pandas数据输入与输出。
1.CSV
CSV (Comma-Separated Values) 是一种以纯文本形式存储表格数据的格式。它是数据交换最常用的格式之一。pandas 提供了强大的函数来读写 CSV 文件。
df.to_csv(path_or_buf, sep, header, index): 将 DataFrame 保存为 CSV 文件。sep: 指定列之间的分隔符,默认为逗号。header: 布尔值,是否在文件中包含列索引(列名),默认为True。index: 布尔值,是否在文件中包含行索引,默认为True。
pd.read_csv(path_or_buf, sep, header, index_col): 从 CSV 文件中读取数据并创建 DataFrame。sep: 指定分隔符。header: 指定哪一行作为列索引,例如header=0使用第一行。index_col: 指定哪一列作为行索引。
当 pandas 读取 CSV 文件时,它会高效地解析每一行,并根据分隔符将数据分割成字段。然后,它会尝试推断每一列的数据类型。如果某些列包含非数值数据,pandas 会将其数据类型设置为
object。通过在读写时正确设置header和index参数,可以确保数据的结构和内容得到准确的保存和恢复。
1
2
3
4
5
6
7
8
9
10
11
12
# 创建一个50*5的df
data = np.random.randint(0, 50, (50, 5))
columns = ["IT", "化学", "生物", "经济", "土木"]
df = pd.DataFrame(data=data, columns=columns)
# 保存,指定分隔符是;
df.to_csv("salary.csv", sep=";")
print("已保存df到salary.csv")
# 加载数据
# header=0使用第一行作为列索引
# index_col=0 使用数据的第一列(之前保存的行索引)作为新的行索引
df_load = pd.read_csv("./salary.csv", sep=";", header=0, index_col=0)
df_load

保存的csv:
1
2
3
4
5
6
7
8
# 创建一个50*5的df,但是指定存储的分隔符是制表符\t
data = np.random.randint(0, 50, (50, 5))
columns = ["IT", "化学", "生物", "经济", "土木"]
df = pd.DataFrame(data=data, columns=columns)
df.to_csv("salary1.csv", sep="\t")
# read_table默认的分隔符就是制表符,所以这里不指定参数sep
data_load_table = pd.read_table("salary1.csv", header = 0, index_col = 0)
data_load_table
使用制表符存储的csv:

选择题
-
如果一个 DataFrame 在保存到 CSV 时,设置了
index=False,但在读取时,没有指定index_col,会发生什么?A. 报错。 B. DataFrame 会自动生成一个默认的整数行索引。 C. DataFrame 会将文件的第一列作为行索引。 D. DataFrame 会将第一行作为列索引。
答案:B ,
pd.read_csv默认不会将任何列作为索引。如果文件中没有索引列,它会自动分配一个0到n-1的整数索引。1 2 3 4 5 6 7 8 9 10 11 12
# 创建一个50*5的df data = np.random.randint(0, 50, (50, 5)) columns = ["IT", "化学", "生物", "经济", "土木"] df = pd.DataFrame(data=data, columns=columns) # 保存,指定分隔符是; df.to_csv("salary.csv", sep=";", index = False) print("已保存df到salary.csv") # 加载数据 # header=0使用第一行作为列索引 # index_col=0 使用数据的第一列(之前保存的行索引)作为新的行索引 df_load = pd.read_csv("./salary.csv", sep=";", header=0) df_load

-
以下哪项是
pd.read_csv()函数的默认行为?A. 使用分号
;作为分隔符。 B. 将第一行作为列索引。 C. 不保留任何行索引。 D. 自动将第一列作为行索引。答案:B
编程题
- 创建一个 DataFrame,包含两列
'Product'和'Price',以及三行数据。 - 将该 DataFrame 保存到名为
'products.csv'的文件中,不包含行索引和列索引。 - 使用
pd.read_csv()重新加载该文件,并手动指定列名为'Product'和'Price'。打印结果。
1
2
3
4
5
6
data = {"Product": ["Apple", "Banana", "Orange"], "Price": [19.8, 20.8, 12.9]}
df = pd.DataFrame(data= data, columns=["Product", "Price"])
display(df)
df.to_csv("products.csv", index=False)
df_load = pd.read_csv("products.csv", header=0)
df_load
2.Excel
与 CSV 相比,Excel 文件格式更加复杂,通常一个文件包含多个工作表。pandas 使用专门的库来读写 Excel 文件。在读写 Excel 文件之前,需要根据文件格式安装相应的库:
.xls(旧格式):pip install xlrd和pip install xlwt.xlsx(新格式):pip install openpyxldf.to_excel(excel_writer, sheet_name, header, index): 将 DataFrame 保存到 Excel 文件。sheet_name: 指定工作表的名称,默认为Sheet1。
pd.read_excel(io, sheet_name, header, names, index_col): 从 Excel 文件中读取数据。sheet_name: 指定要读取的工作表,可以按名称或索引(从 0 开始)指定。names: 用于替换列索引的列表。header: 指定哪一行作为列索引。
pd.ExcelWriter(): 一个上下文管理器,用于在同一个 Excel 文件中保存多个工作表。
【特别注意】文件格式差异
-
.xls:-
.xls是较旧的 Microsoft Excel 文件格式(Excel 97-2003 格式),使用二进制格式(BIFF,Binary Interchange File Format)。 -
pandas 支持
.xls文件,但需要安装 xlwt 库(用于写入 .xls 文件)或 xlrd 库(用于读取.xls文件)。 -
如果系统中未安装 xlwt,调用
df.to_excel("df.xls")会抛出错误,例如:1
ImportError: No module named 'xlwt'
或类似错误,表示缺少必要的库来支持
.xls文件写入。
-
-
.xlsx:.xlsx是较新的 Microsoft Excel 文件格式(Excel 2007 及以上,基于 Office Open XML 标准),使用 XML 格式。- pandas 默认使用 openpyxl 库(或 xlsxwriter 库)来处理
.xlsx文件的读写。 - 现代 Python 环境中,openpyxl 通常是默认安装的(或通过 pip install openpyxl 安装),因此
df.to_excel("df.xlsx")通常不会报错。
总结:如果环境中安装了 openpyxl 但未安装 xlwt,那么写 .xlsx 文件会成功,而写 .xls 文件会失败,因为缺少 xlwt 库。
pandas 的 Excel 读写功能是一个重要的桥梁,连接了常见的数据分析工具和业务中广泛使用的 Excel 格式。
pd.ExcelWriter允许 pandas 像数据库一样管理 Excel 文件,将不同的 DataFrame 写入不同的工作表,这在组织复杂项目的数据时非常有用。它在底层处理 Excel 文件的复杂二进制结构,让用户可以像处理 CSV 一样方便地操作数据。
安装必要的库:

重启内核。
【1】存储读取单个工作表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
import pandas as pd
data = np.random.randint(0, 50, (50, 5))
df = pd.DataFrame(data=data, columns=["IT", "生物", "材料", "化学", "环境"])
data2 = np.random.randint(0, 150, (50, 3))
df2 = pd.DataFrame(data=data2, columns=["Python", "Java", "Golang"])
display(df.head(3), df2.head(3))
# 保存单个工作表
# header=True 将列名作为第一行写入(默认行为)
# index=False 表示不写入索引列,生成的 Excel 文件只包含 DataFrame 的数据列
df.to_excel("df.xlsx", sheet_name="aaa", header=True, index=False)
print("已经保存到excel")
# 加载数据
# sheet_name=0 表示读取第一个工作表(基于 0 索引)。
# 如果 Excel 文件有多个工作表,可以通过索引(整数)或工作表名称(字符串)指定。
# header=0 表示将 Excel 文件的第一行(基于 0 索引,即实际的第一行)作为 DataFrame 的列名
# index_col=0 表示将 Excel 文件的第一列(基于 0 索引,即实际的第1列)作为 DataFrame 的索引列。
df_load_excel = pd.read_excel("df.xlsx", sheet_name=0, header=0 ,index_col=0 )
display(df_load_excel.head(4))
注意:存储时,因为指定了index=False,所以不会写入索引列,那么读取时index_col=0就会使得IT列作为了索引列。
【2】保存多个工作表:
1
2
3
4
5
6
7
8
9
10
11
display(df.head(3), df2.head(3))
# 保存到多个工作表
# 使用上下文管理器
with pd.ExcelWriter("data.xlsx") as writer:
# 默认header和index都是True
df.to_excel(writer, sheet_name="111", index=True)
df2.to_excel(writer, sheet_name="222", index=True)
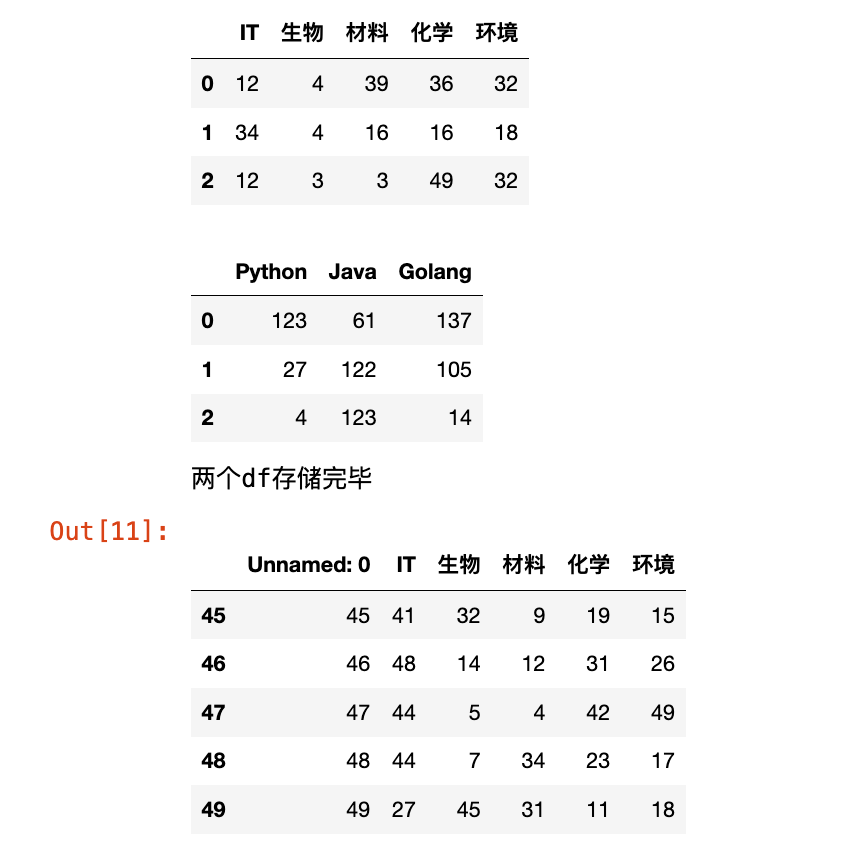
print("两个df存储完毕")
# 读取
df_data_1 = pd.read_excel("data.xlsx", sheet_name="111")
df_data_1.tail(5)
选择题
-
要将一个 DataFrame 写入一个名为
'data.xlsx'的 Excel 文件,并确保其在第二个工作表中,以下哪个方法是正确的?A.
df.to_excel('data.xlsx', sheet_name=1)B.
df.to_excel('data.xlsx', sheet_name='Sheet2')C. 以上皆可。
D.
df.to_excel('data.xlsx', sheet_index=1)答案:C。
sheet_name可以是索引或名称。 -
pd.read_excel()函数中的names参数有什么作用?A. 指定要读取的工作表名称。
B. 替换行索引。
C. 替换列索引。
D. 指定文件的名称。
答案:C,看下面的例子:
1 2 3 4 5 6 7 8
data = {"ID": [10, 20, 30], "Name": ["Adele", "Bob", "David"], "City": ["北京", "上海", "杭州"]} df = pd.DataFrame(data=data) df.head(3) # 存储至excel df.to_excel("df_test.xlsx") print("df存储成功") data_read = pd.read_excel("df_test.xlsx", names=["列0", "列1", "列2"], sheet_name=0) data_read.head(2)

编程题
- 创建两个 DataFrame,
df_sales(包含'Product','Quantity')和df_expenses(包含'Category','Amount')。 - 使用
pd.ExcelWriter()将这两个 DataFrame 分别保存到'report.xlsx'文件的'Sales'和'Expenses'工作表中。 - 编写代码验证
'Expenses'工作表是否成功保存。
1
2
3
4
5
6
7
8
9
10
11
data = np.random.randint(0, 50, (3, 2))
data2 = np.random.randint(0, 30, (3, 2))
df_sales = pd.DataFrame(data=data, columns=["Product", "Quantity"])
df_expenses = pd.DataFrame(data=data2, columns=["Category", "Amount"])
display(df_sales.head(2), df_expenses.head(2))
with pd.ExcelWriter("test.xlsx") as w:
df_sales.to_excel(w, sheet_name="Sales", index=False)
df_expenses.to_excel(w, sheet_name="Expenses", index=False)
# 读取Expenses
load_enpenses = pd.read_excel("test.xlsx", sheet_name="Expenses")
load_enpenses

3.SQL

pandas 可以通过 SQLAlchemy 和其他数据库驱动库,直接与各种 SQL 数据库进行交互。这使得从数据库中提取数据(ETL 过程中的 E)和将处理后的数据加载回数据库(L)变得非常方便。
sqlalchemy.create_engine(connection_string): 创建一个数据库连接引擎。连接字符串的格式因数据库类型而异(例如,'mysql+pymysql://user:pass@host/db_name')。df.to_sql(table_name, con, if_exists): 将 DataFrame 的内容作为新表或附加到现有表中写入数据库。table_name: 数据库中的表名。con: 数据库连接引擎。if_exists: 字符串,指定如果表已存在时的行为,可以是'fail'、'replace'或'append'。
pd.read_sql(sql, con, index_col): 从数据库中读取数据并创建 DataFrame。sql: SQL 查询语句。
pandas 不直接与数据库通信,而是通过 SQLAlchemy 这个数据库抽象层。SQLAlchemy 负责处理各种数据库(如 MySQL、PostgreSQL、SQLite 等)之间的差异,为 pandas 提供统一的接口。
to_sql将 DataFrame 转换为 SQL 的INSERT语句并执行,而read_sql将 SQL 查询的结果集转换为 DataFrame。这让数据分析师可以高效地在数据库和内存中的 DataFrame 之间移动数据。
首先需要安装库:sqlalchemy 和 pymysql
1
!pip install sqlalchemy pymysql
然后重启内核.
【1】数据库连接配置的格式:
1
数据库类型+驱动://用户名:密码@主机/数据库名?charset=编码
比如:
1
mysql+pymysql://root:root@localhost/pandas_test_db_1?charset=UTF8MB4
【2】写入数据库与读取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import pymysql
from sqlalchemy import create_engine
data = np.random.randint(0, 151, (150, 3))
df = pd.DataFrame(data=data, columns=["Python", "Java", "golang"])
display(df)
# 数据库连接的配置
try:
conn = create_engine("mysql+pymysql://root:root@localhost/test_pymysql_1?charset=UTF8MB4")
print("数据库连接引擎创建成功!")
# df保存至数据库
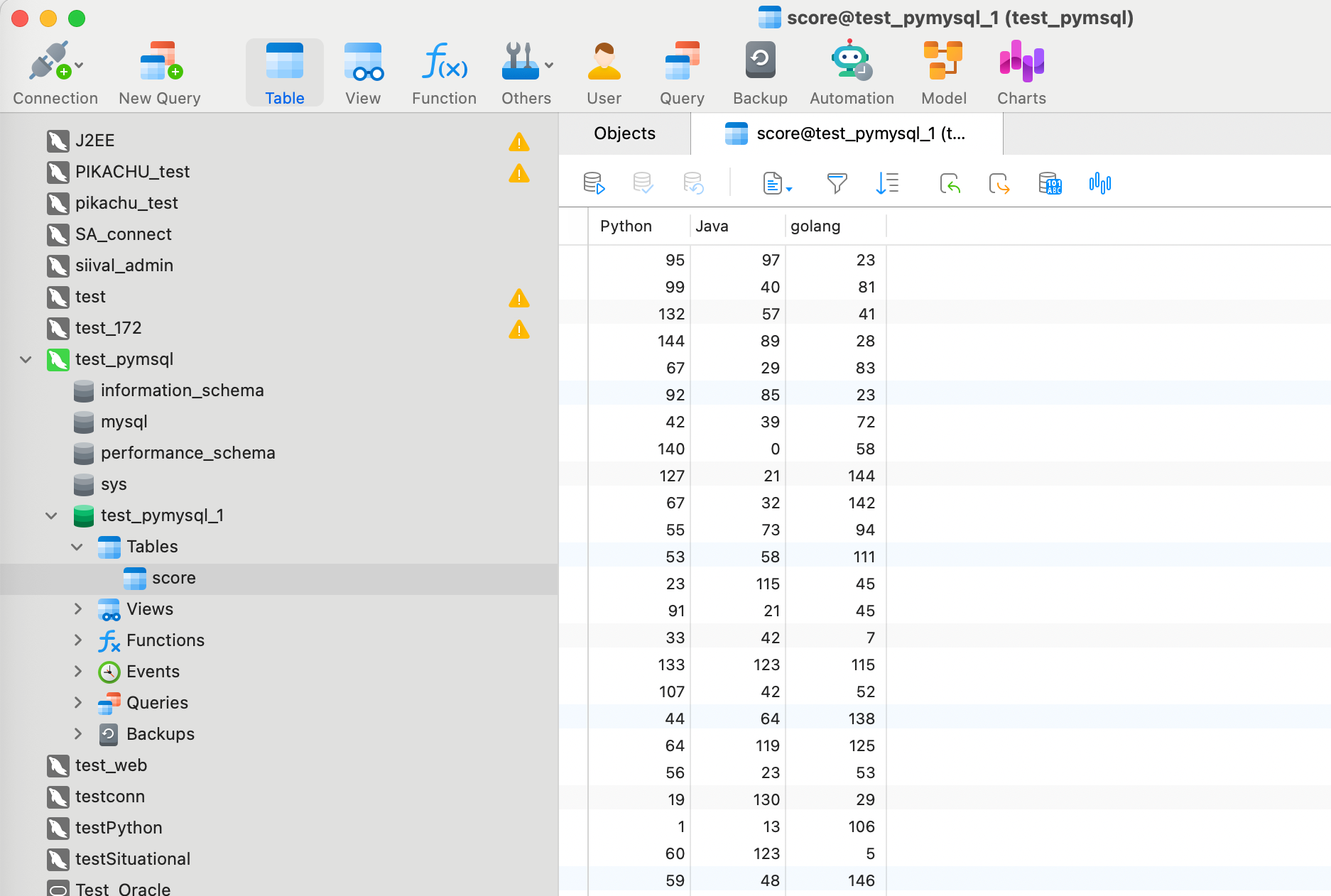
df.to_sql("score", conn, if_exists='append', index=False)
print("已经保至数据库")
# 读取数据
df_load_sql = pd.read_sql("select * from score limit 10", conn, index_col="Python")
display(df_load_sql)
except Exception as e:
print(f"报错:{e}")

数据库中也已经写入了:
选择题
-
在
df.to_sql()中,if_exists='replace'参数的作用是什么?A. 如果表不存在,则创建新表。
B. 如果表已存在,则追加数据。
C. 如果表已存在,则删除旧表并创建新表。
D. 如果表已存在,则报错。
答案:C
-
以下哪项是
pd.read_sql()中sql参数的正确格式?A.
'table_name'B.
'select * from table_name'C.
table_nameD.
select * from table_name答案:B,
read_sql的sql参数需要一个字符串格式的 SQL 查询语句。
4.HDF5

HDF5 (Hierarchical Data Format 5) 是一种专门为存储和管理极大规模、复杂数据集而设计的格式。它的文件后缀通常是 .h5 或 .hdf5。HDF5 的核心优势在于其层次性结构和高效的 I/O 性能,这使得它特别适合处理那些无法一次性加载到内存中的大数据集。
HDF5 文件可以看作是一个文件系统,其中有两个核心概念:
- Group(组): 类似于文件系统中的目录,用于组织和管理数据集。
- Dataset(数据集): 类似于文件系统中的文件,存储实际的数据。
df.to_hdf(path_or_buf, key, mode): 将 DataFrame 保存到 HDF5 文件。key: 一个字符串,用于标识存储在文件中的数据集,类似于文件路径。mode: 指定文件的打开模式,如'w'(写入) 或'a'(追加)。
pd.read_hdf(path_or_buf, key): 从 HDF5 文件中读取数据。key: 指定要读取的数据集的标识符。
pandas 使用
pytables库(需要安装tables)作为后端来读写 HDF5 文件。HDF5 格式允许对数据集进行分块存储和压缩,并且支持只读取数据集的子集,这被称为“分块 I/O”。这种机制使得 pandas 能够高效地处理超出内存大小的数据集,因为它可以按需加载数据块,而不是一次性加载整个文件。key参数则用于在文件的层次结构中定位不同的数据集
【1】确保已安装必要的库tables
【2】存储与读取:
1
2
3
4
5
6
7
8
9
10
11
12
data1 = np.random.randint(0, 51, (50, 5))
df1 = pd.DataFrame(data=data1, columns=["IT", "生物", "化学", "环境", "材料"])
data2 = np.random.randint(0, 151, (150, 3))
df2 = pd.DataFrame(data=data2, columns=["Python", "Tensor flow", "Keras"])
# 保存为HDF5文件
df1.to_hdf("data.h5", key="salary")
df2.to_hdf("data.h5", key="score")
# 读取数据
df_load_hdf5_salary = pd.read_hdf("data.h5", key="salary")
display(df_load_hdf5_salary.head(4))
df_load_hdf5_score = pd.read_hdf("data.h5", key="score")
display(df_load_hdf5_score.head(4))
选择题
-
HDF5 文件中的两个核心概念是?
A. 目录和文件。 B. 组(Group)和数据集(Dataset)。 C. 键(Key)和值(Value)。 D. 索引(Index)和列(Column)。
答案:B
-
以下关于 HDF5 格式的说法,哪一项是正确的?
A. HDF5 是一种纯文本格式。
B. HDF5 不支持在同一个文件中存储多个数据集。
C. HDF5 适合存储和管理无法完全加载到内存中的超大型数据集。
D.
pd.to_hdf()默认使用制表符作为分隔符。答案:C,HDF5 不是纯文本,它是二进制格式,这使其比文本格式更紧凑和高效。
pd.to_hdf()是 pandas 用于将 DataFrame 写入 HDF5 文件的函数。HDF5 是二进制格式,不使用分隔符(如制表符或逗号)来组织数据。pd.to_hdf() 将 DataFrame 存储为 HDF5 的数据集,而不是基于文本的分隔格式(如 CSV)。制表符分隔符的概念适用于 pd.to_csv(),而不是 pd.to_hdf()。
编程题
- 创建一个 DataFrame
df_large,包含 1000 行和 10 列的随机整数。 - 创建一个 DataFrame
df_small,包含 10 行和 2 列的随机整数。 - 将
df_large和df_small分别保存到'datasets.h5'文件中,使用'large_data'和'small_data'作为key。 - 只读取
key为'small_data'的数据集,并打印其形状。
1
2
3
4
5
6
7
8
data1 = np.random.randint(0, 150, (1000, 10))
df_large = pd.DataFrame(data=data1)
data2 = np.random.randint(0, 150, (10, 2))
df_small = pd.DataFrame(data=data2)
df_large.to_hdf("datasets.h5", key="large_data")
df_small.to_hdf("datasets.h5", key="small_data")
df_load_small = pd.read_hdf("datasets.h5", key="small_data")
df_load_small.shape # (10, 2)