1.数据的来源及作用

在当今的数字化时代,数据无处不在,其来源非常广泛,主要可以分为以下几类:
- 互联网公开数据: 这是最常见的来源,包括网站上的文本、图片、视频、商品信息、新闻文章、社交媒体帖子、论坛讨论、公开API接口返回的数据等。这些数据通常可以通过网络爬虫直接获取。
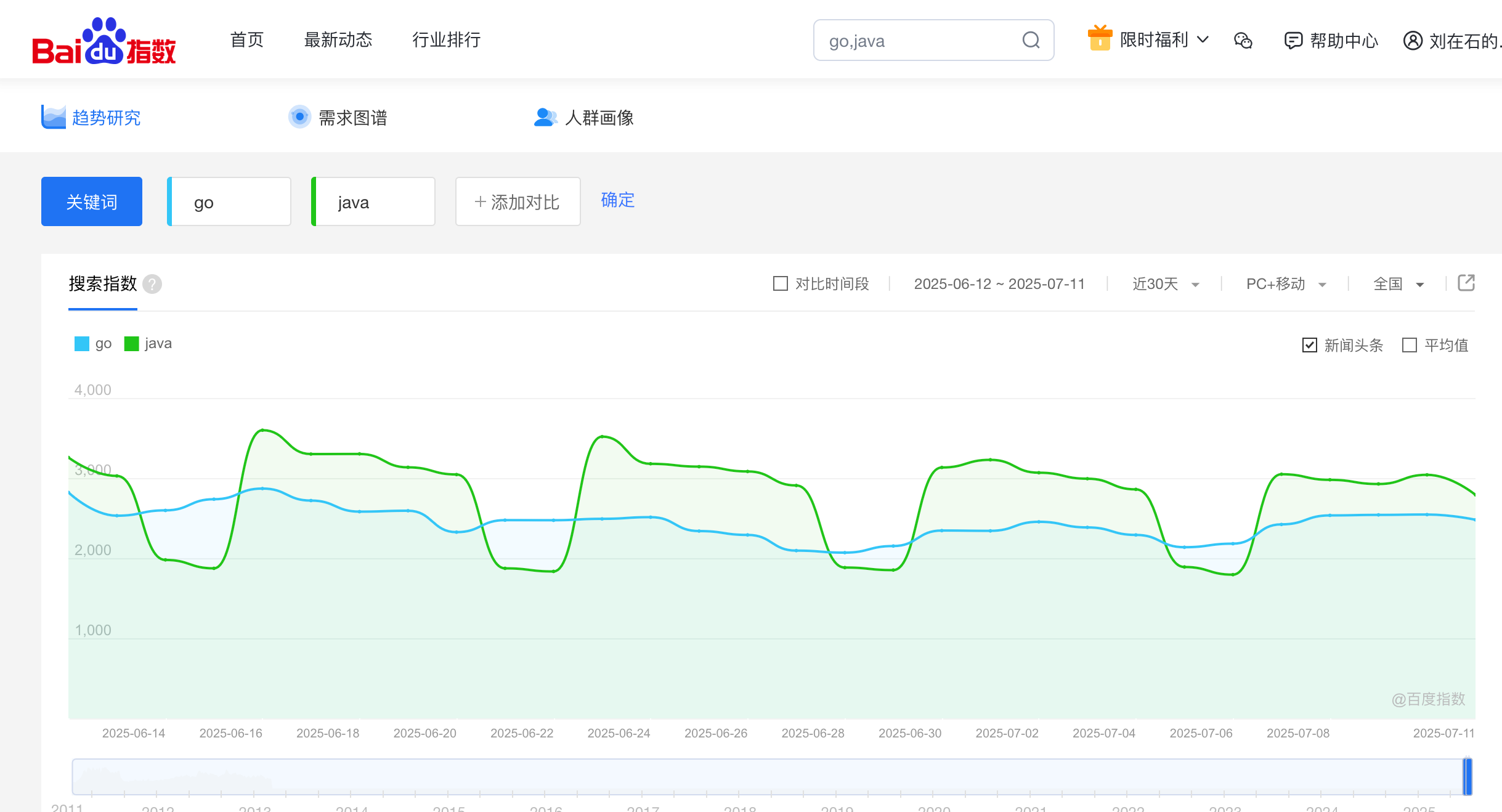
图中是百度指数关于java和golang语言的对比,无论是其底层的数据收集方式(搜索引擎的爬取和用户搜索行为),还是其最终呈现的形式(聚合的搜索指数图表),都完美地诠释了“互联网公开数据”的来源、类型、处理和应用价值。它将散落在互联网上的海量用户行为数据,经过加工后,以一种结构化、可视化、易于理解的方式重新呈现出来,供大众进行分析和利用。
- 企业内部数据: 各个企业在日常运营中产生的数据,如销售记录、客户信息、库存数据、财务报表、员工数据等。这些数据通常存储在企业的数据库、数据仓库或内部系统中。
- 传感器数据: 物联网设备、智能设备、环境监测站等产生的实时数据,如温度、湿度、位置、运动轨迹、心率等。
- 政府/公共机构数据: 政府部门、研究机构、国际组织等发布的公开数据,如统计年鉴、人口普查数据、气象数据、科研论文等。
- 第三方数据提供商: 专门收集、整理和销售各种类型数据的公司,它们通常提供经过清洗和结构化的数据产品。
数据在现代社会中扮演着极其重要的角色,其作用体现在各个方面:
- 商业决策: 企业通过分析市场数据、用户行为数据、竞争对手数据等,制定更精准的营销策略、产品开发方向和运营计划。
- 科学研究: 科学家利用大量实验数据、观测数据进行分析,发现规律,验证假设,推动科学进步。
- 社会治理: 政府部门利用人口数据、经济数据、环境数据等进行宏观调控、城市规划、公共服务优化。
- 个性化服务: 基于用户数据,提供定制化的推荐、广告和内容,提升用户体验。
- 风险控制: 金融机构通过分析交易数据、信用数据等,评估风险,防范欺诈。
- 人工智能与机器学习: 大量高质量的数据是训练机器学习模型的基础,数据决定了模型的性能上限。
- 趋势预测: 通过对历史数据的分析,预测未来的发展趋势,如股票价格、天气变化、疾病传播等。
2.什么是爬虫
网络爬虫(Web Crawler),也称为网络蜘蛛(Web Spider)或网络机器人(Web Robot),是一种按照一定规则,自动地抓取互联网信息的程序或脚本。
简单来说,爬虫就是模拟人类在浏览器中浏览网页的行为,通过发送HTTP请求(如GET、POST),接收服务器响应,然后解析响应内容(HTML、JSON等),从中提取出所需数据的自动化工具。
3.爬虫的分类
网络爬虫可以根据其功能、抓取方式和应用领域进行多种分类:
3.1 根据抓取方式:
- 通用爬虫 (General-Purpose Web Crawler):
- 特点: 抓取互联网上尽可能多的网页,构建一个庞大的网页库,供搜索引擎使用。它们通常从少量起始URL开始,通过解析网页中的链接不断扩展抓取范围。
- 代表: 搜索引擎的爬虫(如Googlebot, Baidu Spider)。
- 聚焦爬虫 (Focused Web Crawler / Topical Crawler):
- 特点: 针对特定主题或领域,只抓取与该主题相关的网页。它们会根据网页内容的相关性进行筛选,避免抓取无关信息,从而提高效率和数据质量。
- 应用: 垂直搜索引擎、行业数据分析、特定领域信息收集。
3.2 根据实现技术:

- 批量式爬虫: 一次性抓取大量数据,通常用于构建大型数据集。
- 增量式爬虫: 定期检查已抓取网页的更新情况,只抓取新增或修改的内容,保持数据的时效性。
- 分布式爬虫: 将爬取任务分解到多台机器上并行执行,以提高抓取效率和处理能力,适用于大规模数据抓取。
3.3 根据数据来源:
- 网页爬虫: 主要抓取HTML网页内容。
- API爬虫: 通过调用网站或服务提供的API接口获取结构化数据。
- APP爬虫: 模拟移动应用的行为,抓取APP内的数据。
3.4 根据行为模式:
- 礼貌型爬虫: 遵守网站的
robots.txt协议,不给网站服务器造成过大压力。 - 非礼貌型爬虫: 不遵守
robots.txt协议,可能对网站服务器造成负担,甚至被封禁。
4.爬虫的原理
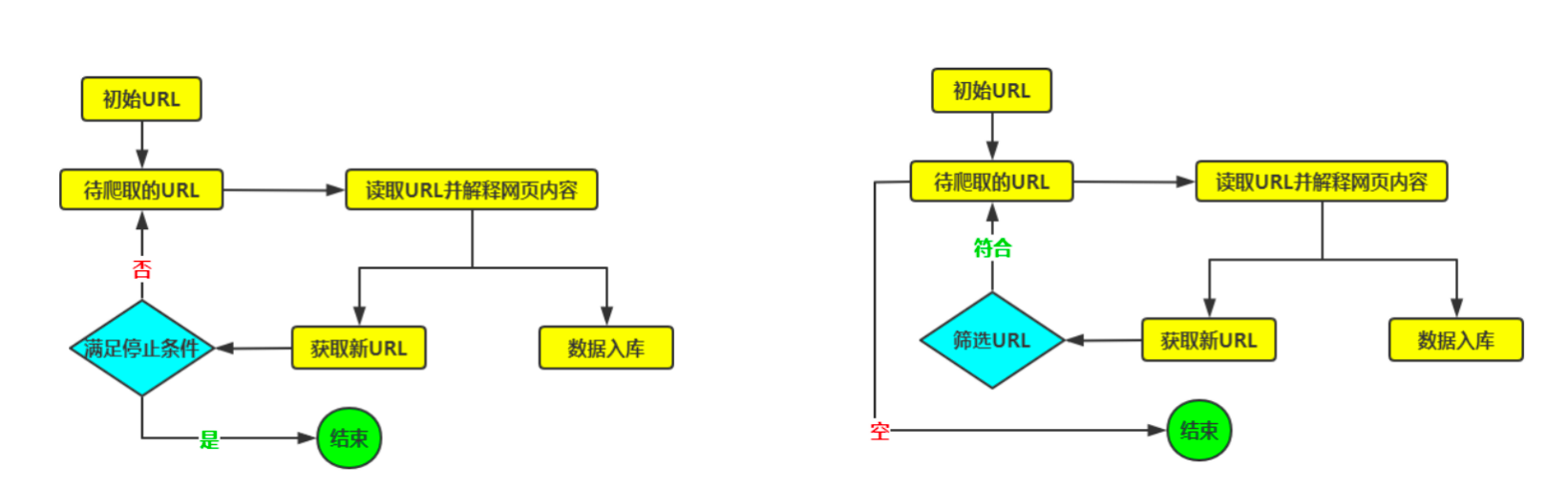
网络爬虫的基本工作原理可以概括为以下几个步骤:
- URL管理器 (URL Manager):
○ 负责管理待抓取的URL队列和已抓取的URL集合。
○ 确保URL不重复抓取,并可以根据优先级进行调度。
○ 起始时,会有一个或多个初始URL。
- 网页下载器 (Downloader):
○ 根据URL管理器提供的URL,发起HTTP/HTTPS请求(GET或POST)。
○ 接收服务器返回的响应(HTML、JSON、图片等)。
○ 处理HTTP状态码、重定向、Cookie等。
- 网页解析器 (Parser):
○ 对下载下来的网页内容进行解析,提取所需数据。
○ 常用的解析技术包括:
■ 正则表达式 (Regular Expression): 适用于简单、有规律的文本匹配。
■ XPath: 基于XML路径语言,用于在XML或HTML文档中查找信息。
■ CSS选择器 (CSS Selector): 类似于CSS样式表中的选择器,用于选择HTML元素。
■ BeautifulSoup: 一个Python库,用于从HTML或XML文件中提取数据,非常灵活和易用。
■ PyQuery: 类似jQuery的Python库,用于解析HTML。
■ Selenium/Playwright: 模拟浏览器行为,处理JavaScript动态加载的内容。
- 数据存储器 (Data Storage):
○ 将解析器提取出的数据进行存储。
○ 存储方式可以是:
■ 文件: TXT、CSV、JSON、XML等。
■ 数据库: 关系型数据库(MySQL, PostgreSQL, SQLite)、非关系型数据库(MongoDB, Redis)。
■ 内存: 临时存储,程序结束后数据丢失。
5.为什么用Python语言写爬虫
Python之所以成为编写网络爬虫的首选语言,主要有以下几个原因:
● 丰富的第三方库: Python拥有极其丰富且功能强大的第三方库,为爬虫开发提供了极大的便利。
○ HTTP请求库: requests (简单易用,功能强大)。
○ HTML/XML解析库: BeautifulSoup4, lxml, PyQuery (解析效率高,语法简洁)。
○ 动态网页抓取: Selenium, Playwright (模拟浏览器行为,处理JavaScript渲染的页面)。
○ 爬虫框架: Scrapy (高性能、可扩展的专业爬虫框架)。
○ 数据处理: pandas, numpy (数据清洗、分析和存储)。
● 语法简洁,开发效率高: Python语言的语法非常简洁明了,代码可读性强,开发效率远高于Java、C++等语言。这使得开发者能够快速构建和迭代爬虫程序。
● 跨平台性: Python可以在Windows、macOS、Linux等多种操作系统上运行,保证了爬虫程序的通用性。
● 社区活跃,资料丰富: Python拥有庞大而活跃的开发者社区,遇到问题很容易找到解决方案和学习资料。
● 胶水语言特性: Python可以很方便地与其他语言(如C/C++编写的库)进行集成,利用其高性能部分。
● 数据科学和机器学习的生态: 爬取到的数据通常需要进行后续的分析和处理。Python在数据科学和机器学习领域拥有强大的生态系统(如pandas, scikit-learn, TensorFlow, PyTorch),使得数据从爬取到分析形成一个完整的闭环。
● 异步IO支持: Python 3.5+ 引入的 asyncio 模块,以及 aiohttp 等库,使得编写高并发、非阻塞的异步爬虫成为可能,大大提高了爬取效率。
综上所述,Python凭借其简洁的语法、丰富的库支持、高效的开发速度和强大的生态系统,成为了网络爬虫领域的“明星”语言。