在数据科学领域,Python 是最受欢迎的编程语言之一,但它在数据处理和分析方面的原生能力相对有限。pandas 是一个强大的库,它为 Python 补足了这一短板,能够在 Python 中完成从数据清洗、整理到分析、建模的整个工作流程,而无需切换到其他语言,如 R。
pandas 提供了快速、灵活且直观的数据结构,旨在简单地处理各种关系型或标记型数据。它与 Jupyter 等工具以及 NumPy、Matplotlib 和 Scikit-learn 等库协同工作,共同构建了一个高效、强大的数据分析环境。
pandas非常强大,比numpy强大,或者说基于numpy才会有pandas。
pandas 的核心理念是为数据分析提供“表格”状的数据结构,这比原生 Python 的列表或字典更适合处理大规模、异构的数据。这些数据结构在底层是基于高度优化的 NumPy 数组实现的,这意味着它们继承了 NumPy 的快速计算能力。同时,pandas 在 NumPy 的基础上增加了标签索引功能,使得数据操作不再依赖于简单的整数位置,而是可以通过有意义的标签进行,这极大地提高了代码的可读性和健壮性。
在开始之前,确保已经安装了 pandas 库:
1
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
1.数据结构
1.1 Series
Series 是一种一维的、带标签的数据结构,可以看作是带有标签索引的 NumPy 数组。它由两个主要部分组成:数据(values) 和 索引(index)。
- 数据(values): 存储 Series 中的实际数据,可以是任何 NumPy 支持的数据类型。
- 索引(index): 为每个数据点提供标签,可以是整数、字符串或其他可哈希的 Python 对象。如果未指定索引,pandas 会自动生成从
0开始的整数索引。
一个重要的特性是,无论是 NumPy 中的 np.nan 还是原生 Python 的 None,在 pandas 中都会被视为缺失数据,并统一表示为 NaN(Not a Number)。
Series 的强大之处在于其索引。这个索引不仅提供了标签访问的便利,更重要的是,它在多个 Series 或 DataFrame 之间进行算术运算时,能够自动对齐数据。当对两个 Series 进行操作时,pandas 会根据它们的索引标签进行匹配,如果某个标签在其中一个 Series 中缺失,相应位置的计算结果将是
NaN。这种【自动对齐机制】避免了因数据顺序不一致而导致的错误。
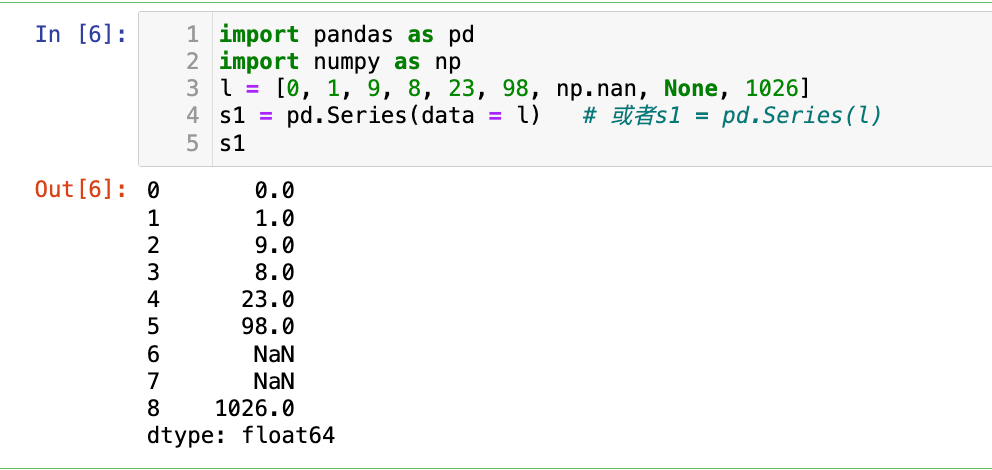
【1】使用列表生成Series,pandas自动添加整数索引。
1
2
3
4
5
import pandas as pd
import numpy as np
l = [0, 1, 9, 8, 23, 98, np.nan, None, 1026]
s1 = pd.Series(data = l) # 或者s1 = pd.Series(l)
s1
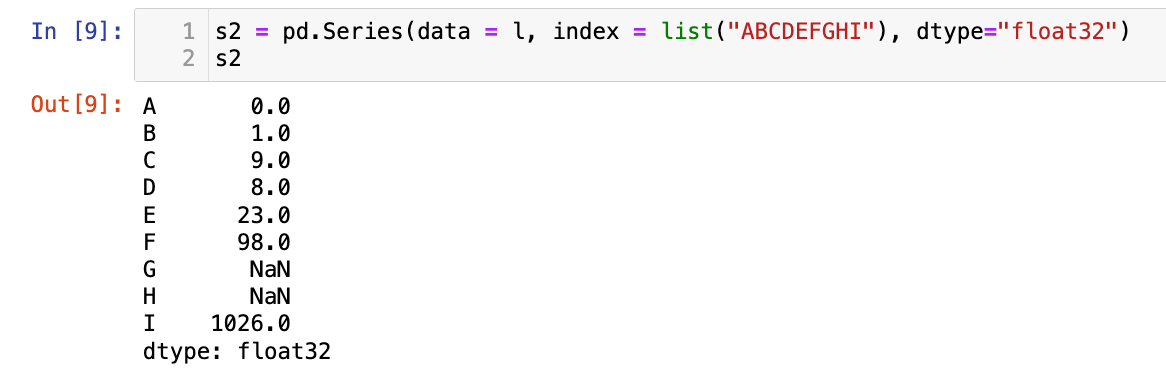
【2】指定行索引和数据类型
1
2
s2 = pd.Series(data = l, index = list("ABCDEFGHI"), dtype="float32")
s2
【3】从字典创建Series,字典的键作为索引
1
2
s3 = pd.Series(data={'a':99, "b": 90, "C":888}, name="Python_score")
s3

【4】索引和切片:
整数索引:
1
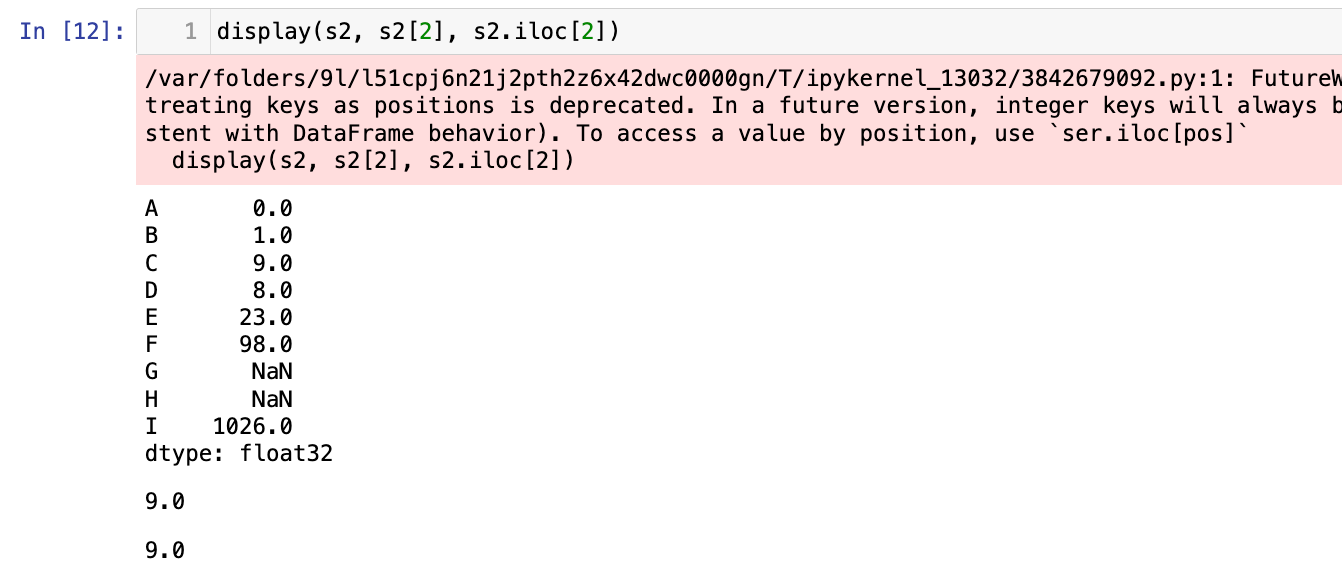
display(s2, s2[2], s2.iloc[2])
现在不推荐
s2[2],更推荐的是s2.iloc[2]写法。
标签索引:

标签切片:(左边右边都包含)

选择题
-
以下关于 pandas Series 和 NumPy 数组的说法,哪一项是错误的?
A. Series 支持带有标签的索引。 B. Series 只能包含同一种数据类型。 C. Series 可以由 NumPy 数组创建。 D. Series 支持自动数据对齐。
答案:B,虽然 Series 通常是同一种类型,但如果包含不同类型的数据(例如整数和字符串),其
dtype将变为object。
-
给定
s = pd.Series([10, 20, 30], index=['a', 'b', 'c']),以下哪种方式会返回一个包含20和30的新 Series?A.
s[1:3]B.s['b':'c']C. A 和 B 都正确。 D. A 和 B 都错误。答案:C,
s[1:3]是整数位置切片,左闭右开,返回索引 1 和 2 的元素。s['b':'c']是标签切片,左闭右闭,返回索引'b'和'c'的元素。
编程题
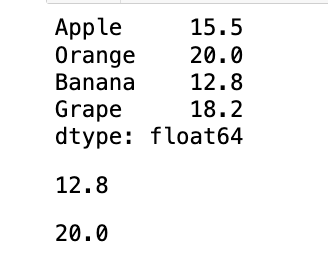
- 创建一个名为
product_prices的 Series,数据为[15.5, 20.0, 12.8, 18.2],索引分别为'Apple','Orange','Banana','Grape'。 - 使用标签索引访问
'Banana'的价格。 - 使用整数位置索引访问
'Orange'的价格。
1
2
product_prices = pd.Series(data=[15.5, 20.0, 12.8, 18.2], index = ["Apple", "Orange", "Banana", "Grape"])
display(product_prices, product_prices["Banana"], product_prices.iloc[1])
1.2 DataFrame
DataFrame 是 pandas 的核心数据结构,它是一个二维的、带标签的数据结构,类似于 Excel 表格、SQL 数据库表,或者是 Series 对象的字典。DataFrame 具有行索引和列索引,这让它非常灵活。
DataFrame 的数据可以由多种类型构成,每一列(column)都可以是不同的数据类型,但一列中的所有数据通常是同一种类型。
DataFrame 在内部可以被看作是一个共享相同行索引的 Series 对象的字典。它的行索引(index) 和 列索引(columns) 提供了双重的标签对齐能力。这种结构使得数据处理和分析变得非常直观:
- 列操作: 您可以像操作字典一样操作 DataFrame 的列,例如
df['column_name']。- 行操作: 您可以使用切片或标签索引来选择行。
- 数据对齐: 当进行操作时,pandas 会同时根据行和列标签进行对齐,确保即使数据顺序或缺失值不同,计算结果也是正确的。
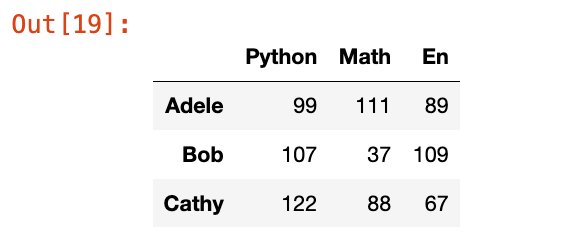
【1】从字典创建DataFrame
1
2
df = pd.DataFrame(data={"Python":[99, 107, 122], "Math":[111, 37, 88], "En":[89, 109, 67]}, index = ["Adele", "Bob", "Cathy"], columns=["Python", "Math", "En"])
df
【2】从numpy数组创建DataFrame:
1
2
3
4
5
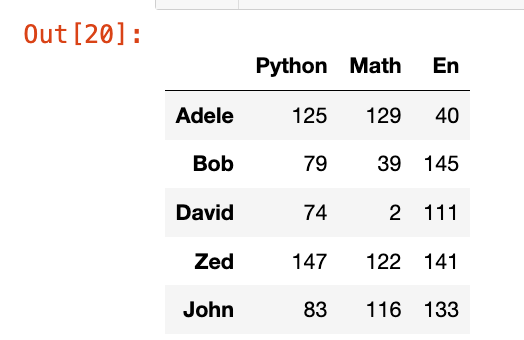
data = np.random.randint(0, 151, (5, 3))
index = ["Adele", "Bob", "David", "Zed", "John"]
columns = ["Python", "Math", "En"]
df = pd.DataFrame(data = data, index = index, columns=columns)
df
【3】访问列:
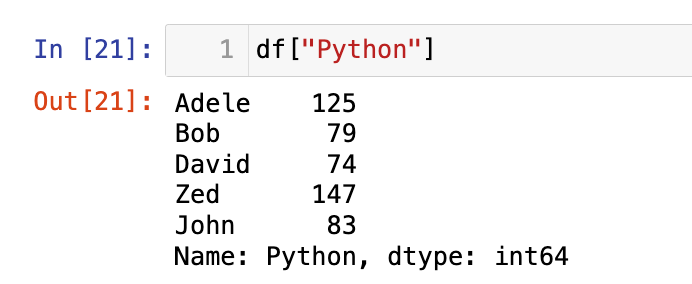
1
df["Python"]
选择题
-
以下关于 DataFrame 的说法,哪一项是正确的?
A. DataFrame 只能包含一种数据类型。 B. DataFrame 类似于一维的 Series。 C. DataFrame 具有行索引和列索引。 D. DataFrame 总是从 NumPy 数组创建。
答案:C
-
如果一个 DataFrame 的行索引和列索引都是字符串,如何使用
.loc访问名为'a'的行和名为'b'的列的交汇处的元素?A.
df['a']['b']B.df.loc['a', 'b']C.df.iloc['a', 'b']D.df['a', 'b']答案:B,
df.loc是基于标签的索引器,用于访问行和列。
编程题
- 创建一个 DataFrame,包含两列
'Name'和'Age',以及三行数据。 - 为这个 DataFrame 添加一列
'City',并为每一行赋一个城市名。 - 打印出添加列后的 DataFrame。
1
2
3
4
5
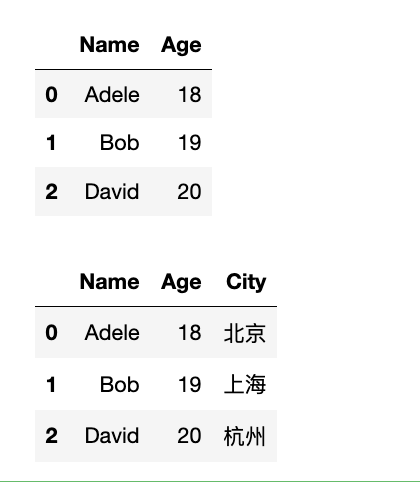
data = {"Name": ["Adele", "Bob", "David"], "Age": [18, 19, 20]}
df = pd.DataFrame(data = data, columns=["Name", "Age"])
display(df)
df["City"] = ["北京", "上海", "杭州"]
display(df)
2.数据查看
在数据分析的初期,数据探索是至关重要的。pandas 提供了多种方法和属性来快速查看 DataFrame 的基本信息、形状、数据类型和统计概览。
df.head(n): 查看 DataFrame 的前n行,默认显示前 5 行。df.tail(n): 查看 DataFrame 的后n行,默认显示后 5 行。df.shape: 一个元组,表示 DataFrame 的维度(行数, 列数)。df.dtypes: 返回一个 Series,显示每列的数据类型。df.index: 返回行索引对象。df.columns: 返回列索引对象。df.values: 返回一个 NumPyndarray,包含 DataFrame 的所有值。df.describe(): 生成数值型列的汇总统计信息,包括计数、均值、标准差、最小值、四分位数和最大值。df.info(): 打印出 DataFrame 的简明摘要,包括索引类型、列索引、数据类型、非空值的数量和内存使用情况。
这些查看方法是数据分析工作流的第一步,它们能够提供关于数据质量和分布的快速洞察。
df.info()在底层遍历 DataFrame 的所有列,并检查每个列的元数据和内存使用情况,这比手动检查每一列的isnull().sum()更快,尤其是在大型数据集中。df.describe()则在底层对每一列的 NumPy 数组执行快速的聚合计算,生成汇总统计信息。这些方法之所以高效,是因为它们充分利用了 pandas 的 C 语言底层实现。
【1】准备150*3 的数据:
1
2
3
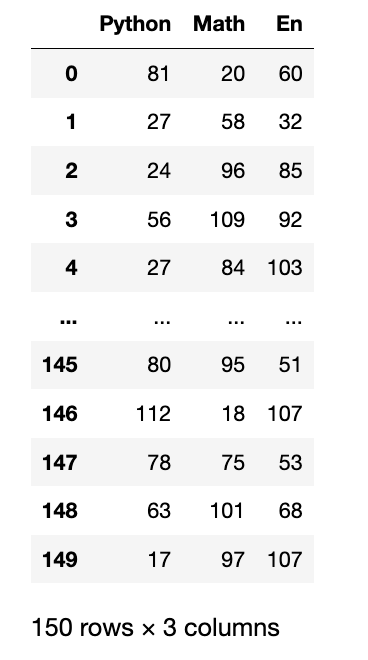
data = np.random.randint(0, 151, (150, 3))
df = pd.DataFrame(data=data, columns=["Python", "Math", "En"])
display(df)
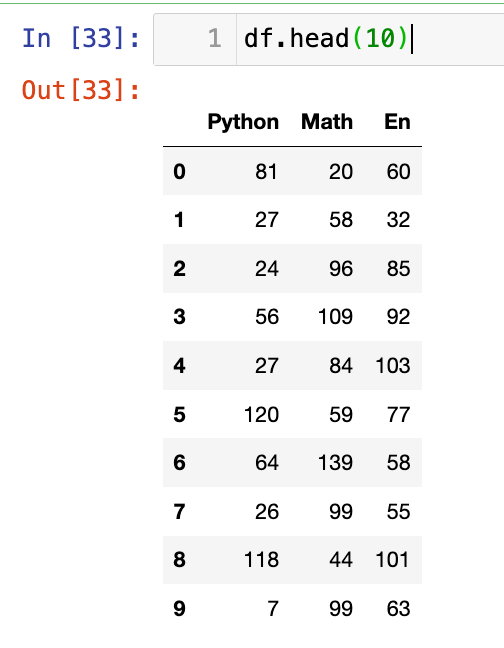
【2】查看前10行:
1
df.head(10)
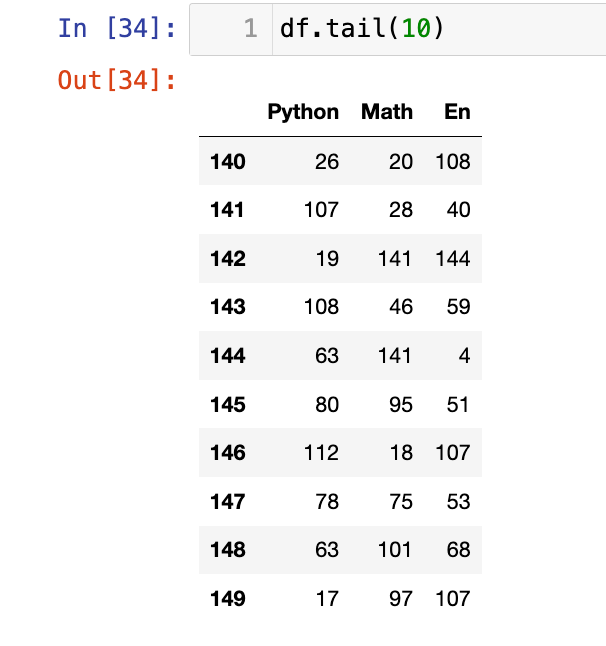
【3】查看后10行
1
df.tail(10)
【4】查看形状

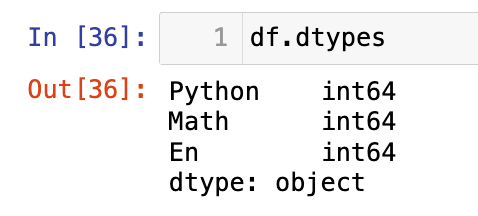
【5】数据类型:
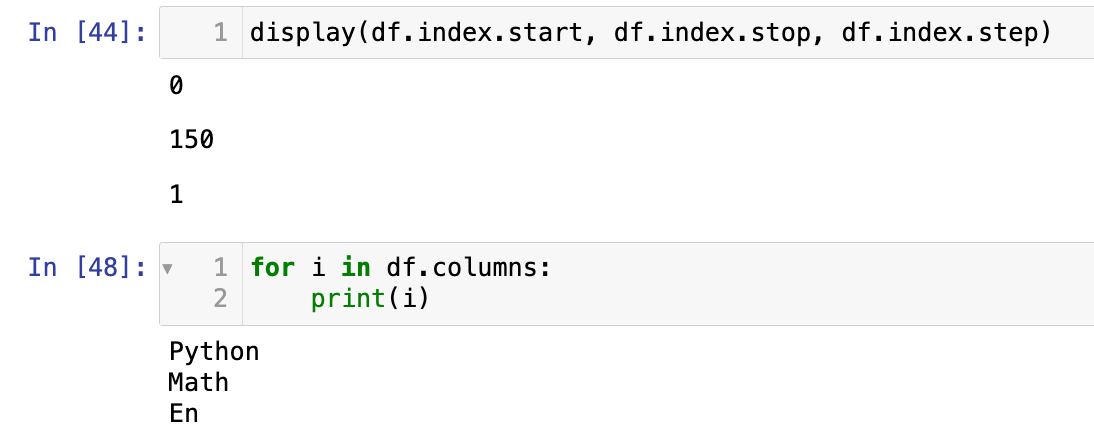
【6】查看索引:
行索引与列索引

【7】查看对象值(底层是二维的numpy数组)

【8】查看数值型列的汇总统计
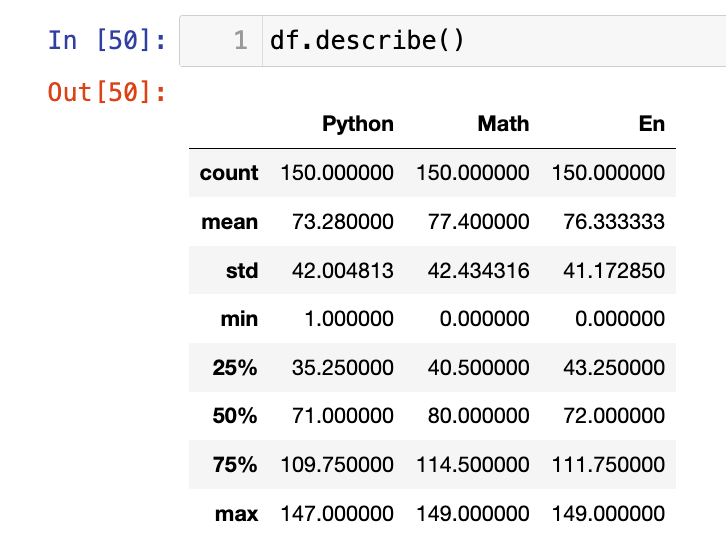
【9】概览和非空计数

选择题
-
以下哪个方法主要用于快速了解 DataFrame 中是否存在缺失值、数据类型是否正确以及内存使用情况?
A.
df.describe()B.df.head()C.df.info()D.df.shape答案:C,
info()提供了关于数据类型、非空计数和内存使用的摘要信息。 -
df.describe()的输出结果中,哪一项通常不包含在内?A. 均值(mean) B. 四分位数(25%, 50%, 75%) C. 非空计数(non-null count) D. 最大值(max)
答案:C,
df.describe()只对数值型数据进行统计,不报告非空计数。非空计数由df.info()提供。
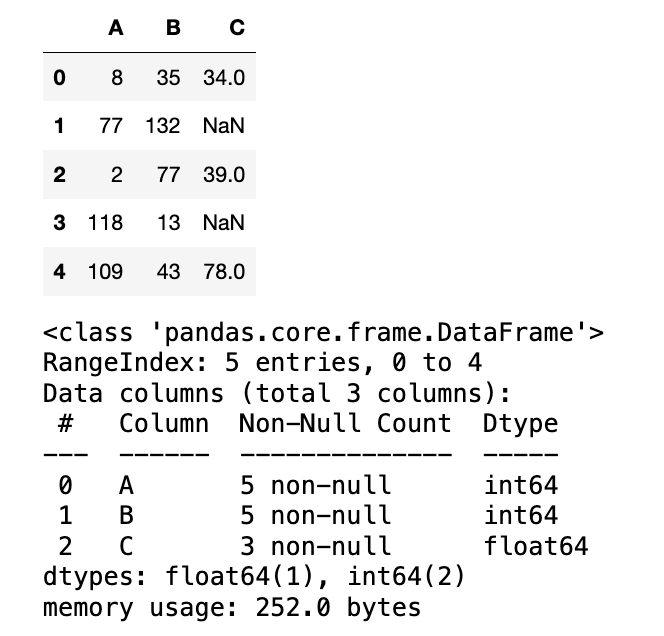
编程题
- 创建一个包含 3 列 (
A,B,C) 和 5 行的 DataFrame,并用随机数填充。 - 为
C列的第 2 和第 4 个元素手动赋值为np.nan。 - 使用
df.info()打印 DataFrame 的摘要,并观察C列的非空计数变化。
1
2
3
4
5
data = np.random.randint(0, 151, (5, 3))
df = pd.DataFrame(data=data, columns=["A", "B", "C"])
df.loc[[1, 3], "C"] = np.nan
display(df)
df.info()