数据选取是数据分析的第一步,它允许我们从大型数据集中提取出感兴趣的子集。pandas 提供了多种直观且高效的方法来实现这一点。
1.字段数据(基本索引)
在 pandas 中,DataFrame 的列可以像字典一样通过键(列名)来访问,也可以像 NumPy 数组一样通过整数位置进行切片。
- 选择单列:
df['ColumnName']:这是最常用和推荐的方式,返回一个 Series。df.ColumnName:如果列名是有效的 Python 变量名(不含空格、特殊字符或与 DataFrame 方法名冲突),也可以使用点语法访问,返回一个 Series。不推荐在生产代码中大量使用,因为它可能导致歧义或错误。
- 选择多列:
df[['Column1', 'Column2']]:传入一个包含所需列名的列表,返回一个 DataFrame。
- 行切片:
df[start:end]:与 Python 列表和 NumPy 数组类似,通过整数位置对行进行切片。切片是左闭右开的。这会返回一个 DataFrame。
DataFrame 在内部将数据存储为列的集合,每个列本身就是一个 Series。当您通过列名访问数据时,
pandas会查找对应的 Series 对象并返回它。这种设计使得列操作非常高效。对于行切片,
pandas并没有复制数据,而是返回原始 DataFrame 的一个视图(view)。这意味着对切片结果的修改会直接影响到原始 DataFrame。这是pandas性能优化的一个关键点,因为它避免了不必要的数据复制。
【链式索引的注意事项】
避免使用链式索引进行赋值操作,例如 df['col'][row_index] = value。这可能会导致 SettingWithCopyWarning,并且结果可能不是期望的,因为它可能在视图的副本上操作,而不是原始 DataFrame。推荐使用 .loc 或 .iloc 进行赋值。
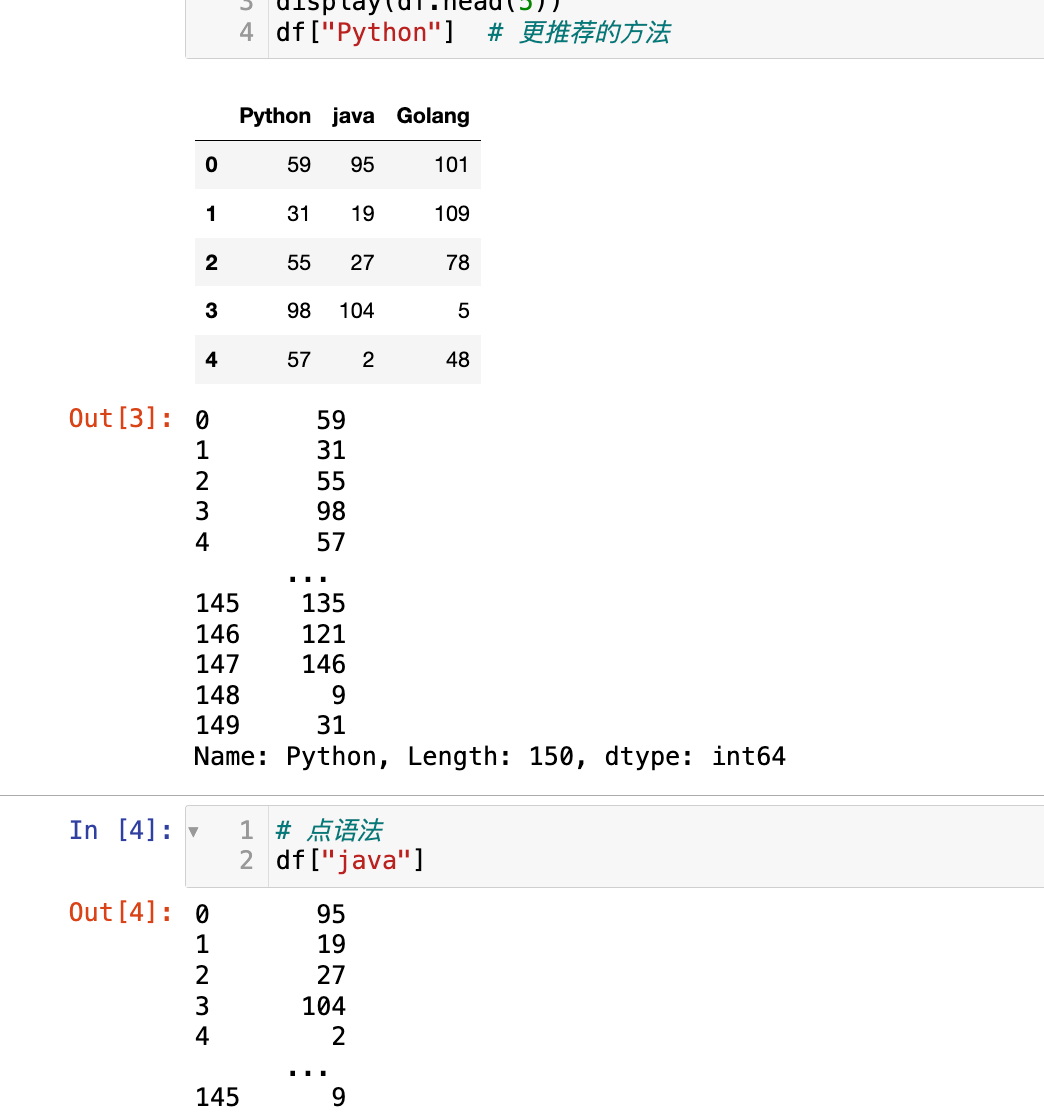
【1】选择单列
1
2
3
4
data = np.random.randint(0, 151, (150, 3))
df = pd.DataFrame(data = data, columns=["Python", "java", "Golang"])
display(df.head(5))
df["Python"] # 更推荐的方法
或者点语法:
1
2
# 点语法
df["java"]
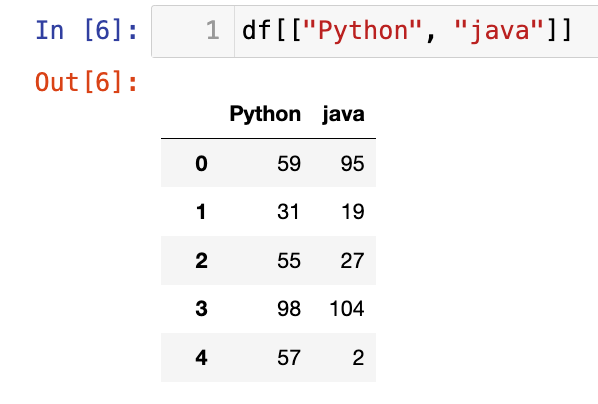
【2】选择多列:用双层方括号[]
1
df[["Python", "java"]]
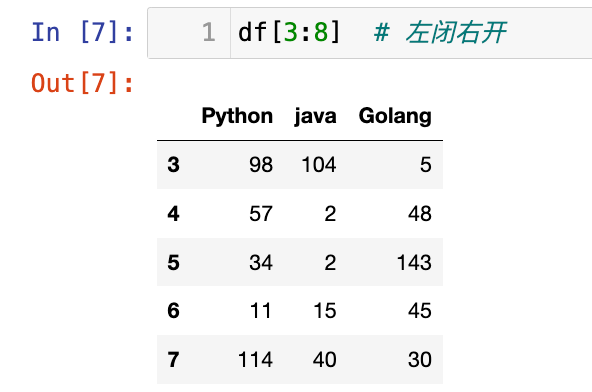
【3】行切片:
1
df[3:8] # 左闭右开
验证行切片是视图:
1
2
3
row_slice_df = df[3:8]
row_slice_df.iloc[0, 0] = 999 # 修改视图
df.head(10)

选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),以下哪项操作会返回一个 Series?A.
df[['A', 'B']]B.
df['A']C.
df[0:1]D.
df答案:B。
-
如果
df是一个 DataFrame,df[5:10]的结果是什么类型?A. Series
B. NumPy
ndarrayC. DataFrame
D. 列表
答案:C。
df[5:10]是对 DataFrame 的行切片操作,表示选择索引从 5 到 9(不包括 10)的行。在 pandas 中,DataFrame 的行切片(基于整数索引或标签)会返回一个新的 DataFrame,包含指定范围的行,保留所有列。
即使切片结果为空(例如 DataFrame 行数少于 5),返回的仍然是一个 DataFrame(空 DataFrame)。
结果不会是 Series(Series 是单列或单行数据的一维结构),也不会是 NumPy 数组或列表。
编程题
- 创建一个 DataFrame
students,包含两列'Name'和'Score',以及 5 行数据。 - 使用两种不同的方式(方括号和点语法)获取
'Score'列,并打印它们。 - 获取
studentsDataFrame 的前 3 行,并打印结果。
1
2
3
4
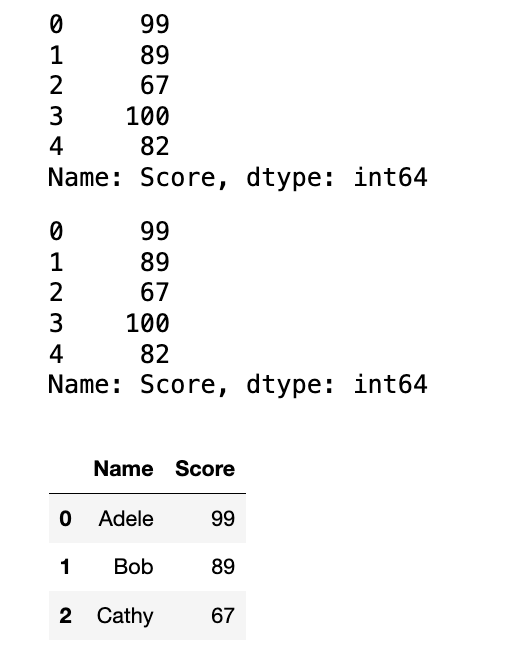
data = {"Name": ["Adele", "Bob", "Cathy", "David", "John"], "Score": [99, 89, 67, 100, 82]}
students = pd.DataFrame(data=data, columns=["Name", "Score"])
display(students["Score"], students.Score)
display(students[:3])
2.标签选择 (.loc)
.loc 是 pandas 中基于标签(label) 进行数据选取的首选方法。它非常强大和灵活,能够同时选择行和列,并且支持单标签、标签列表和标签切片。
- 基本语法:
df.loc[row_label, column_label] - 选择指定行标签的数据:
df.loc['Label']:选择单行,返回一个 Series。df.loc[['Label1', 'Label2']]:选择多行,传入标签列表,返回一个 DataFrame。
- 根据行标签切片:
df.loc['StartLabel':'EndLabel']:进行行切片,包含起始和结束标签。
- 选择指定列标签的数据:
df.loc[:, 'ColumnLabel']:选择单列,:表示所有行,返回一个 Series。df.loc[:, ['Column1', 'Column2']]:选择多列,返回一个 DataFrame。
- 根据列标签切片:
df.loc[:, 'StartColLabel':'EndColLabel']:进行列切片,包含起始和结束标签。
- 同时进行行和列选择/切片:
df.loc['A':'E', ['Python', 'Keras']]:根据行标签切片,并选择指定列标签。
- 选择标量值:
df.loc['RowLabel', 'ColumnLabel']:选择单个单元格的值。
.loc的核心在于其基于标签的对齐和查找。当您使用.loc时,pandas会在 DataFrame 的索引和列中精确匹配您提供的标签。这种明确的标签引用避免了整数位置可能带来的混淆(例如,当数据被重新排序或插入时,整数位置会改变,但标签不会)。与基本索引的行切片不同,
.loc进行的标签切片(例如df.loc['A':'E'])通常也返回原始 DataFrame 的视图。但是,当您进行更复杂的复合操作时,例如选择非连续的行或列,pandas可能会返回一个副本。为了安全起见,在进行赋值操作时,始终使用.loc或.iloc的单次调用,并避免链式赋值。
.loc 也支持布尔条件进行行选择,这使得数据筛选非常强大: df.loc[df['Python'] > 100, ['Python', 'Keras']]:选择 Python 分数大于 100 的所有行,并只显示 ‘Python’ 和 ‘Keras’ 列。
【1】选取指定行标签
1
2
3
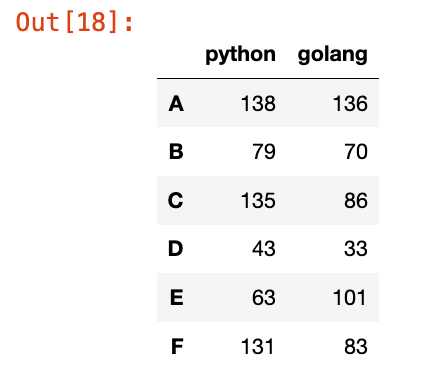
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, columns=["python", "java", "golang"], index=list("ABCDEFGHIJ"))
df.loc[["A", "C", "F"]]

【2】根据行标签切片,选取指定列标签:
1
df.loc["A":"F", ["python", "golang"]]
【3】保留所有行,选择指定的列:
1
df.loc[:, ["java", "golang"]]

【4】行切片+列切片:
1
df.loc["A":"E", "java":"golang"]

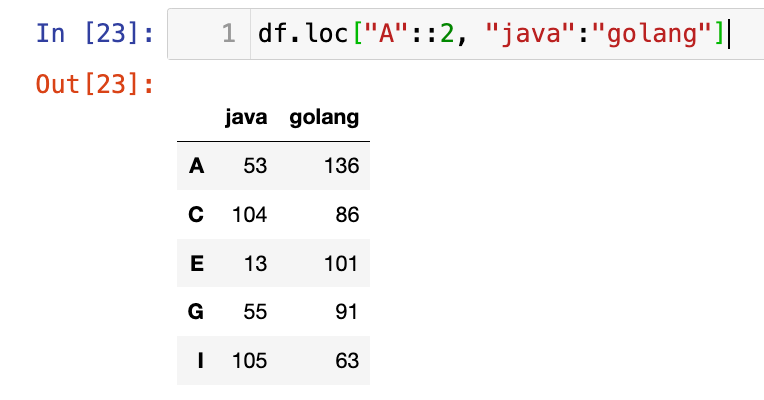
也可以指定步长:
1
df.loc["A"::2, "java":"golang"]
【5】选取标量值:
1
df.loc["G", "golang"]

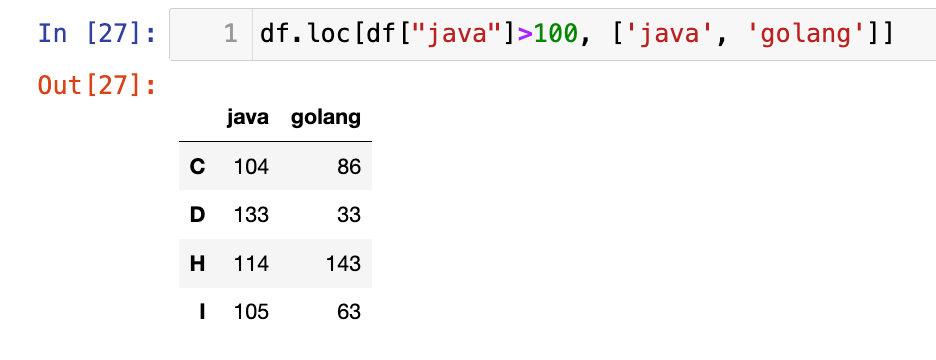
【6】布尔条件:
1
df.loc[df["java"]>100, ['java', 'golang']]
选择题
-
给定
df = pd.DataFrame({'A': [10, 20], 'B': [30, 40]}, index=['X', 'Y']),以下哪个操作会返回20?A.
df.loc['Y', 'A']B.
df.loc[1, 0]C.
df.loc['A', 'Y']D.
df.iloc['Y', 'A']答案:A
-
使用
.loc进行标签切片时,例如df.loc['start_label':'end_label'],'end_label'是否包含在结果中?A. 包含
B. 不包含
C. 取决于数据类型
D. 报错
答案:A
编程题
- 创建一个 DataFrame
students_grades,行索引为学生姓名(例如['Alice', 'Bob', 'Charlie']),列索引为科目(例如['Math', 'Science', 'History']),并填充随机分数。 - 使用
.loc选取Alice和Charlie的Math和History成绩。 - 使用
.loc选取Bob的Science成绩。 - 使用
.loc选取Math成绩大于 80 的所有学生的全部科目成绩。
1
2
3
4
5
data = np.random.randint(0, 101, (3, 3))
df = pd.DataFrame(data=data, index=["Alice", "Bob", "Charlie"], columns=["Math", "Science", "History"])
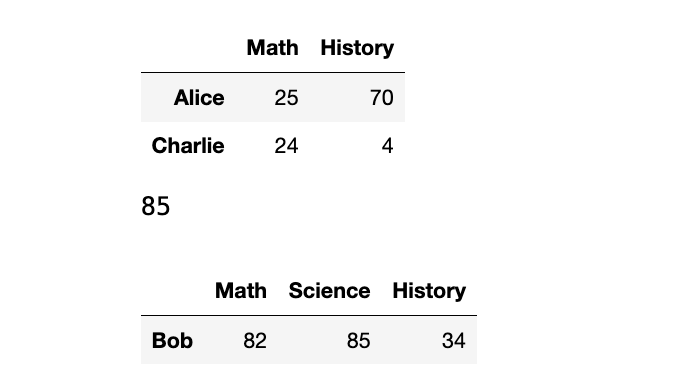
display(df.loc[["Alice","Charlie"], ["Math", "History"]])
display(df.loc["Bob", "Science"])
display(df.loc[df.Math > 80])
3.位置选择 (.iloc)
.iloc 是 pandas 中基于整数位置(integer-location) 进行数据选取的首选方法。它的行为与 NumPy 数组和 Python 列表的索引和切片非常相似。
- 基本语法:
df.iloc[row_index, column_index] - 选择指定行位置的数据:
df.iloc[i]:选择第i行(从 0 开始计数),返回一个 Series。df.iloc[[i1, i2]]:选择多行,传入整数位置列表,返回一个 DataFrame。
- 根据整数位置切片:
df.iloc[start_idx:end_idx]:进行行切片,左闭右开,不包含end_idx。
- 选择指定列位置的数据:
df.iloc[:, j]:选择第j列,:表示所有行,返回一个 Series。df.iloc[:, [j1, j2]]:选择多列,传入整数位置列表,返回一个 DataFrame。
- 根据整数位置切片:
df.iloc[:, start_col_idx:end_col_idx]:进行列切片,左闭右开。
- 同时进行行和列选择/切片:
df.iloc[2:8, 0:2]:行切片从索引 2 到 7,列切片从索引 0 到 1。
- 选择标量值:
df.iloc[row_idx, col_idx]:选择单个单元格的值。
.iloc直接操作 DataFrame 的底层 NumPy 数组结构,通过计算内存偏移量来访问数据。它不关心行或列的标签,只关心它们在内部存储中的整数位置。这使得.iloc在需要基于位置进行批量操作时非常高效。与
.loc类似,.iloc进行的切片操作通常也返回原始 DataFrame 的视图。但当选择非连续的行或列时,可能会返回副本。在赋值操作时,同样推荐使用.iloc的单次调用。
df.iloc 的行为与 NumPy 数组的索引非常一致,这使得熟悉 NumPy 的用户能够快速上手。例如,df.iloc[0, 0] 类似于 np_array[0, 0]。
【1】用整数位置选择:
1
2
3
4
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, columns=["Python", "java", "golang"], index=list("ABCDEFGHIJ"))
display(df)
df.iloc[4] # 从0开始

【2】用整数切片:
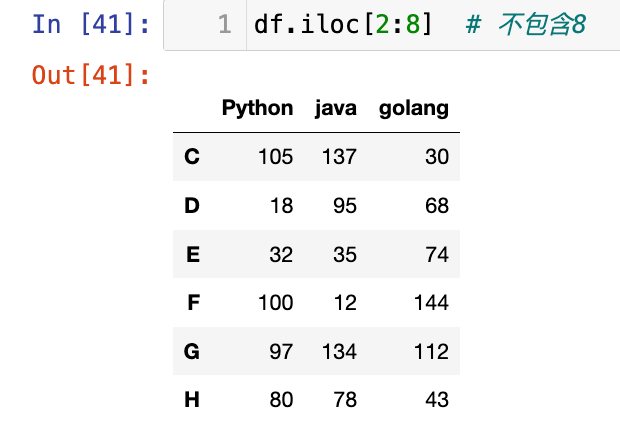
1
df.iloc[2:8] # 不包含8
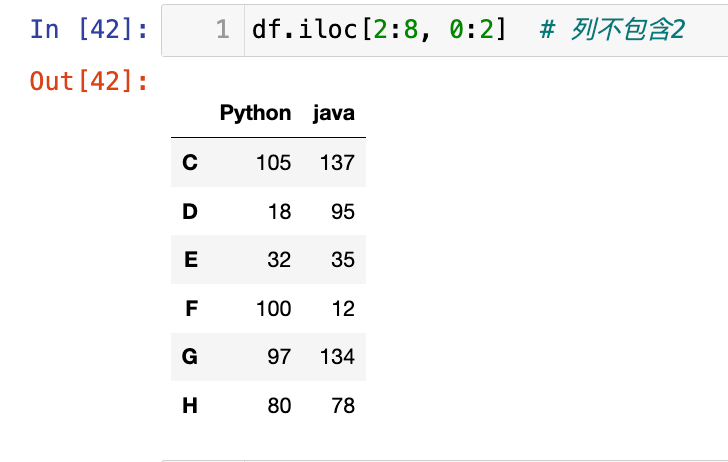
1
df.iloc[2:8, 0:2] # 列不包含2
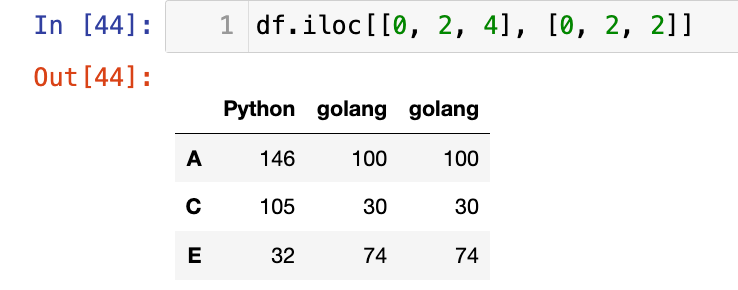
【3】整数列表按位置进行选择:
1
df.iloc[[0, 2, 4], [0, 2, 2]]
【4】行切片和列切片:
1
df.iloc[1:3, :] # 行切片
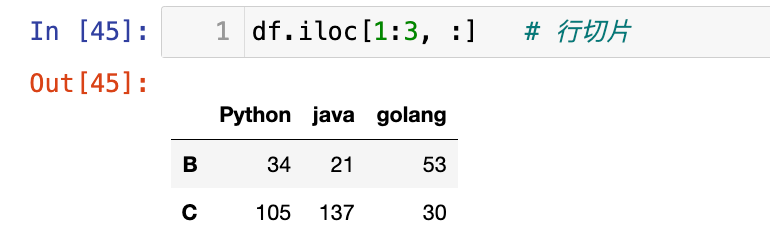
1
df.iloc[:, ::2] # 列切片

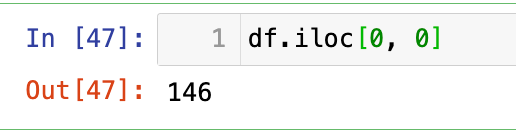
【5】选取标量值
1
df.iloc[0, 0]
选择题
-
给定
df = pd.DataFrame({'A': [10, 20], 'B': [30, 40]}, index=['X', 'Y']),以下哪个操作会返回40?A.
df.iloc['Y', 'B']B.
df.iloc[1, 1]C.
df.iloc[0, 0]D.
df.loc[1, 1]答案:B,
df.iloc使用整数位置(integer location)索引,而不是标签。df.loc使用标签索引 -
使用
.iloc进行整数位置切片时,例如df.iloc[start_idx:end_idx],end_idx是否包含在结果中?A. 包含
B. 不包含
C. 取决于数据类型
D. 报错
答案:B
编程题
- 创建一个 DataFrame
exam_scores,包含 4 行 3 列的随机整数分数。 - 使用
.iloc选取第 1 行和第 3 行的所有列。 - 使用
.iloc选取所有行的第 0 列和第 2 列。 - 使用
.iloc选取第 2 行第 1 列的单个元素。
1
2
3
4
5
6
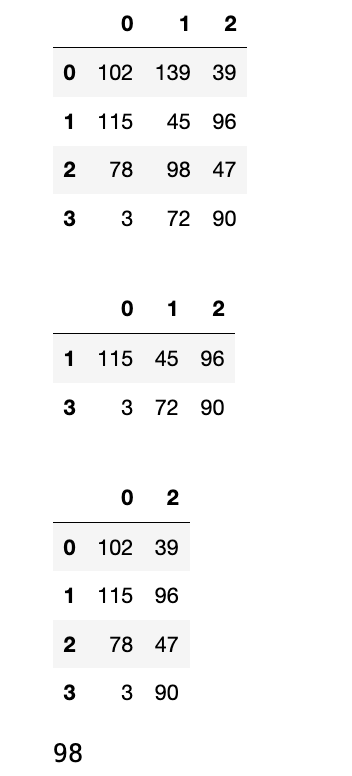
data = np.random.randint(0, 151, (4, 3))
df = pd.DataFrame(data=data)
display(df)
display(df.iloc[[1, 3],:])
display(df.iloc[:, [0, 2]])
display(df.iloc[2, 1])
4.布尔索引
布尔索引(Boolean Indexing)是一种非常强大和灵活的数据筛选方式。它允许您使用一个布尔 Series 或 DataFrame 作为索引,来选择满足特定条件的行或元素。
- 基本原理: 传入一个与 DataFrame 行数相同(或可广播)的布尔 Series。布尔 Series 中值为
True的位置对应的 DataFrame 行会被选中,False的行则被过滤掉。 - 创建布尔 Series: 最常见的方式是使用比较运算符(
>,<,==,!=,>=,<=)对 DataFrame 的某一列进行操作。例如df.Python > 100会返回一个布尔 Series。 - 多条件组合:
&(与运算):所有条件都为True时才为True。|(或运算):任一条件为True时即为True。~(非运算):对布尔 Series 进行取反。- 重要提示: 在
pandas中进行布尔运算时,必须使用位运算符&,|,~,而不是 Python 的逻辑运算符and,or,not。同时,每个条件表达式需要用括号括起来,以确保正确的运算优先级。
- 选择 DataFrame 中满足条件的值:
df[df > value]:传入一个与 DataFrame 形状相同的布尔 DataFrame。满足条件的元素会保留其值,不满足条件的元素会被替换为NaN。
isin()方法:df.index.isin(list_of_labels):判断 DataFrame 的行索引是否在给定的列表中。返回一个布尔 Series。df['Column'].isin(list_of_values):判断某一列的值是否在给定的列表中。返回一个布尔 Series
布尔索引的底层机制是创建了一个“掩码”(mask)。这个掩码是一个布尔数组,它指示了哪些数据点应该被保留。
pandas然后使用这个掩码来过滤数据。与
.loc或.iloc的切片不同,布尔索引通常会返回原始 DataFrame 的副本。这是因为被选择的行或元素在内存中可能不是连续的,为了构建一个新的连续的 DataFrame,pandas需要复制数据。
布尔索引是数据清洗和条件分析的基石。例如:
- 筛选异常值:
df[df['sales'] < 0]找出负销售额。 - 条件赋值:
df[df['score'] < 60] = 0将不及格分数设为 0。 - 缺失值处理:
df[df['column'].isnull()]找出包含缺失值的行。
【1】基本布尔索引
1
2
3
4
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "CPP"])
cond1 = df.python > 100
df[cond1]

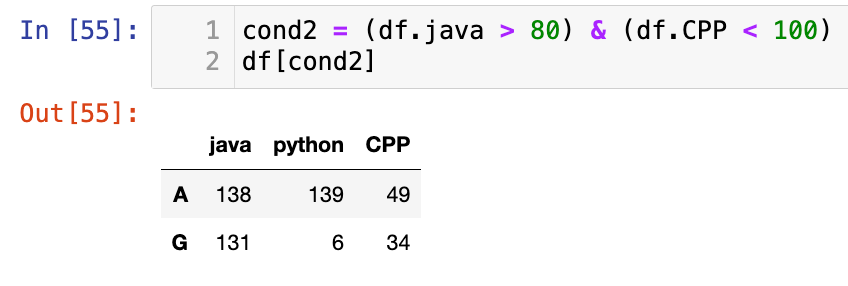
【2】多条件组合
1
2
cond2 = (df.java > 80) & (df.CPP < 100)
df[cond2]
【3】不满足条件赋值为NaN
1
2
3
4
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "CPP"])
df.loc[df["CPP"] < 50, "CPP"] = np.nan
df

上面的例子用where也可以:
1
2
3
4
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "CPP"])
df["CPP"] = df["CPP"].where(df["CPP"] >= 50, np.nan)
df
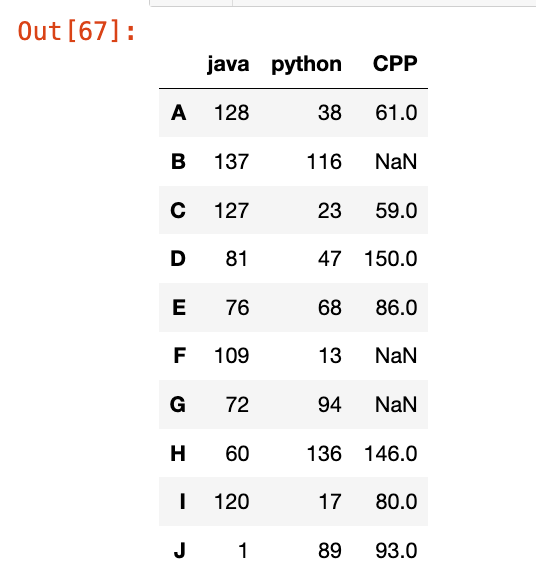
【4】判断某一列的值是否在列表中:
1
df[df["python"].isin(range(90, 131))]
选择题
-
给定
df = pd.DataFrame({'A': [10, 20, 30], 'B': [5, 15, 25]}),以下哪个表达式会返回A列大于15且B列小于20的行?A.
df[(df['A'] > 15) and (df['B'] < 20)]B.
df[(df['A'] > 15) & (df['B'] < 20)]C.
df[df['A'] > 15 & df['B'] < 20]D.
df.loc[df['A'] > 15 and df['B'] < 20]答案:B,and 是 Python 的逻辑运算符,用于标量布尔值运算,而不是 pandas 的逐元素运算。
-
如果
df是一个 DataFrame,df[df['Column'] > 10]的结果是什么类型?A. Series
B. NumPy
ndarrayC. DataFrame
D. 布尔 Series
答案:C
编程题
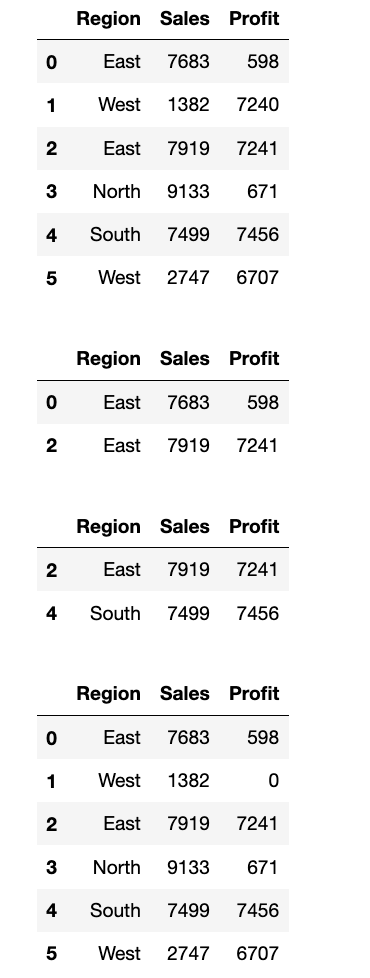
- 创建一个 DataFrame
sales_data,包含'Region'(地区),'Sales'(销售额),'Profit'(利润) 三列,以及 6 行数据。Region包含'East','West','East','North','South','West'。Sales和Profit填充随机整数。
- 使用布尔索引:
- 筛选出
'Region'为'East'的所有销售记录。 - 筛选出
'Sales'大于 5000 且'Profit'大于 1000 的销售记录。 - 将所有
'Sales'小于 2000 的记录的'Profit'设置为 0。
- 筛选出
- 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
region = ["East", "West", "East", "North", "South", "West"]
col = ["Region", "Sales", "Profit"]
data = {"Region": region, "Sales": np.random.randint(0, 10000, (6,)), "Profit": np.random.randint(100, 10000, (6, ))}
sales_data = pd.DataFrame(data = data, columns=col)
display(sales_data)
# 筛选出 `'Region'` 为 `'East'` 的所有销售记录
display(sales_data[sales_data["Region"] == "East"])
# 筛选出 `'Sales'` 大于 5000 且 `'Profit'` 大于 1000 的销售记录。
display(sales_data[(sales_data["Sales"] > 5000) & (sales_data["Profit"] > 1000)])
# 将所有 `'Sales'` 小于 2000 的记录的 `'Profit'` 设置为 0。
sales_data.loc[sales_data["Sales"] < 2000, "Profit"] = 0
display(sales_data)
5.赋值操作
在 pandas 中,数据选取和赋值是紧密结合的。您可以使用各种索引器(如 [], .loc, .iloc)来选择数据的子集,然后直接对其进行赋值操作。
- 添加新列:
df['NewColumn'] = value:为 DataFrame 添加一个新列。value可以是标量(所有行填充相同值)、列表、NumPy 数组或 Series。如果value是 Series,pandas会根据行索引自动对齐数据,不匹配的索引位置将填充NaN。
- 按标签赋值:
df.loc['RowLabel', 'ColumnLabel'] = value:为单个单元格赋值。df.loc['RowLabel', ['Col1', 'Col2']] = [val1, val2]:为指定行的多个列赋值。df.loc[['Row1', 'Row2'], 'ColumnLabel'] = value:为指定列的多个行赋值。df.loc[row_slice, col_slice] = value:为标签切片区域赋值。
- 按位置赋值:
df.iloc[row_idx, col_idx] = value:为单个单元格赋值。df.iloc[row_slice, col_slice] = value:为位置切片区域赋值。
- 按 NumPy 数组进行赋值:
df.loc[:, 'ColumnName'] = np_array:将 NumPy 数组赋值给整个列。np_array的长度必须与列的行数匹配。
- 按条件赋值(布尔赋值):
df[condition] = value:将满足condition的所有元素替换为value。df.loc[condition, 'ColumnName'] = value:将满足condition的特定列的元素替换为value。df[condition_df] = value:传入一个布尔 DataFrame,将其中为True的位置替换为value。
pandas的赋值操作在底层会进行数据对齐和广播。当您赋值一个标量时,它会被广播到所有选定的位置。当赋值一个 Series 或 NumPy 数组时,pandas会尝试根据索引或位置进行对齐。
SettingWithCopyWarning 当对 DataFrame 的一个视图进行操作,并且这个操作可能导致修改原始数据时,pandas 可能会发出 SettingWithCopyWarning。这通常发生在链式索引中,例如 df[df['col'] > 0]['another_col'] = value。为了避免这个问题,并确保您修改的是原始 DataFrame,始终使用 .loc 或 .iloc 的单次调用进行赋值,例如 df.loc[df['col'] > 0, 'another_col'] = value。
【1】添加新的列:
1
2
3
4
5
6
data = np.random.randint(0, 151, (10, 3))
df = pd.DataFrame(data=data, index=list("ABCDEFGHIJ"), columns=["java", "python", "golang"])
display(df)
data_cpp = pd.Series(np.random.randint(0, 151, (9, )), name="cpp", index=list("ABCDEFGHI"))
df["cpp"] = data_cpp
display(df)
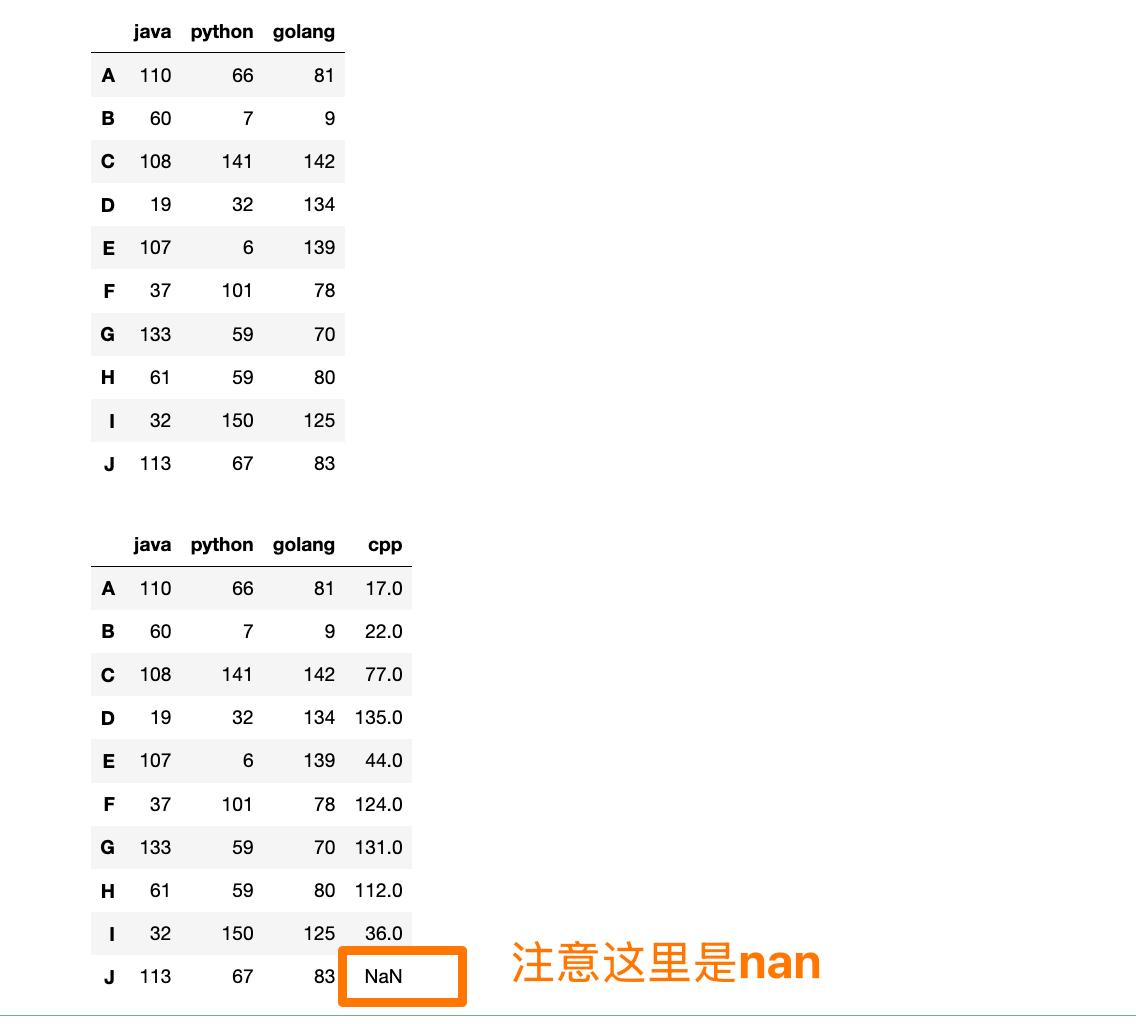
【2】按标签赋值:
1
2
df.loc["A", "python"] = 200
df

【3】按照位置赋值:
1
2
df.iloc[0, 0] = 999
df
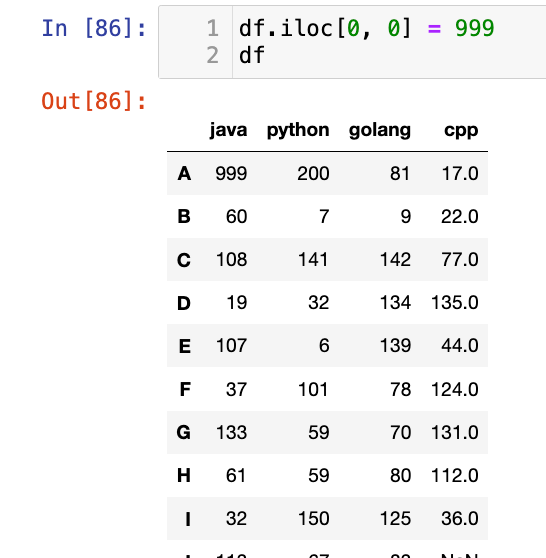
【4】用numpy数据进行赋值:
1
2
3
# python整一列设置为128
df.loc[:, "python"] = np.array([128]*10)
df
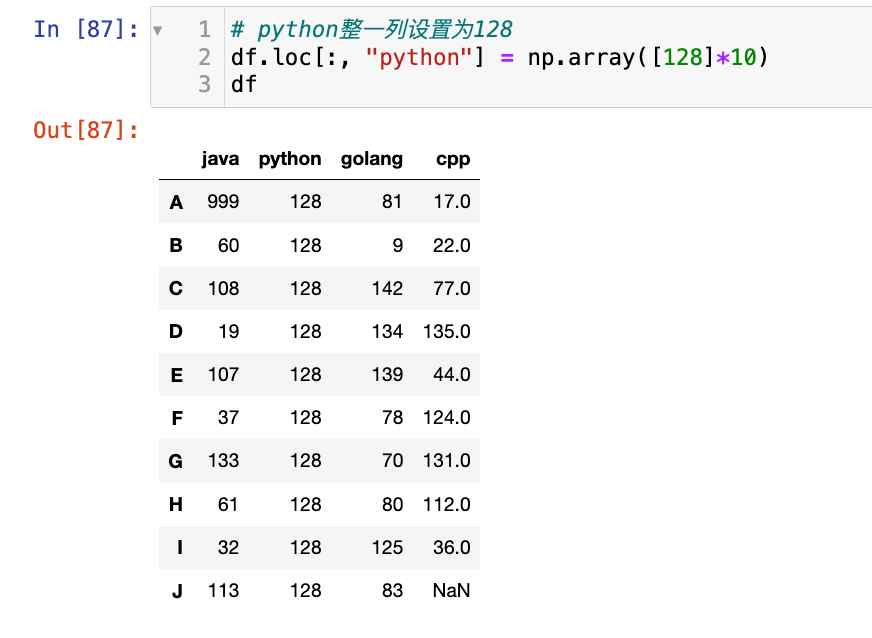
其实还有更加简单的写法:
1
2
df["python"] = 90
df
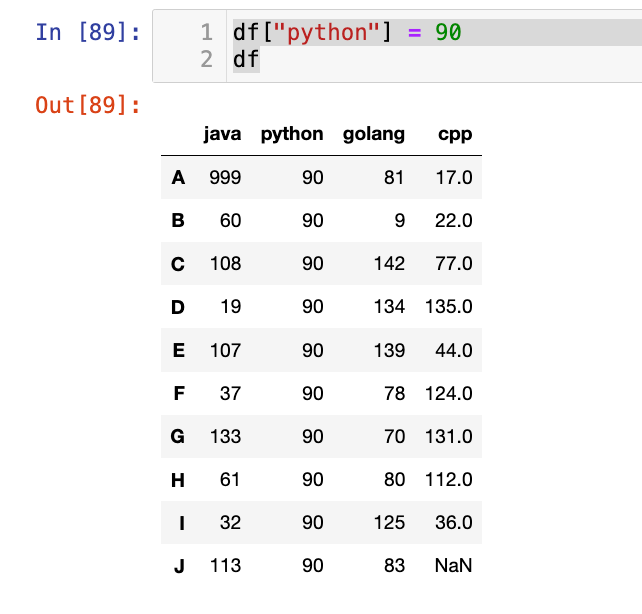
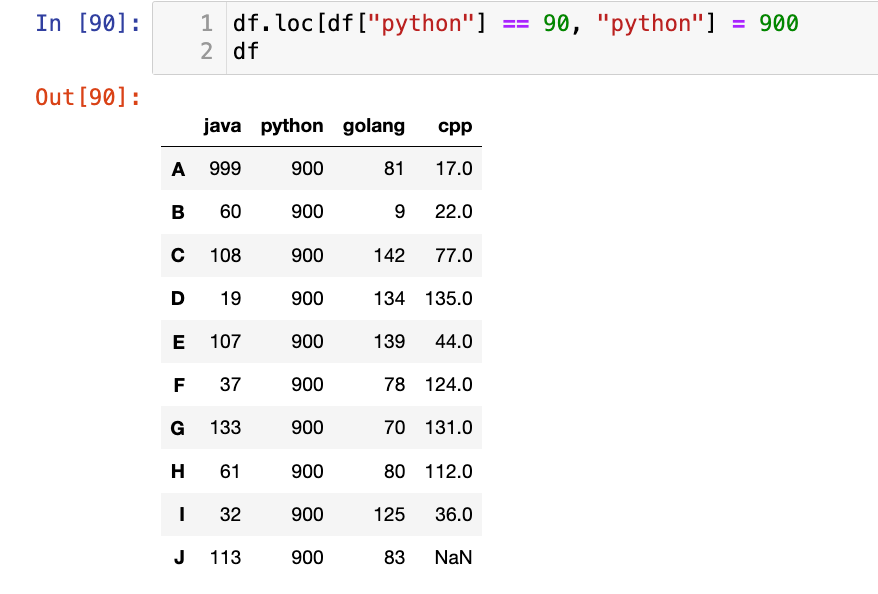
【5】按照条件进行赋值:
1
2
df.loc[df["python"] == 90, "python"] = 900
df
选择题
-
给定
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}),执行df['C'] = 10后,df的形状是什么?A.
(2, 2)B.(2, 3)C.(3, 2)D.(3, 3)答案:B
-
以下哪种赋值操作最可能导致
SettingWithCopyWarning?A.
df.loc[row_label, col_label] = valueB.
df.iloc[row_idx, col_idx] = valueC.
df[df['col'] > 0]['another_col'] = valueD.
df['new_col'] = new_series答案:C,首先,
df[df['col'] > 0] 通过布尔索引返回一个子集(可能是一个视图或副本,取决于 pandas 的内部实现)。对这个子集的列
['another_col']进行赋值,pandas 无法确定是否在修改原始 DataFrame 的子集视图,可能会触发SettingWithCopyWarning。
编程题
- 创建一个 DataFrame
employees,包含'Name','Department'两列和 5 行数据。 - 为
employeesDataFrame 添加一列'Salary',并使用随机整数填充。 - 将
'Department'为'HR'的所有员工的'Salary'增加 10%。 - 将
'Name'为'Alice'的员工的'Department'修改为'Marketing'。 - 打印每一步操作后的 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
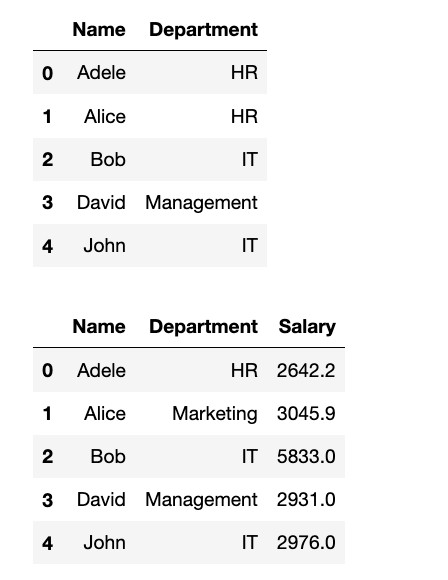
names = ["Adele", "Alice", "Bob", "David", "John"]
dept = ["HR", "HR", "IT", "Management", "IT"]
salary_data = np.random.randint(2000, 8000, (5, ))
data = {"Name": names, "Department": dept}
employees = pd.DataFrame(data=data, columns=["Name", "Department"])
display(employees)
# 为 `employees` DataFrame 添加一列 `'Salary'`,并使用随机整数填充。
employees["Salary"] = salary_data
# 将 `'Department'` 为 `'HR'` 的所有员工的 `'Salary'` 增加 10%。
# 防止告警:FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas
# 修改salary这一列的数据类型:int-->float
employees["Salary"] = employees["Salary"].astype(float)
employees.loc[employees["Department"] == "HR", "Salary"] = employees["Salary"] * 1.1
# 将 `'Name'` 为 `'Alice'` 的员工的 `'Department'` 修改为 `'Marketing'`。
employees.loc[employees["Name"] == "Alice", "Department"]= "Marketing"
display(employees)