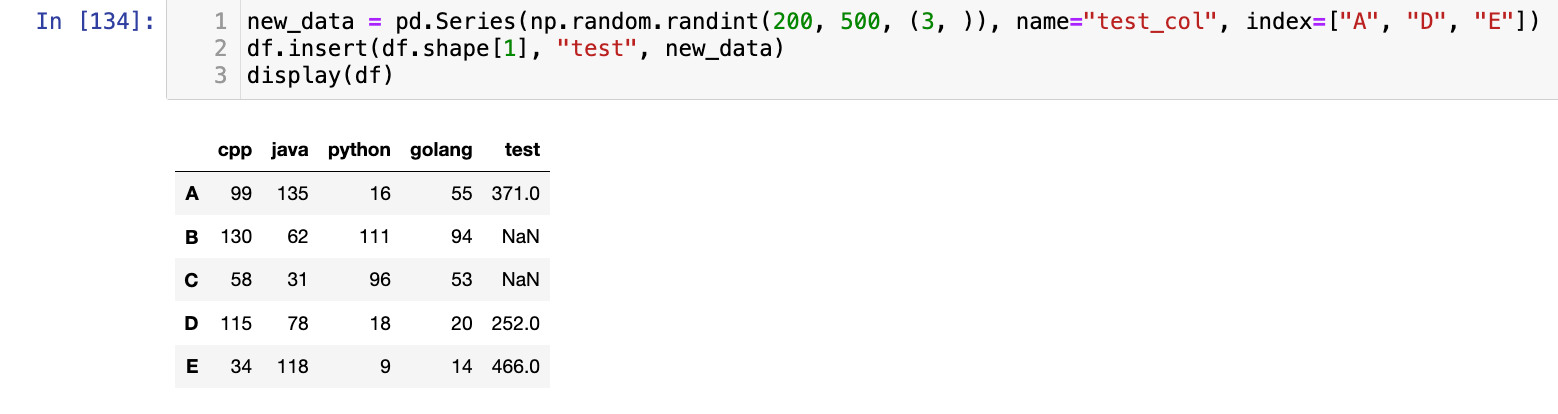
new_data = pd.Series(np.random.randint(200, 500, (3, )), name="test_col", index=["A", "D", "E"])
df.insert(df.shape[1], "test", new_data)
display(df)
以上是插入列,如果想要插入行,可以通过concat实现:
1
2
3
4
5
6
7
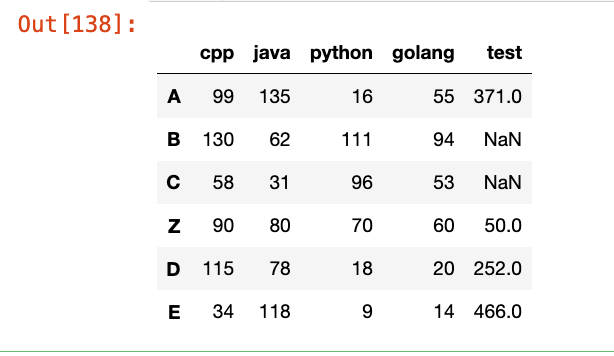
df_new = pd.DataFrame(data=[[90, 80, 70, 60, 50]], columns=df.columns, index=["Z"])
# 在CD之间插入新的一行,需要先分割
df_1 = df.loc[:"C"] # 包含C
df_2 = df["D":]
# 然后再合并
res = pd.concat([df_1, df_new, df_2])
res
选择题
-
以下哪个方法可以在 DataFrame 的指定位置插入一列?
A.
df['new_col'] = valueB.
df.insert()C.
df.append()D.
pd.concat(axis=1)答案:B
-
如果要将一个新行插入到 DataFrame 的中间位置,最推荐的方法是什么?
A. 使用
df.insert_row()。B. 使用
df.append()。C. 将 DataFrame 分割成两部分,插入新行,然后使用
pd.concat()重新合并。D. 直接修改 DataFrame 的
values属性。答案:C,
df.append()(pandas 2.0 之前)用于在 DataFrame 末尾追加行,且已废弃。它无法在中间位置插入行。
编程题
- 创建一个 DataFrame
employees,包含'Name','Age'两列和 4 行数据。 - 在
'Age'列的左侧(即索引 1 的位置)插入一个新列'Gender',并填充'Male','Female','Male','Female'。 - 创建一个新的 Series
new_employee = pd.Series({'Name': 'Frank', 'Age': 28, 'Gender': 'Male'})。 - 将
new_employee作为新行插入到 DataFrame 的第 2 行(索引为 2)之后。 - 打印每一步操作后的 DataFrame
1
2
3
4
5
6
7
8
9
10
11
12
13
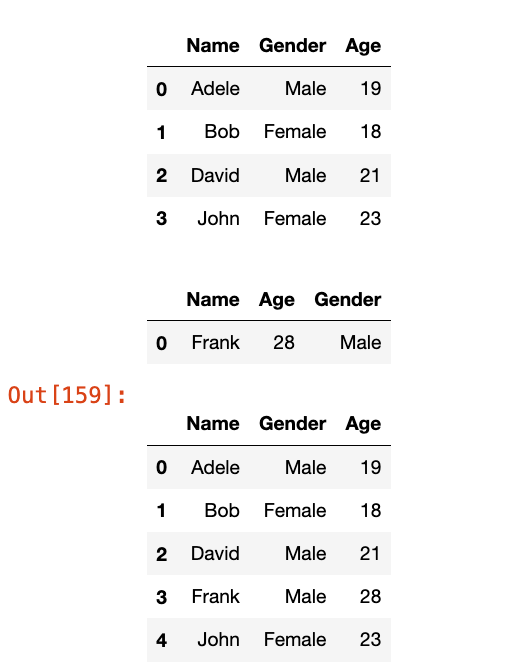
dict_data = {"Name": ["Adele", "Bob", "David", "John"], "Age": [19, 18, 21, 23]}
employees = pd.DataFrame(dict_data)
employees.insert(1, "Gender", ["Male", "Female", "Male", "Female"])
display(employees)
new_employee = pd.Series({'Name': 'Frank', 'Age': 28, 'Gender': 'Male'})
# 分割df,才能在指定位置插入一行
df1 = employees.loc[:2]
df2 = employees.loc[3:]
# 要将Series变成行,才可以concat
new_employee = pd.DataFrame(new_employee).T.reset_index(drop=True)
display(new_employee)
res = pd.concat([df1, new_employee, df2], ignore_index=True)
res
特别注意:将Series变成一行数据:
3.Join SQL 风格合并 (merge)
数据集的合并(merge)或连接(join)运算是关系型数据库的核心操作,pandas 的 pd.merge() 函数是实现这些操作的主要入口点。它允许通过一个或多个键(列或索引)将两个或多个 DataFrame 链接起来。
- 基本语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)left,right: 要合并的两个 DataFrame 对象。how: 指定合并类型,类似于 SQL JOIN。'inner'(默认):内合并,只保留两个 DataFrame 中键都存在的行(交集)。'outer':全外连接,保留所有键的行(并集),不匹配的位置填充NaN。'left':左连接,保留左边 DataFrame 的所有行,并匹配右边 DataFrame 中对应的行。'right':右连接,保留右边 DataFrame 的所有行,并匹配左边 DataFrame 中对应的行。
on: 用于合并的列名(或列名列表)。如果左右 DataFrame 中用于合并的列名相同,可以使用此参数。left_on,right_on: 如果左右 DataFrame 中用于合并的列名不同,分别指定左边和右边 DataFrame 的列名。left_index,right_index: 布尔值,如果为True,则使用 DataFrame 的行索引作为合并键。
pd.merge()在底层执行的是一种高效的哈希连接(hash join)算法。它的工作流程大致如下:
- 键提取: 根据
on,left_on,right_on,left_index,right_index参数,从两个 DataFrame 中提取出用于合并的键。- 哈希表构建: 通常,
pandas会选择较小的一个 DataFrame 的键来构建一个哈希表(或类似的数据结构),其中键映射到对应的行数据。- 查找与匹配: 然后,遍历另一个(通常是较大)DataFrame 的键,在哈希表中查找匹配项。
- 结果构建: 根据
how参数指定的连接类型,将匹配的行(或不匹配但需要保留的行)组合成一个新的 DataFrame。由于结果的形状和内容可能与原始 DataFrame 不同,merge操作总是返回一个副本。
【多键合并与索引合并】
- 多键合并: 当
on或left_on/right_on参数传入一个列名列表时,merge会根据所有指定的列进行复合键匹配。 - 索引合并: 当
left_index=True或right_index=True时,DataFrame 的行索引会被提升为合并键。这在两个 DataFrame 已经通过索引对齐时非常有用。
【1】inner join
1
2
3
4
5
6
7
8
9
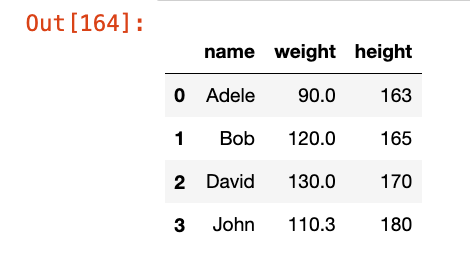
names = ["Adele", "Bob", "David", "John"]
data1 = {"name": names, "weight": [90.0, 120.0, 130.0, 110.3]}
data2 = {"name": names, "height": [163, 165, 170, 180]}
data3 = {"姓名": names, "身高": [190, 190, 190, 190]}
df1 = pd.DataFrame(data = data1)
df2 = pd.DataFrame(data = data2)
df3 = pd.DataFrame(data = data3)
inner_ = pd.merge(df1, df2, how="inner", on="name")
inner_
【2】outer join
1
2
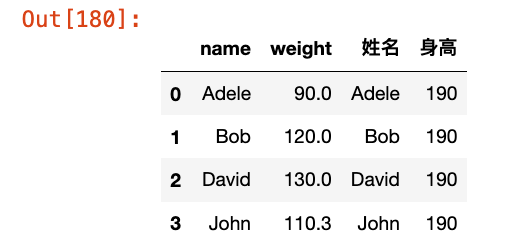
outer_ = pd.merge(df1, df3, how="outer", left_on="name", right_on="姓名")
outer_
【3】左连接:
1
2
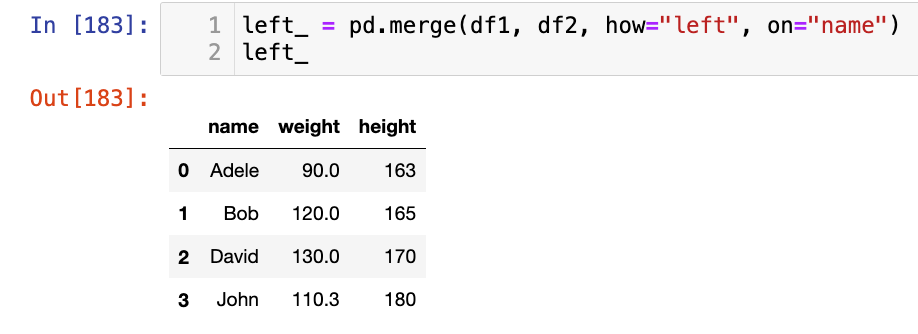
left_ = pd.merge(df1, df2, how="left", on="name")
left_
右连接类似。
【4】索引合并:
1
2
3
4
5
6
7
8
data = np.random.randint(0, 151, (10, 3))
df4 = pd.DataFrame(data=data, columns=["Python", "Java", "Golang"])
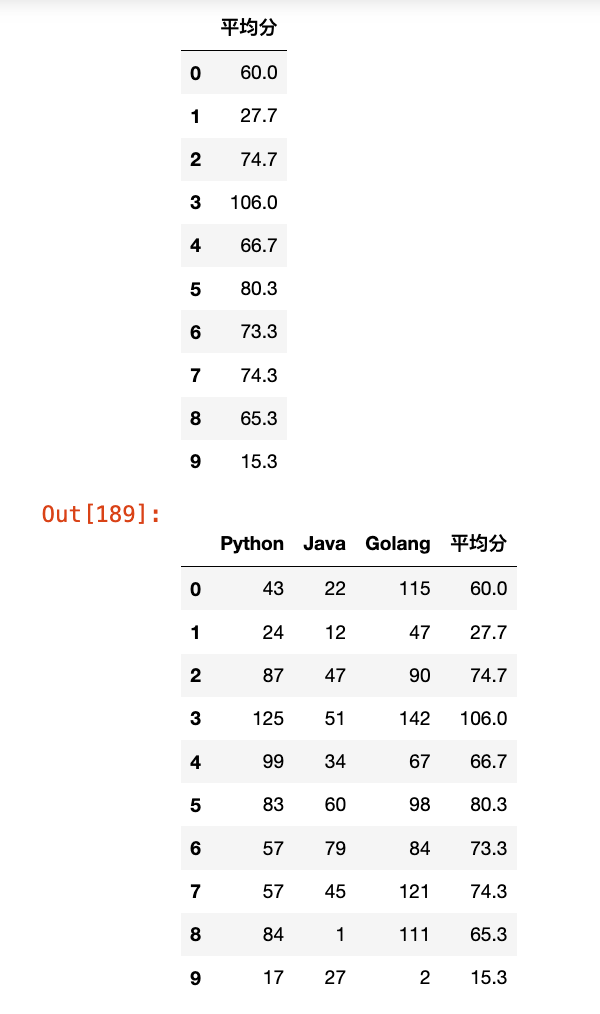
# 计算每个学生的均分,变成df
mean1 = pd.DataFrame(df4.mean(axis=1).round(1), columns=["平均分"])
display(mean1)
# 使用行索引合并
merge1 = pd.merge(df4, mean1, left_index=True, right_index=True)
merge1
选择题
-
给定
df_a = pd.DataFrame({'id': [1, 2], 'value_a': [10, 20]})和df_b = pd.DataFrame({'id': [2, 3], 'value_b': [30, 40]})。执行pd.merge(df_a, df_b, on='id', how='left')的结果是什么?A.
DataFrame包含id=1, value_a=10, value_b=NaN和id=2, value_a=20, value_b=30。B.
DataFrame包含id=2, value_a=20, value_b=30。C.
DataFrame包含id=1, value_a=10, value_b=NaN,id=2, value_a=20, value_b=30,id=3, value_a=NaN, value_b=40。D. 报错。
答案:A
-
如果两个 DataFrame 要通过它们的行索引进行合并,应该使用
pd.merge()的哪个参数组合?A.
on='index'B.
left_on='index', right_on='index'C.
left_index=True, right_index=TrueD.
how='index'答案:C
编程题
- 创建两个 DataFrame:
df_employees:包含'EmployeeID','Name','Department'。df_salaries:包含'EmployeeID','Salary','Bonus'。
- 使用
pd.merge()进行内合并,将两个 DataFrame 基于'EmployeeID'合并。 - 创建一个新的 DataFrame
df_projects:包含'ProjectID','EmployeeID','ProjectName',其中包含一些在df_employees中不存在的EmployeeID。 - 使用
pd.merge()进行左连接,将合并后的员工信息与df_projects基于'EmployeeID'合并。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
employeeID = np.arange(1, 11)
names = ["Adele", "Alice", "Bob", "Charlie", "David", "Fred", "Gary", "John", "Sally", "Zed"]
dept = ["Management", "IT", "IT", "HR", "Management", "Sales", "HR", "Management", "HR", "Sales"]
salaries = np.random.randint(5000, 50000, (10, ))
bonus_ = np.random.randint(0, 5000, (10, ))
emp = {"EmployeeID": employeeID, "Name": names, "Department": dept}
sal = {"EmployeeID": employeeID, "Salary": salaries, "Bonus": bonus_}
df_employees = pd.DataFrame(columns=["EmployeeID", "Name", "Department"], data = emp)
df_salaries = pd.DataFrame(columns=["EmployeeID", "Salary", "Bonus"], data=sal)
# display(df_employees, df_salaries)
# 使用 `pd.merge()` 进行内合并,将两个 DataFrame 基于 `'EmployeeID'` 合并。
df_all = pd.merge(df_employees, df_salaries, how="inner", on="EmployeeID")
display(df_all)
pro_name = list("ABCDEFGHIJ")
employeeID_ = [1, 2, 3, 99, 89, 5, 7, 9, 21, 100]
pro_dict = {"ProjectID": np.arange(11, 21), "EmployeeID": employeeID_, "ProjectName": pro_name}
df_projects = pd.DataFrame(data = pro_dict)
# display(df_projects)
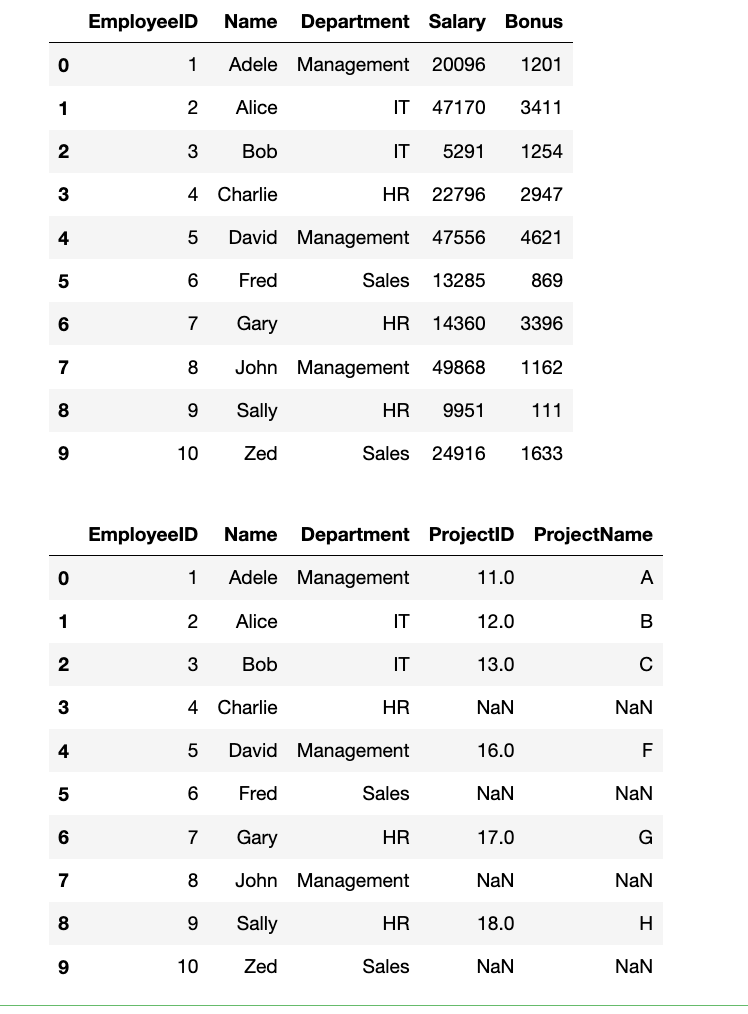
# 使用 `pd.merge()` 进行左连接,将合并后的员工信息与 `df_projects` 基于 `'EmployeeID'` 合并。
df_1 = pd.merge(df_employees, df_projects, how="left", on="EmployeeID")
display(df_1)