推荐一个json的在线解析器:json.cn
1、HTTP与HTTPS
(1)HTTP
HTTP (HyperText Transfer Protocol):超文本传输协议,是互联网上应用最为广泛的一种网络协议。它是一个基于请求与响应模式的、无状态的应用层协议,常用于传输超文本(如HTML)、图片、视频等资源。
● 无状态 (Stateless):HTTP 协议是无状态的,这意味着服务器不会保存客户端的任何信息。每次请求都是独立的,服务器无法直接知道两次请求是否来自同一个客户端。为了解决这个问题,通常会结合 Cookie 和 Session 来维护状态。
● 请求-响应模式 (Request-Response Model):客户端(如浏览器或爬虫)向服务器发送请求,服务器接收请求后处理,并返回响应。
● 常用方法 (Methods):
○ GET:从服务器获取资源。是最常用的方法,通常用于请求网页、图片等。请求参数会附加在 URL 后面。
○ POST:向服务器提交数据。常用于提交表单、上传文件等。请求参数放在请求体中,安全性相对较高(参数不会直接显示在URL中)。
○ PUT:向服务器上传完整资源,如果资源已存在则更新,不存在则创建。
○ DELETE:删除服务器上的指定资源。
○ HEAD:与 GET 类似,但服务器只返回响应头,不返回响应体。常用于检查资源是否存在或获取元信息。
○ OPTIONS:查询服务器支持的请求方法。
get与post的区别
- Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。
- Get传送的数据量较小,这主要是因为受URL长度限制,不能大于2kb;Post传送的数据量较大,一般被默认为不受限制。
- Get限制Form表单的数据集的值必须为ASCII字符;而Post支持整个ISO10646字符集。
- Get执行效率却比Post方法好。Get是form提交的默认方法。
以上是网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。
但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌。有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
比如:拉勾 https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=
1
2
3
4
5
6
7
8
9
10
11
12
13
# 导入requests库 一个非常流行的用于发送HTTP请求的库
import requests
try:
http_url = "http://httpbin.org/get" # 目前可以访问到
response_http = requests.get(http_url)
print(f"HTTP请求状态码:{response_http.status_code}")
print(f"HTTP响应内容:{response_http.text}")
print(f"HTTP响应的类型:{type(response_http)}") # requests.models.Response
dic_res = response_http.__dict__
for k, v in dic_res.items():
print(f"{k}: {v}")
except requests.exceptions.RequestException as e:
print(f"HTTP请求发生错误:{e}")
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
HTTP请求状态码:200
HTTP响应内容:{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.2",
"X-Amzn-Trace-Id": "Root=1-68729b09-5631afa501ad9a0c6a532b6d"
},
"origin": "159.89.197.90",
"url": "http://httpbin.org/get"
}
HTTP响应的类型:<class 'requests.models.Response'>
_content: b'{\n "args": {}, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.28.2", \n "X-Amzn-Trace-Id": "Root=1-68729b09-5631afa501ad9a0c6a532b6d"\n }, \n "origin": "159.89.197.90", \n "url": "http://httpbin.org/get"\n}\n'
_content_consumed: True
_next: None
status_code: 200
headers: {'Connection': 'close', 'Content-Length': '306', 'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Type': 'application/json', 'Date': 'Sat, 12 Jul 2025 17:27:37 GMT', 'Server': 'gunicorn/19.9.0'}
raw: <urllib3.response.HTTPResponse object at 0x7fa89f5ec760>
url: http://httpbin.org/get
encoding: utf-8
history: []
reason: OK
cookies: <RequestsCookieJar[]>
elapsed: 0:00:00.821807
request: <PreparedRequest [GET]>
connection: <requests.adapters.HTTPAdapter object at 0x7fa89f58ee80>
(2)HTTPS
HTTPS (HyperText Transfer Protocol Secure):超文本传输安全协议,是 HTTP 的安全版本。它在 HTTP 和 TCP 之间加入了一层 SSL/TLS (Secure Sockets Layer/Transport Layer Security) 协议,对网络通信进行加密。
● 安全性 (Security):HTTPS 通过 SSL/TLS 协议提供了数据加密、身份认证和数据完整性保护。
○ 加密 (Encryption):防止数据在传输过程中被窃听。
○ 身份认证 (Authentication):通过数字证书验证服务器的身份,防止中间人攻击。
○ 数据完整性 (Data Integrity):确保数据在传输过程中没有被篡改。
● 端口 (Port):HTTP 默认使用 80 端口,HTTPS 默认使用 443 端口。
● 重要性 (Importance):对于涉及用户隐私(如登录信息、支付数据)或敏感数据的网站,强制使用 HTTPS 是行业标准。作为爬虫开发者,需要能够处理 HTTPS 请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
import requests
# 请求HTTPS
try:
https_url = "https://httpbin.org/get" # 测试相同的网站,但是用Https
response_http = requests.get(https_url)
print(f"HTTPS请求状态码:{response_http.status_code}")
print(f"HTTPS响应内容:{response_http.text}")
print(f"HTTPS响应的类型:{type(response_http)}") # requests.models.Response
dic_res = response_http.__dict__
for k, v in dic_res.items():
print(f"{k}: {v}")
except requests.exceptions.RequestException as e:
print(f"HTTPS请求发生错误:{e}")
输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
HTTPS请求状态码:200
HTTPS响应内容:{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.2",
"X-Amzn-Trace-Id": "Root=1-68729b0a-274b1e9547432e155b64394d"
},
"origin": "159.89.197.90",
"url": "https://httpbin.org/get"
}
HTTPS响应的类型:<class 'requests.models.Response'>
_content: b'{\n "args": {}, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.28.2", \n "X-Amzn-Trace-Id": "Root=1-68729b0a-274b1e9547432e155b64394d"\n }, \n "origin": "159.89.197.90", \n "url": "https://httpbin.org/get"\n}\n'
_content_consumed: True
_next: None
status_code: 200
headers: {'Date': 'Sat, 12 Jul 2025 17:27:38 GMT', 'Content-Type': 'application/json', 'Content-Length': '307', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
raw: <urllib3.response.HTTPResponse object at 0x7fa89f5ecd00>
url: https://httpbin.org/get
encoding: utf-8
history: []
reason: OK
cookies: <RequestsCookieJar[]>
elapsed: 0:00:01.417405
request: <PreparedRequest [GET]>
connection: <requests.adapters.HTTPAdapter object at 0x7fa89f111fa0>
(3)学习代码参考-POST请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import requests
# POST请求
try:
post_url = "https://httpbin.org/post" # 测试相同的网站,但是用Https
payload = {"k1": "v1", "k2": "v2"}
response_http = requests.post(post_url, data=payload)
print(f"post请求状态码:{response_http.status_code}")
print(f"post响应的类型:{type(response_http)}") # requests.models.Response
# 对于POST请求,响应通常是JSON格式
cont_json = response_http.json()
for k, v in cont_json.items():
print(f"{k}: {v}")
except requests.exceptions.RequestException as e:
print(f"post请求发生错误:{e}")
运行输出:
1
2
3
4
5
6
7
8
9
10
post请求状态码:200
post响应的类型:<class 'requests.models.Response'>
args: {}
data:
files: {}
form: {'k1': 'v1', 'k2': 'v2'}
headers: {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Content-Length': '11', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.28.2', 'X-Amzn-Trace-Id': 'Root=1-68729d13-5ab393045bd464f1135de2da'}
json: None
origin: 159.89.197.90
url: https://httpbin.org/post
(4)习题
请使用 requests 库向 https://www.baidu.com/ 发送一个 GET 请求,并打印其响应状态码和响应内容的长度。
参考答案:
1
2
3
4
5
6
7
8
import requests
try:
url = "https://www.baidu.com/"
res = requests.get(url)
print(f"响应状态码:{res.status_code}")
print(f"响应内容的长度:{len(res.text)}")
except requests.exceptions.RequestException as e:
print(f"请求百度出现异常:{e}")
2、URL与URI
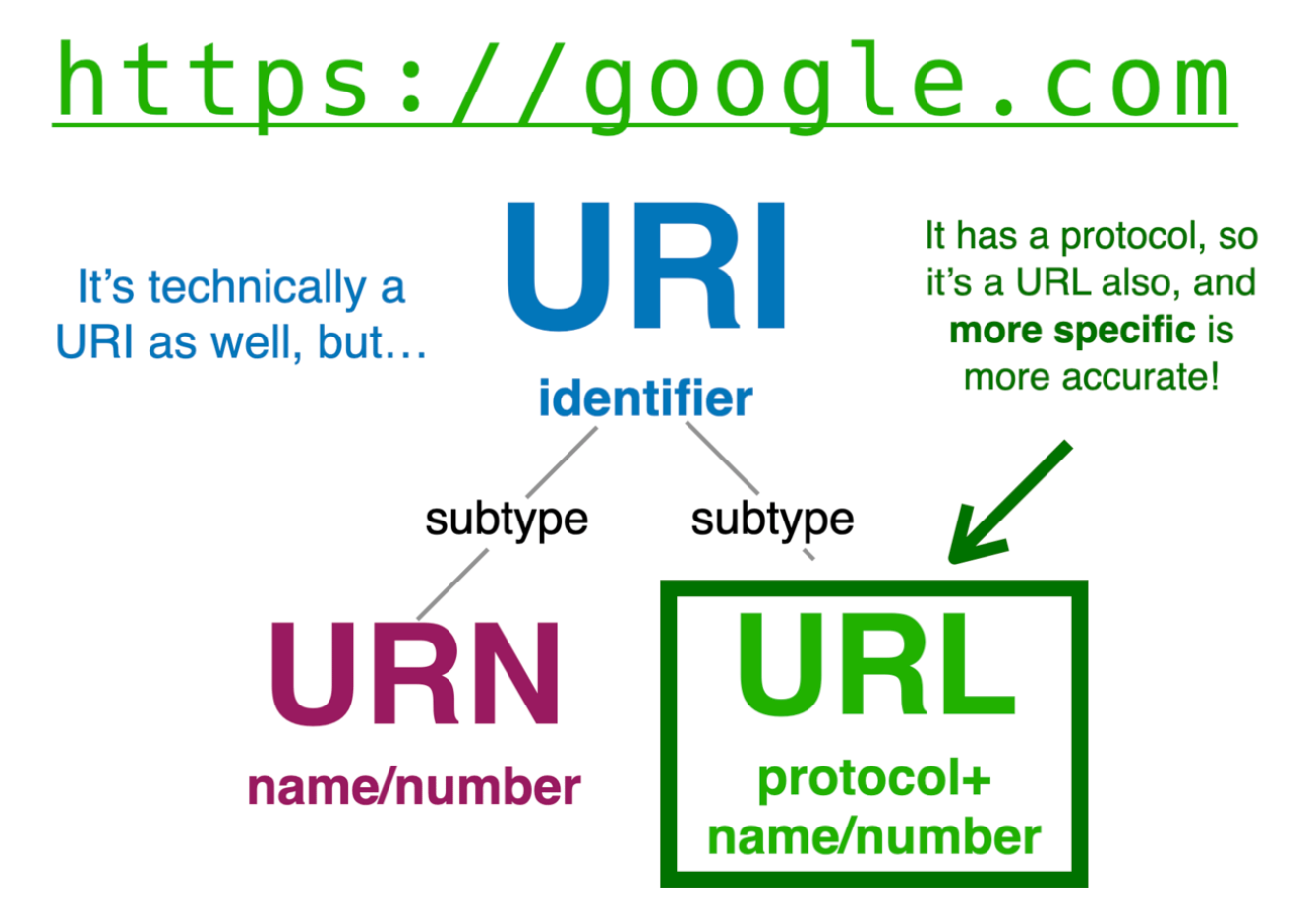
URI (Uniform Resource Identifier):统一资源标识符。它是一个通用概念,用于唯一标识互联网上的任何资源。URI 可以是资源的名称,也可以是资源的地址。
URL (Uniform Resource Locator):统一资源定位符。它是 URI 的一个子集,不仅标识了资源,还指明了如何定位(获取)该资源。简单来说,URL 提供了资源的“地址”。所有的 URL 都是 URI,但不是所有的 URI 都是 URL。
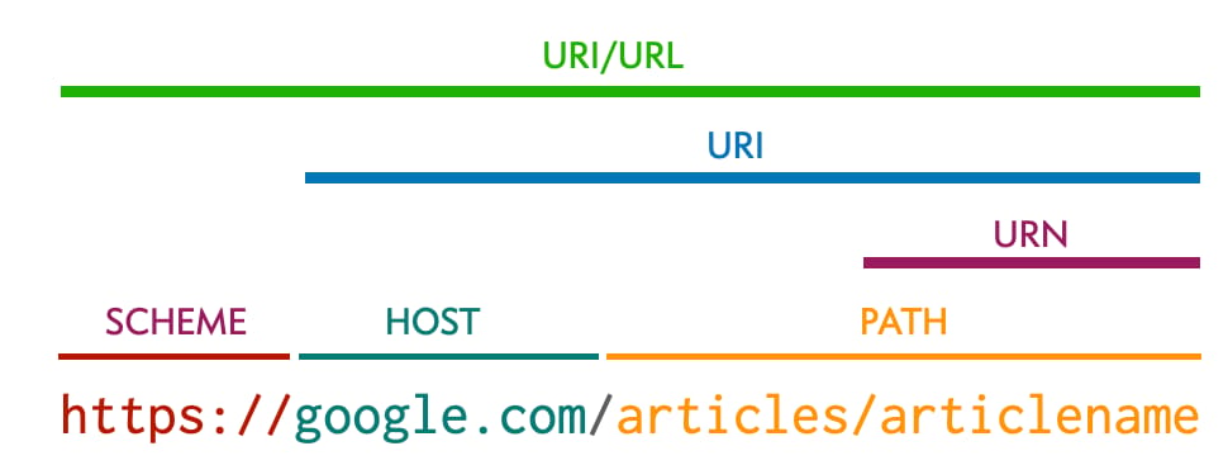
URL 的组成部分:
一个典型的 URL 结构如下:
scheme://host:port/path?query#fragment
● scheme (协议):指定用于访问资源的协议。常见的有 http、https、ftp、file 等。
○ 示例:https
● host (主机):指定资源所在的服务器的域名或 IP 地址。
○ 示例:www.example.com 或 192.168.1.1
● port (端口):可选。指定服务器上用于通信的端口号。如果使用协议的默认端口(HTTP 80,HTTPS 443),则可以省略。
○ 示例:8080 (如果 URL 是 http://www.example.com:8080/)
● path (路径):指定服务器上资源的具体路径。
○ 示例:/path/to/resource.html
● query (查询参数):可选。以 ? 开头,后面跟着一系列 key=value 对,多个键值对之间用 & 连接。用于向服务器传递额外的数据,常用于搜索、过滤等。
○ 示例:?name=John&age=30
● fragment (片段标识符):可选。以 # 开头,用于标识资源内部的某个部分。通常用于浏览器内部跳转到页面的特定锚点,不会发送到服务器。
○ 示例:#section1
示例:
● https://www.google.com/search?q=python%E7%88%AC%E8%99%AB#top
○ scheme: https
○ host: www.google.com
○ path: /search
○ query: q=python%E7%88%AC%E8%99%AB
○ fragment: top
(1)代码学习参考
Python 的 urllib.parse 模块提供了处理 URL 的强大功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
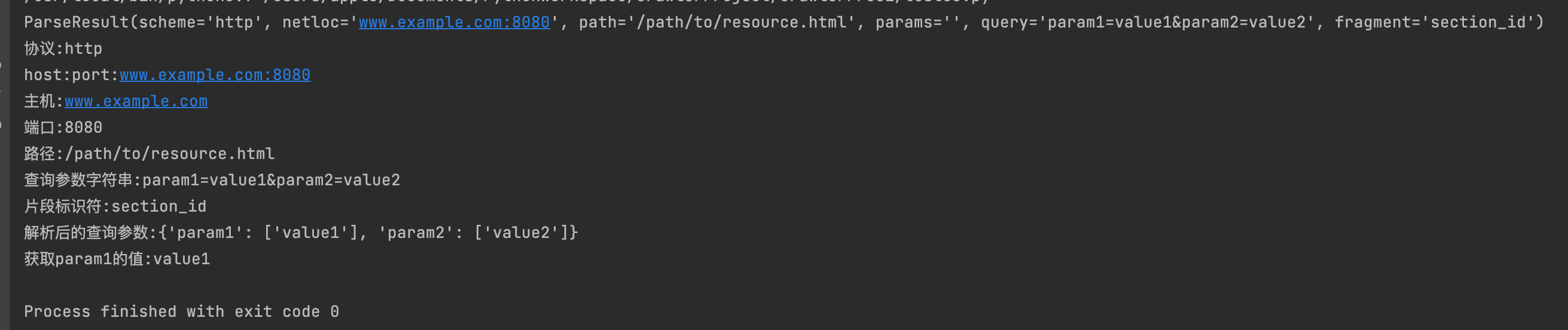
from urllib.parse import urlparse, parse_qs
url = "http://www.example.com:8080/path/to/resource.html?param1=value1¶m2=value2#section_id"
parsed_url = urlparse(url)
print(parsed_url)
print(f"协议:{parsed_url.scheme}")
print(f"host:port:{parsed_url.netloc}")
print(f"主机:{parsed_url.hostname}")
print(f"端口:{parsed_url.port}")
print(f"路径:{parsed_url.path}")
print(f"查询参数字符串:{parsed_url.query}")
print(f"片段标识符:{parsed_url.fragment}")
# 查询参数字符串--->字典
query_params_dict = parse_qs(parsed_url.query)
print(f"解析后的查询参数:{query_params_dict}")
# parse_qs返回字典,值是列表
print(f"获取param1的值:{query_params_dict.get('param1')[0]}")
(2)习题
请解析以下 URL,并打印其 scheme、hostname 和 path。
ftp://ftp.example.org/pub/files/document.pdf
参考答案:
1
2
3
4
5
6
7
8
from urllib.parse import urlparse, parse_qs
url = "ftp://ftp.example.org/pub/files/document.pdf"
parsed_url = urlparse(url)
# 打印其 scheme、hostname 和 path。
print(f"scheme:{parsed_url.scheme}")
print(f"主机名:{parsed_url.hostname}")
print(f"path:{parsed_url.path}")
3、HTTP的请求过程
HTTP 请求过程是客户端(通常是浏览器或您的爬虫程序)与服务器之间进行通信的一系列步骤。理解这个过程对于爬虫开发者至关重要,因为它能帮助模拟真实的用户行为,解决爬取中遇到的问题。
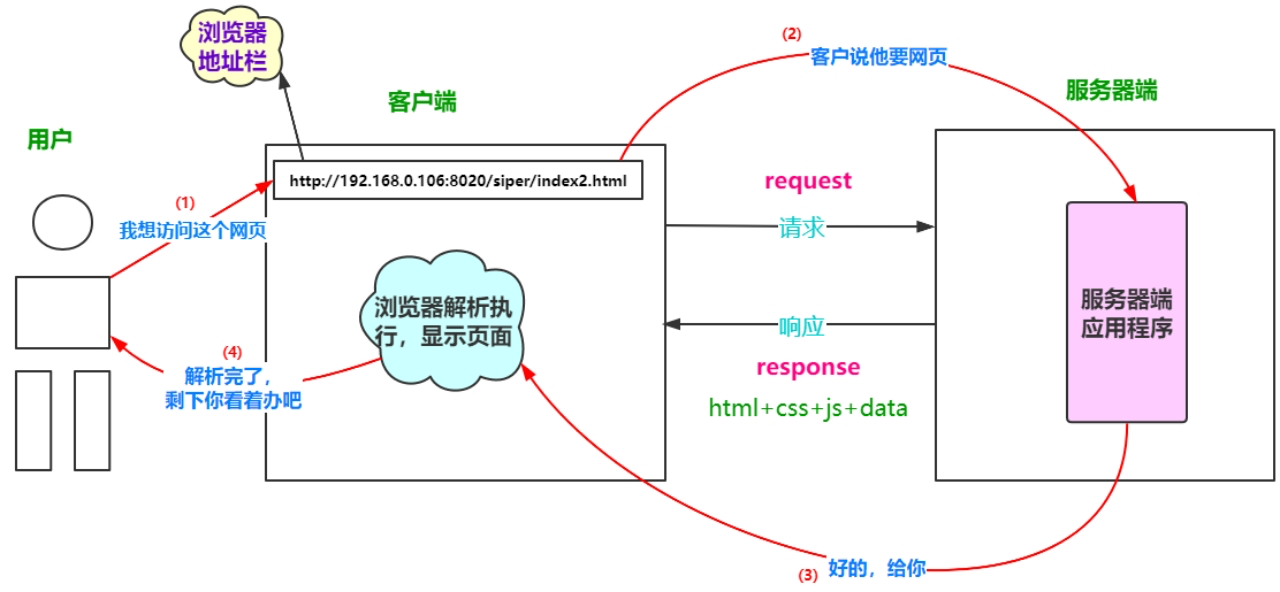
以下是 HTTP 请求的典型过程:
- DNS 解析 (DNS Resolution):
○ 当您输入一个域名(如 www.example.com)时,客户端首先需要知道这个域名对应的 IP 地址。
○ 客户端会向 DNS 服务器发送查询请求,将域名解析为 IP 地址。
○ 如果本地有缓存,则直接使用缓存;否则,会进行递归/迭代查询直到找到对应的 IP 地址。
○ 爬虫模拟: requests 库会自动处理 DNS 解析,您通常无需手动干预。
- 建立 TCP 连接 (TCP Connection Establishment):
○ 一旦获得了服务器的 IP 地址,客户端会尝试与服务器建立一个 TCP 连接。
○ 这通常通过“三次握手”完成:
■ 客户端发送 SYN (同步序列号) 包到服务器。
■ 服务器收到 SYN 包后,发送 SYN-ACK (同步-确认) 包给客户端。
■ 客户端收到 SYN-ACK 包后,发送 ACK (确认) 包给服务器。
○ 连接建立后,客户端和服务器之间就可以可靠地传输数据了。
○ 爬虫模拟: requests 库同样会自动处理 TCP 连接的建立和管理。
- 发送 HTTP 请求 (Sending HTTP Request):
○ TCP 连接建立后,客户端会构建一个 HTTP 请求报文,并将其发送给服务器。
○ HTTP 请求报文通常包含以下部分:
■ 请求行 (Request Line):
■ 方法 (Method):如 GET, POST。
■ URL (Uniform Resource Locator):要请求的资源路径。
■ HTTP 版本 (HTTP Version):如 HTTP/1.1。
■ 示例:GET /index.html HTTP/1.1
■ 请求头 (Request Headers):
■ 提供关于请求或客户端的附加信息。
■ Host: 目标服务器的域名和端口,必需。
■ User-Agent: 客户端(浏览器或爬虫)的身份标识。对爬虫非常重要,很多网站会根据 User-Agent 来判断是否是爬虫。
■ Accept: 客户端能处理的媒体类型。
■ Referer: 指示请求的来源页面。对爬虫也很重要,有些网站会检查 Referer 来防止直接访问。
■ Cookie: 客户端发送给服务器的 Cookie 信息(如果有的话)。
■ Content-Type: POST 请求中请求体的媒体类型(如 application/x-www-form-urlencoded 或 application/json)。
■ Content-Length: POST 请求中请求体的长度。
■ 示例:
1
2
3
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
■ 请求体 (Request Body):
■ 可选。主要用于 POST、PUT 等方法,包含要发送到服务器的数据(如表单数据、JSON 数据)。
○ 爬虫模拟: requests 库允许您轻松地设置请求方法、URL、请求头和请求体。
- 服务器处理请求 (Server Processing):
○ 服务器接收到 HTTP 请求后,会根据请求行和请求头的信息,找到对应的资源或执行相应的操作(如查询数据库、处理表单数据)。
- 发送 HTTP 响应 (Sending HTTP Response):
○ 服务器处理完请求后,会构建一个 HTTP 响应报文,并将其发送回客户端。
○ HTTP 响应报文通常包含以下部分:
■ 状态行 (Status Line):
■ HTTP 版本 (HTTP Version):如 HTTP/1.1。
■ 状态码 (Status Code):一个三位数字,表示请求的结果。
- 1xx(信息性状态码):表示接收的请求正在处理。
- 2xx(成功状态码):表示请求正常处理完毕。
- 3xx(重定向状态码):需要后续操作才能完成这一请求。
- 4xx(客户端错误状态码):表示请求包含语法错误或无法完成。
- 5xx(服务器错误状态码):服务器在处理请求的过程中发生了错误。
常见的响应状态码 200: 请求正常,服务器正常的返回数据 301:永久重定向。比如访问http://www.360buy.com的时候会重定向到www.jd.com http://www.jingdong.com。。。。。。。www.jd.com 404:请求的url在服务器上找不到,换句话说就是请求的url错误. https://www.jianshu.com/fd 418:发送请求遇到服务器端反爬虫,服务器拒绝响应数据 500:服务器内部错误,可能是服务器出现了bug
■ 状态消息 (Status Message):状态码的文字描述。
■ 示例:HTTP/1.1 200 OK
■ 常见状态码:
■ 200 OK:请求成功。
■ 301 Moved Permanently:永久重定向。
■ 302 Found:临时重定向。
■ 400 Bad Request:客户端请求语法错误。
■ 403 Forbidden:服务器拒绝访问(权限问题)。
■ 404 Not Found:请求的资源不存在。
■ 500 Internal Server Error:服务器内部错误。
■ 503 Service Unavailable:服务器暂时无法处理请求。
■ 响应头 (Response Headers):
■ 提供关于响应、服务器或响应内容的附加信息。
■ Content-Type: 响应体的媒体类型(如 text/html, application/json)。
■ Content-Length: 响应体的长度。
■ Set-Cookie: 服务器设置的 Cookie 信息。
■ Server: 服务器软件信息。
■ Location: 重定向时指示新的 URL。
■ 示例:
1
2
3
Content-Type: text/html; charset=UTF-8
Content-Length: 12345
Set-Cookie: sessionid=abcdef123; Path=/; HttpOnly
■ 响应体 (Response Body):
■ 可选。包含服务器返回的实际数据,如 HTML 页面、图片二进制数据、JSON 数据等。
○ 爬虫模拟: requests 库会解析响应,可以轻松访问状态码、响应头和响应体。
- 关闭 TCP 连接 (TCP Connection Termination):
○ 客户端和服务器完成数据传输后,会关闭 TCP 连接,通常通过“四次挥手”完成。
○ 爬虫模拟: requests 库会自动管理连接的关闭。
(1)代码学习参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/13 15:03
import requests
url = "https://www.baidu.com/"
try:
custom_headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:140.0) Gecko/20100101 Firefox/140.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Connection": "keep-alive"
}
res = requests.get(url, headers=custom_headers)
print(f"请求URL:{res.url}")
print(f"响应状态码:{res.status_code}")
print(f"响应状态消息:{res.reason}")
print("------响应头-------")
for k, v in res.headers.items():
print(f"{k}: {v}")
print("------响应内容(前200个字符)-------")
print(res.text[:200])
print("------请求信息-------")
print(f"请求方法:{res.request.method}")
print(f"请求URL:{res.request.url}")
print("------实际发送的请求头-------")
for k, v in res.request.headers.items():
print(f"{k}: {v}")
except requests.exceptions.RequestException as e:
print(f"请求过程发生报错:{e}")
(2)习题
请向 https://www.httpbin.org/status/404 发送一个 GET 请求,并打印其响应状态码和状态消息。
参考:
1
2
3
4
5
6
import requests
url = "https://www.httpbin.org/status/404"
# GET 请求,并打印其响应状态码和状态消息。
res = requests.get(url)
print(f"响应状态码:{res.status_code}")
print(f"响应状态消息:{res.reason}")
4、Chrome分析网站
Chrome 开发者工具(Chrome Developer Tools,简称 DevTools)是前端开发和爬虫开发中不可或缺的利器。它允许您检查网页的 HTML、CSS、JavaScript,更重要的是,它可以监控网络请求,这对于爬虫开发来说至关重要。
如何打开 Chrome 开发者工具:
● 快捷键:
○ Windows/Linux: F12 或 Ctrl + Shift + I
○ macOS: Cmd + Option + I
● 菜单: Chrome 菜单 -> 更多工具 -> 开发者工具。
爬虫开发中主要关注的面板:
- Elements (元素):
○ 显示网页的 HTML 结构。
○ 可以实时修改 HTML 和 CSS,查看效果。
○ 爬虫用途: 用于分析网页结构,定位需要提取的数据所在的 HTML 标签,获取其 CSS 选择器或 XPath。
- Network (网络):
○ 这是爬虫开发者最常用的面板。 它记录了浏览器加载网页过程中所有的网络请求和响应。
○ 主要功能:
■ 请求列表: 按照时间顺序显示所有发出的请求(HTML、CSS、JS、图片、AJAX/XHR 等)。
■ 过滤 (Filter): 可以根据类型(XHR/Fetch, Doc, CSS, JS, Img, Media, Font 等)或关键词过滤请求。
■ XHR/Fetch: 专门用于过滤 AJAX 请求,这对于爬取动态加载的内容非常重要。
■ Doc: 过滤主文档请求(通常是 HTML 页面)。
■ 请求详情 (Click on a request): 点击列表中的任一请求,可以查看其详细信息:
■ Headers (标头):
■ General (常规):请求 URL、请求方法、状态码等。
■ Request Headers (请求标头):浏览器发送给服务器的所有请求头,包括 User-Agent、Referer、Cookie 等。这是爬虫模拟浏览器行为的关键信息。
■ Response Headers (响应标头):服务器返回的所有响应头,包括 Content-Type、Set-Cookie 等。
■ Preview (预览):显示响应内容的渲染预览(如果是 HTML、图片等)。
■ Response (响应):显示原始的响应内容(如 HTML 源代码、JSON 字符串)。
■ Timing (计时):显示请求的各个阶段(DNS 查询、TCP 连接、发送请求、等待响应、下载内容)所花费的时间。
■ 禁用缓存 (Disable cache): 勾选此选项可以防止浏览器使用缓存,每次都从服务器重新请求资源,这对于调试非常有用。
■ 清除 (Clear): 清除当前面板中的所有请求记录。
■ Preserve log (保留日志): 在页面跳转或刷新时保留网络请求日志。
爬虫开发中的应用:
● 识别请求类型: 区分是普通页面加载还是 AJAX 动态加载。
● 获取请求参数: 找出 GET 请求的查询参数,或 POST 请求的表单数据/JSON 数据。
● 模拟请求头: 复制 User-Agent、Referer、Cookie 等重要请求头,以防止被网站识别为爬虫。
● 分析响应内容: 确定响应是 HTML、JSON 还是其他格式,以及如何解析。
● 查找隐藏 API: 很多网站的数据是通过 AJAX 请求从后台 API 获取的,这些 API 往往更容易爬取。
5、Session与Cookie
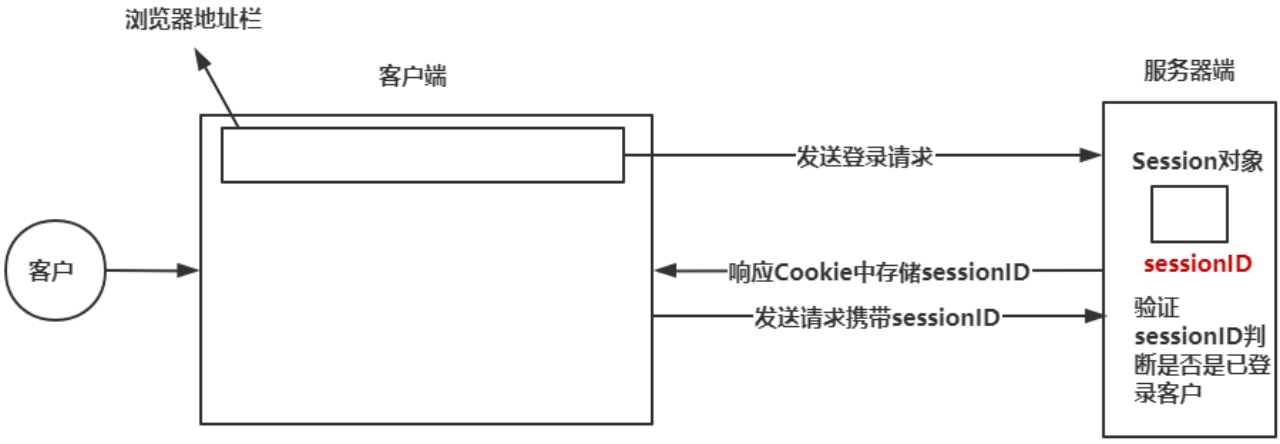
由于 HTTP 协议是无状态的,服务器无法记住用户的身份或之前的操作。为了在多次请求之间维护用户状态,引入了 Cookie 和 Session 机制。
(1)Cookie
● 定义: Cookie 是服务器发送到用户浏览器并保存在用户本地的一小段文本信息。
● 工作原理:
- 当浏览器第一次请求某个网站时,服务器在响应头中通过
Set-Cookie字段向浏览器发送 Cookie。 - 浏览器接收到 Cookie 后,将其存储在本地。
- 之后,每次浏览器向同一个网站发送请求时,都会自动在请求头中通过 Cookie 字段将该网站相关的 Cookie 发送回服务器。
- 服务器接收到 Cookie 后,可以识别用户身份或获取之前存储的信息。
● 用途:
○ 会话管理: 记住用户登录状态、购物车内容等。
○ 个性化设置: 记住用户偏好(如语言、主题)。
○ 跟踪用户行为: 记录用户访问历史、广告点击等。
● 类型:
○ 会话 Cookie (Session Cookie):通常不设置过期时间,在浏览器关闭时失效。
○ 持久化 Cookie (Persistent Cookie):设置了过期时间,在过期前会一直保存在用户硬盘上。
(2)Session
● 定义: Session 是服务器端用于维护用户状态的一种机制。它将用户的一些信息存储在服务器上。
● 工作原理:
- 当用户第一次访问网站时,服务器会创建一个唯一的 Session ID,并将与该 Session ID 关联的用户信息存储在服务器内存或数据库中。
- 服务器将这个 Session ID 通过 Cookie 的形式发送给浏览器。
- 浏览器将 Session ID 存储为 Cookie,并在后续请求中将其发送回服务器。
- 服务器通过收到的 Session ID 查找对应的 Session 数据,从而识别用户并获取其状态信息。
● 与 Cookie 的关系: Session 依赖于 Cookie 来传递 Session ID。如果浏览器禁用了 Cookie,Session 就无法正常工作(除非通过 URL 重写等方式传递 Session ID,但这不常见且不安全)。
● 安全性: Session 信息存储在服务器端,相对更安全,因为敏感数据不会暴露在客户端。
爬虫中的应用:
● 模拟登录: 登录通常涉及 Cookie 和 Session。爬虫需要能够接收服务器设置的 Cookie,并在后续请求中带上这些 Cookie,以维持登录状态。
● 维持会话: 访问需要登录才能查看的页面,或者在多个请求之间保持某种状态(如分页浏览)。
(3)学习代码参考
requests 库提供了 Session 对象,可以非常方便地处理 Cookie 和会话。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import requests
url_set_cookie = "https://httpbin.org/cookies/set?name=Adele&age=18"
url_get_cookie = "https://httpbin.org/cookies"
# 第一次请求,服务器会设置cookie
res1 = requests.get(url_set_cookie)
print(f"第一次请求状态码:{res1.status_code}")
print(f"第一次请求设置的cookie是:{res1.headers.get('Set-Cookie', '无')}") # 第一次请求设置的cookie是:无
# 第二次请求,不使用Session,requests默认不会带上之前的cookie
res2 = requests.get(url_get_cookie)
print(f"第二次请求状态码:{res2.status_code}")
print(f"第二次请求f发送的Cookie:{res2.json()}") # res2并没有带上res1设置的cookie
# 创建一个session对象
s = requests.session()
# 使用session对象发送请求
res1_s = s.get(url_set_cookie)
print(f"session第一次请求状态码:{res1_s.status_code}")
res1_s_json = res1_s.json() # 字典
for k, v in res1_s_json.items():
print(f"{k}: {v}") # cookies: {'age': '18', 'name': 'Adele'}
# 第二次请求,带上之前存储的cookie发送给服务器
res2_s = s.get(url_get_cookie)
print(f"session第二次请求状态码:{res2_s.status_code}")
print(f"session第二次请求发送的cookie:{res2_s.json()}")
运行输出:
1
2
3
4
5
6
7
8
第一次请求状态码:200
第一次请求设置的cookie是:无
第二次请求状态码:200
第二次请求f发送的Cookie:{'cookies': {}}
session第一次请求状态码:200
cookies: {'age': '18', 'name': 'Adele'}
session第二次请求状态码:200
session第二次请求发送的cookie:{'cookies': {'age': '18', 'name': 'Adele'}}
6、JSON数据
JSON (JavaScript Object Notation):JavaScript 对象表示法,是一种轻量级的数据交换格式。它易于人阅读和编写,也易于机器解析和生成。JSON 广泛应用于 Web 应用程序之间的数据传输,尤其是前后端数据交互和 API 接口。
JSON 基于 JavaScript 编程语言的一个子集,但它是一种独立于语言的数据格式。它主要由两种结构组成:
- 对象 (Object):
○ 表示为 {} (大括号)。
○ 包含一系列 键值对 (key-value pairs)。
○ 键 (key) 必须是字符串(用双引号包围)。
○ 值 (value) 可以是字符串、数字、布尔值(true/false)、null、数组或另一个 JSON 对象。
○ 键值对之间用 , (逗号)分隔。
○ 键和值之间用 : (冒号)分隔。
○ 示例:
1
2
3
4
5
{
"name": "张三",
"age": 30,
"isStudent": false
}
- 数组 (Array):
○ 表示为 [] (方括号)。
○ 包含一系列有序的值。
○ 值可以是字符串、数字、布尔值、null、对象或另一个数组。
○ 值之间用 , (逗号)分隔。
○ 示例:
1
2
3
4
5
[
"apple",
"banana",
"orange"
]
JSON 数据类型:
● 字符串 (String):用双引号 “” 包围的 Unicode 字符序列。
● 数字 (Number):整数或浮点数。
● 布尔值 (Boolean):true 或 false。
● 空值 (Null):null。
● 对象 (Object):键值对的无序集合。
● 数组 (Array):值的有序集合。
Python 与 JSON:
Python 内置的 json 模块提供了处理 JSON 数据的功能。
● json.loads() (load string):将 JSON 格式的字符串解析成 Python 对象(通常是字典或列表)。
● json.dumps() (dump string):将 Python 对象(字典或列表)编码成 JSON 格式的字符串。
● response.json() (requests 库特有):requests 库的响应对象提供了一个方便的 .json() 方法,可以直接将 JSON 格式的响应体解析成 Python 字典或列表。
爬虫中的应用:
● API 爬取: 许多网站的动态数据是通过 RESTful API 返回 JSON 格式的数据。直接请求这些 API 接口是高效且稳定的爬取方式。
● 数据存储: 有时爬取到的数据也可以以 JSON 格式存储到本地文件。
(1)学习代码参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/13 17:24
import json
import requests
# 准备一个python字典
python_dict= {
"name": "李四",
"age": 18,
"city": "北京",
"hobbies": ["读书", "做菜", "旅行"],
"isStudent": True,
"extra_info": None
}
# dict--->json
# ensure_ascii=False允许输出非ACSII的字符(比如中文)
# indent=4输出的json字符串带缩紧,更易读
json_str = json.dumps(python_dict, ensure_ascii=False, indent=4)
print(json_str)
print(type(json_str))
# json--->python对象
decoded_python_obj = json.loads(json_str)
print(decoded_python_obj)
print(type(decoded_python_obj))
print(decoded_python_obj["name"])
print(decoded_python_obj["hobbies"][0])
# 从web API获取json数据:
# https://jsonplaceholder.typicode.com/posts/1
api_url = "https://jsonplaceholder.typicode.com/posts/1"
try:
res = requests.get(api_url)
res.raise_for_status() # 如果状态码不是200,抛出异常
# 使用response.json() 解析json
json_data = res.json()
print(json_data)
print(type(json_data)) # 类型dict
# 格式化打印
print(json.dumps(json_data, indent=4, ensure_ascii=False))
print(f"userId:{json_data['userId']}")
print(f"title:{json_data['title']}")
except requests.exceptions.RequestException as e:
print(f"获取json数据时发生错误:{e}")
运行输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
{
"name": "李四",
"age": 18,
"city": "北京",
"hobbies": [
"读书",
"做菜",
"旅行"
],
"isStudent": true,
"extra_info": null
}
<class 'str'>
{'name': '李四', 'age': 18, 'city': '北京', 'hobbies': ['读书', '做菜', '旅行'], 'isStudent': True, 'extra_info': None}
<class 'dict'>
李四
读书
{'userId': 1, 'id': 1, 'title': 'sunt aut facere repellat provident occaecati excepturi optio reprehenderit', 'body': 'quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto'}
<class 'dict'>
{
"userId": 1,
"id": 1,
"title": "sunt aut facere repellat provident occaecati excepturi optio reprehenderit",
"body": "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto"
}
userId:1
title:sunt aut facere repellat provident occaecati excepturi optio reprehenderit
(2)习题
请访问 https://jsonplaceholder.typicode.com/users/1,获取该用户的 JSON 数据,并打印其 name 和 email。
1
2
3
4
5
6
7
# https://jsonplaceholder.typicode.com/users/1
# 获取该用户的 JSON 数据,并打印其 name 和 email
import requests
url = "https://jsonplaceholder.typicode.com/users/1"
json_data_dict = requests.get(url).json()
print(f"name:{json_data_dict['name']}")
print(f"emaill:{json_data_dict['email']}")
运行输出:
1
2
name:Leanne Graham
emaill:Sincere@april.biz
7、Ajax请求
AJAX (Asynchronous JavaScript and XML):异步 JavaScript 和 XML。它不是一种新的编程语言,而是一种用于创建快速动态网页的技术。AJAX 允许网页在不重新加载整个页面的情况下,与服务器进行异步通信,从而更新部分网页内容。
(1)AJAX 的核心思想
● 异步 (Asynchronous):意味着 JavaScript 可以向服务器发送请求,而无需等待服务器响应,用户可以继续与页面进行交互。当服务器响应返回时,JavaScript 会处理响应并更新页面。
● 局部更新 (Partial Page Update):传统的网页每次数据更新都需要重新加载整个页面,用户体验差。AJAX 允许只更新页面中需要变化的部分,大大提升了用户体验和页面加载速度。
● 数据格式: 尽管名称中包含 “XML”,但现在 AJAX 请求返回的数据更多地使用 JSON 格式,因为它更轻量、更易于解析。
(2)AJAX 请求的工作流程:
-
用户在网页上触发某个事件(如点击按钮、滚动页面)。
-
JavaScript 代码(通常是 XMLHttpRequest 对象或 Fetch API)在后台向服务器发送一个 HTTP 请求。
-
服务器处理请求并返回数据(通常是 JSON 或 XML)。
-
JavaScript 接收到数据后,解析数据,并动态地更新网页的相应部分,而无需刷新整个页面。
(3)为什么 AJAX 对爬虫很重要?
● 动态内容: 许多现代网站的内容(如新闻列表、商品评论、无限滚动加载的商品)并非在初始 HTML 页面中完全呈现。它们是在用户与页面交互时,通过 AJAX 请求从服务器动态加载的。
● 传统爬虫的局限: 如果只抓取初始 HTML 页面,您将无法获取到这些动态加载的内容。
● 爬虫应对策略:
-
模拟 AJAX 请求: 这是最常见和高效的方法。通过 Chrome 开发者工具分析 AJAX 请求的 URL、请求方法、请求头和请求体,然后使用 requests 库直接模拟这些 AJAX 请求来获取数据。
-
使用无头浏览器: 对于复杂的 JavaScript 渲染(例如需要执行大量 JavaScript 代码才能生成内容的网站),可以使用 Selenium 或 Playwright 等无头浏览器来模拟真实的浏览器环境,等待页面完全加载后再提取数据。这种方法资源消耗较大,速度较慢,通常作为模拟 AJAX 请求的备选方案。
(4)如何在 Chrome 开发者工具中识别 AJAX 请求:
● 打开开发者工具 (F12),切换到 Network (网络) 面板。
● 在过滤栏中选择 XHR 或 Fetch。
● 在页面上进行操作(如滚动、点击加载更多、切换标签页),观察这些过滤后的请求。
● 点击这些请求,检查其 Headers 和 Response,特别是 Response 中的数据格式(通常是 JSON)。