1、编码格式介绍
字符编码是将字符(如字母、数字、符号)转换为计算机可以存储和处理的二进制数据(字节)的过程。常见的编码格式包括ASCII、Unicode(及其实现UTF-8、UTF-16等)。理解编码对于正确处理文本数据至关重要。
计算机只能理解二进制数据(0和1)。当我们处理文本时,需要一种方式将人类可读的字符映射到这些二进制数据上。这就是字符编码的作用。
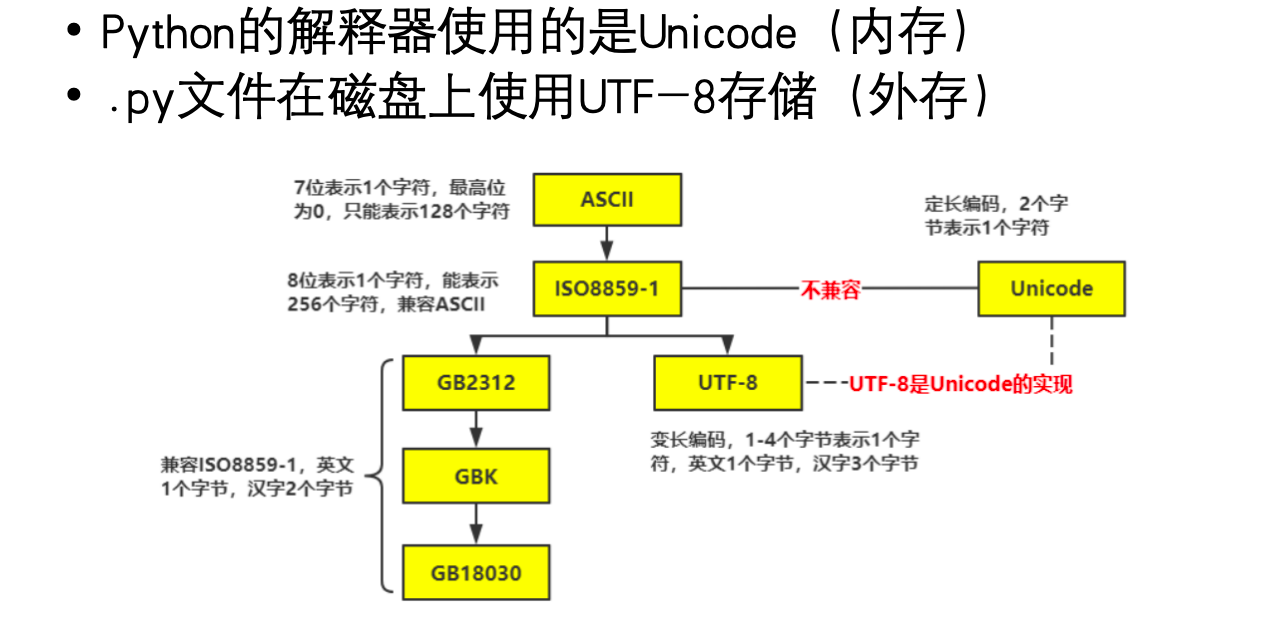
ASCII:最早且最简单的编码标准之一。使用7位二进制数表示128个字符,包括英文字母(大小写)、数字、标点符号和一些控制字符。无法表示非英文字符,如中文、日文、德文的变音符号等。
Unicode:为了解决ASCII的局限性,Unicode应运而生。它是一个国际标准,旨在为世界上所有字符提供一个唯一的数字编码(称为码点)。Unicode本身只是一个字符集,定义了字符和码点之间的映射关系,例如字符 ‘A’ 的码点是 U+0041,字符 ‘中’ 的码点是 U+4E2D。 Unicode只是定义了每个字符的唯一数字标识,但并没有规定这些数字如何存储为字节。因此,需要不同的编码方案来将Unicode码点转换为字节序列。最常见的Unicode编码方案有:
-
UTF-8 (Unicode Transformation Format - 8-bit):最流行和推荐的Unicode编码。它使用1到4个字节来表示一个Unicode字符。ASCII字符(0-127)只占用1个字节,与ASCII兼容。节省存储空间(对于英文文本),向后兼容ASCII,并且能够表示所有Unicode字符。它是Web、Linux系统和许多现代应用程序的首选编码。
-
UTF-16 (Unicode Transformation Format - 16-bit):使用2或4个字节表示一个Unicode字符。在Windows系统和Java内部常用。
-
UTF-32 (Unicode Transformation Format - 32-bit):使用固定的4个字节表示一个Unicode字符。
■ 优点: 查找字符速度快(因为每个字符长度固定)。
■ 缺点: 占用大量存储空间,即使是ASCII字符也占用4个字节,因此不常用。
其他编码格式:
- GBK (国标扩展): 中国大陆常用的编码,用于表示简体中文。
- Big5 (大五码): 台湾和香港常用的编码,用于表示繁体中文。
- Latin-1 (ISO-8859-1): 欧洲常用,支持西欧语言的字符。
● 在Python 3中,str 类型(字符串)默认是Unicode,表示抽象的字符序列。
● bytes 类型(字节串)表示实际的二进制数据,由0到255的整数组成。
● 编码 (Encoding): 将 str 对象转换为 bytes 对象,需要指定编码格式(例如 my_string.encode('utf-8'))。
● 解码 (Decoding): 将 bytes 对象转换为 str 对象,也需要指定编码格式(例如 my_bytes.decode('utf-8'))。
编码/解码错误处理:
在编码或解码过程中,如果遇到无法处理的字符或字节序列,Python会抛出 UnicodeEncodeError 或 UnicodeDecodeError。str.encode() 和 bytes.decode() 方法都接受一个 errors 参数来控制错误处理行为:
● ‘strict’ (默认):抛出错误。
● ‘ignore’:忽略无法处理的字符/字节。
● ‘replace’:用问号 ? 或其他占位符替换无法处理的字符/字节。
● ‘xmlcharrefreplace’ (仅编码):用XML字符引用替换。
● ‘backslashreplace’ (仅编码):用反斜杠转义序列替换。
当Python处理文件I/O或网络通信时,它必须在Unicode字符(str)和字节序列(bytes)之间进行转换。
● 写入文件: 当你向文件写入字符串时,Python会根据你指定的编码(或默认编码,通常是UTF-8)将字符串编码成字节序列,然后这些字节被写入到磁盘上。
● 读取文件: 当你从文件读取字节序列时,Python会根据你指定的编码(或默认编码)将这些字节解码成Unicode字符,然后返回一个字符串对象。
这种分离的设计(str 负责字符,bytes 负责字节)使得Python能够清晰地处理不同编码的文本,避免了Python 2 中字符串处理的混乱。
(1)字符串和字节串的基本转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 23:15
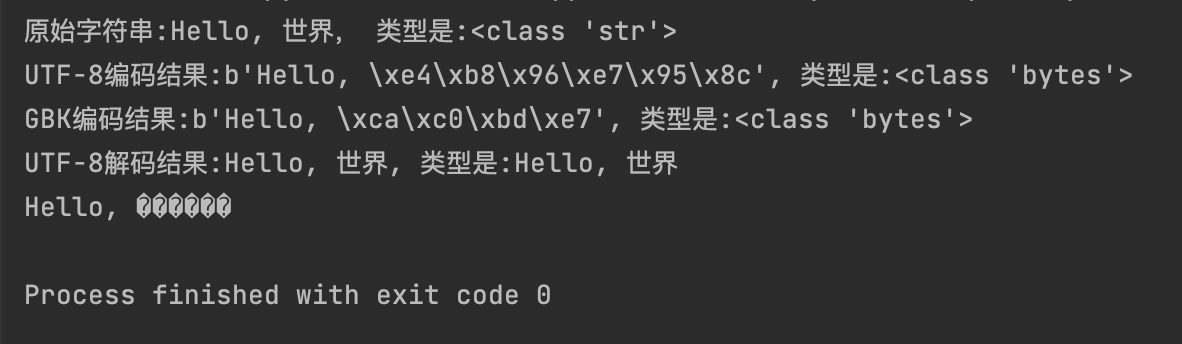
s = "Hello, 世界"
print(f"原始字符串:{s}, 类型是:{type(s)}")
# 编码 str --> bytes
b_utf8 = s.encode("utf-8")
print(f"UTF-8编码结果:{b_utf8}, 类型是:{type(b_utf8)}")
# 编码GBK
b_gbk = s.encode("gbk")
print(f"GBK编码结果:{b_gbk}, 类型是:{type(b_gbk)}")
# 解码
utf8_str = b_utf8.decode("utf-8")
print(f"UTF-8解码结果:{utf8_str}, 类型是:{utf8_str}")
try:
utf_error = b_utf8.decode("ascii", errors="replace")
print(utf_error)
except UnicodeDecodeError as e:
print(f"报错:{e}")
(2)习题1.1
给定一个字符串 s = "你好 World!"。
○ 尝试将其编码为 UTF-8 和 GBK 字节串,并打印出它们的长度和内容。
○ 将 UTF-8 字节串解码回字符串。
○ 将 GBK 字节串解码回字符串。
1
2
3
4
5
6
7
8
9
10
11
12
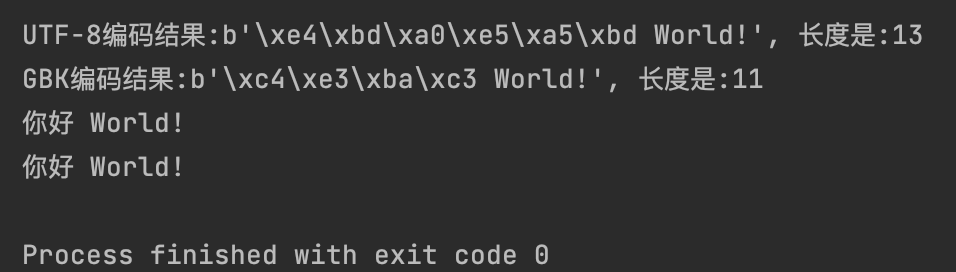
s = "你好 World!"
# 尝试将其编码为 UTF-8 和 GBK 字节串,并打印出它们的长度和内容。
b_utf_8 = s.encode("utf-8")
b_gbk = s.encode("gbk")
print(f"UTF-8编码结果:{b_utf_8}, 长度是:{len(b_utf_8)}")
print(f"GBK编码结果:{b_gbk}, 长度是:{len(b_gbk)}")
# 将 UTF-8 字节串解码回字符串。
s1 = b_utf_8.decode("utf-8")
print(s1)
# 将 GBK 字节串解码回字符串。
s2 = b_gbk.decode("gbk")
print(s2)
(3)习题1.2
给定一个包含特殊字符的字符串 s = "这是一个€符号和一些中文:你好"。
○ 尝试将其编码为 ASCII 格式,并分别使用 errors='strict'、errors='ignore' 和 errors='replace' 模式,观察并解释结果。
○ 将 errors='replace' 模式编码后的字节串再解码回字符串,观察结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
s = "这是一个€符号和一些中文:你好"
# 尝试将其编码为 ASCII 格式,并分别使用 errors='strict'、errors='ignore' 和 errors='replace' 模式,观察并解释结果。
try:
strict_encode = s.encode("ascii", errors="strict")
print(f"编码结果:{strict_encode}")
except UnicodeEncodeError as e:
print(f"报错:{e}")
try:
ignore_encode = s.encode("ascii", errors="ignore")
print(f"编码结果:{ignore_encode}")
except UnicodeEncodeError as e:
print(f"报错:{e}")
try:
replace_encode = s.encode("ascii", errors="replace")
print(f"编码结果:{replace_encode}")
# 将 errors='replace' 模式编码后的字节串再解码回字符串,观察结果。
res = replace_encode.decode("ascii")
print(res)
except UnicodeEncodeError as e:
print(f"报错:{e}")

2、文件的读写原理
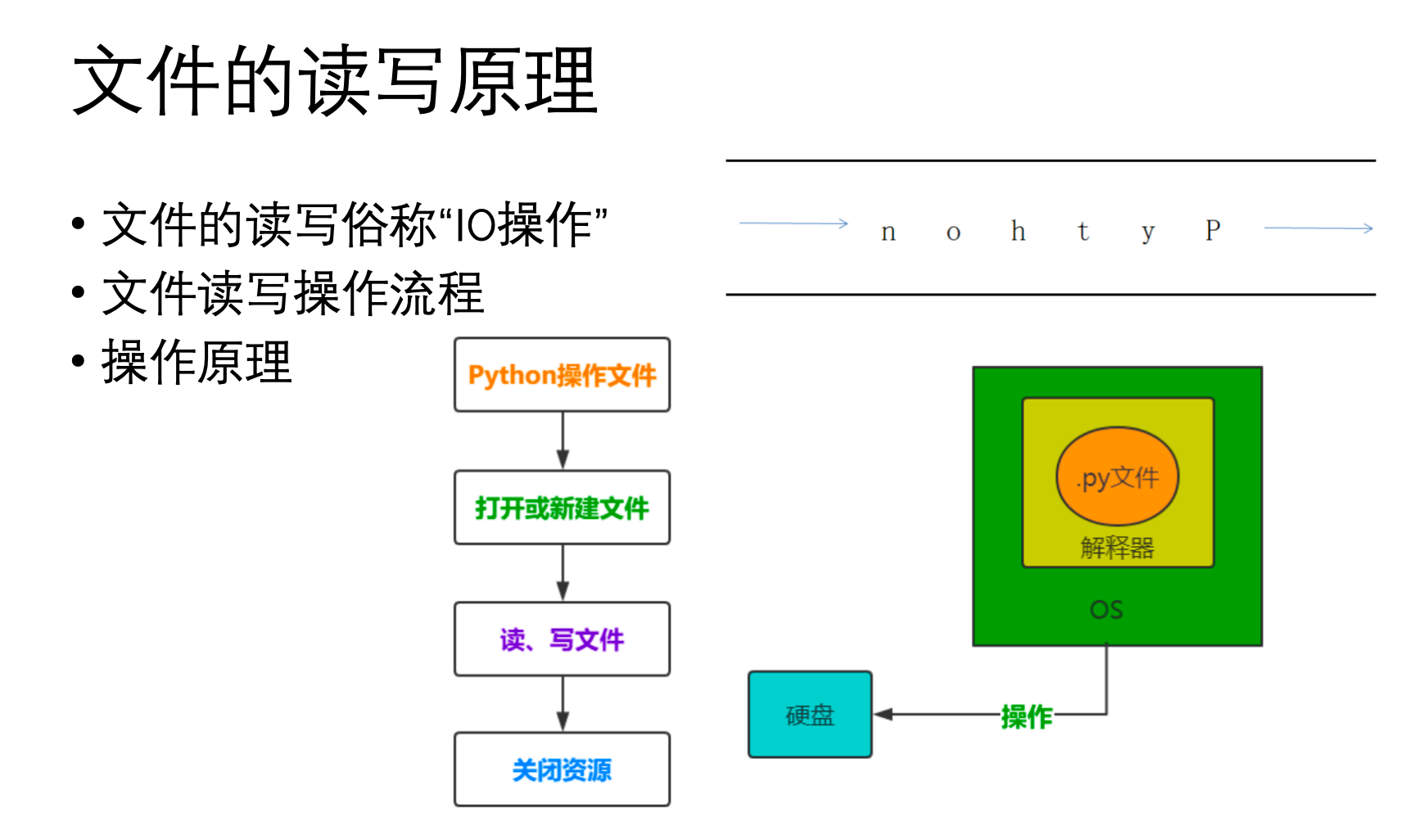
文件读写是程序与持久化存储(如硬盘)交互的过程。其核心原理涉及操作系统提供的文件句柄/描述符、缓冲区机制以及文本模式与二进制模式的区别。
当Python程序进行文件读写操作时,它并不是直接操作硬盘上的物理扇区,而是通过操作系统提供的服务来完成的。
- 文件句柄/文件描述符 (File Handle/File Descriptor): 当程序成功打开一个文件时,操作系统会返回一个整数标识符,称为文件描述符(在Unix/Linux系统中)或文件句柄(在Windows系统中)。这个标识符是程序与打开的文件之间的唯一关联。程序后续对文件的所有操作(读、写、定位、关闭)都通过这个句柄/描述符来引用文件,而不是直接使用文件名。这就像你拿到了一本书的“借书证”,后续所有关于这本书的操作都凭这张证进行。操作系统维护一个打开文件表,其中记录了每个文件描述符对应的文件信息(如文件路径、访问模式、当前读写位置等)。当程序请求读写时,操作系统根据文件描述符找到对应的文件,并执行I/O操作。
- 缓冲区 (Buffering): 缓冲区是内存中的一块临时存储区域。在文件I/O操作中,数据通常不会直接从应用程序写入硬盘,或直接从硬盘读取到应用程序。而是先经过缓冲区。当程序请求从文件读取数据时,操作系统通常会一次性读取比请求量更大的数据块到内存缓冲区中。下次程序再次请求读取时,如果所需数据已经在缓冲区中,就可以直接从内存获取,避免了较慢的磁盘I/O操作。当程序写入数据时,数据通常不会立即写入硬盘,而是先写入内存缓冲区。当缓冲区满、或者程序显式调用 flush()、或者文件被关闭时,缓冲区中的数据才会被“刷新”(flush)到硬盘上。
- 优点:减少了频繁的磁盘I/O操作(磁盘I/O比内存I/O慢得多),提高了读写效率。
- 缺点:写入的数据可能不会立即持久化到磁盘,存在数据丢失的风险(例如程序崩溃或断电)。
- 文本模式 (Text Mode) 与 二进制模式 (Binary Mode):这是Python open() 函数中的一个重要概念。
- 文本模式 (‘t’ 或默认):用于处理文本文件。在读写过程中会进行编码/解码转换。当你写入字符串时,它会根据指定的编码(或系统默认编码)将其转换为字节序列;当你读取字节序列时,它会根据编码将其解码为字符串。还会对换行符进行处理:在Windows上,
\n(LF)在写入时会自动转换为\r\n(CRLF),在读取时会将\r\n转换为\n。在Unix/Linux上,通常不进行这种转换。适合处理包含可读字符的文本文件(如 .txt, .csv, .json, .py 等) - 二进制模式 (‘b’): 用于处理非文本文件(如图片、视频、音频、可执行文件等)或需要精确控制字节流的文本文件。在读写过程中不会进行编码/解码转换,也不会对换行符进行特殊处理。数据以原始字节的形式进行读写。适合处理任何非文本数据,或者当你需要手动控制编码/解码过程时。
- 文本模式 (‘t’ 或默认):用于处理文本文件。在读写过程中会进行编码/解码转换。当你写入字符串时,它会根据指定的编码(或系统默认编码)将其转换为字节序列;当你读取字节序列时,它会根据编码将其解码为字符串。还会对换行符进行处理:在Windows上,
- 文件指针/文件游标 (File Pointer/File Cursor):每个打开的文件都有一个内部的文件指针,它指示了下一次读写操作将从文件的哪个位置开始。读写操作会自动移动文件指针。也可以使用
seek()方法显式地移动文件指针到文件的某个特定位置。
程序通过调用操作系统提供的API(如
open(),read(),write(),close()等系统调用)来与文件系统交互。操作系统负责管理文件在磁盘上的物理存储,并提供抽象层给应用程序。缓冲区机制在应用程序和操作系统之间充当一个中间层,优化了I/O性能。文本模式和二进制模式则是在Python层面对字节流进行解释和转换的两种不同策略。
(1)文本模式和二进制模式的区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 12:48
# 写入文件
with open("text_file.txt", "w", encoding="utf-8") as f:
f.write("Hello, World!\n")
f.write("你好,世界!\n")
# 读取文件(文本模式)
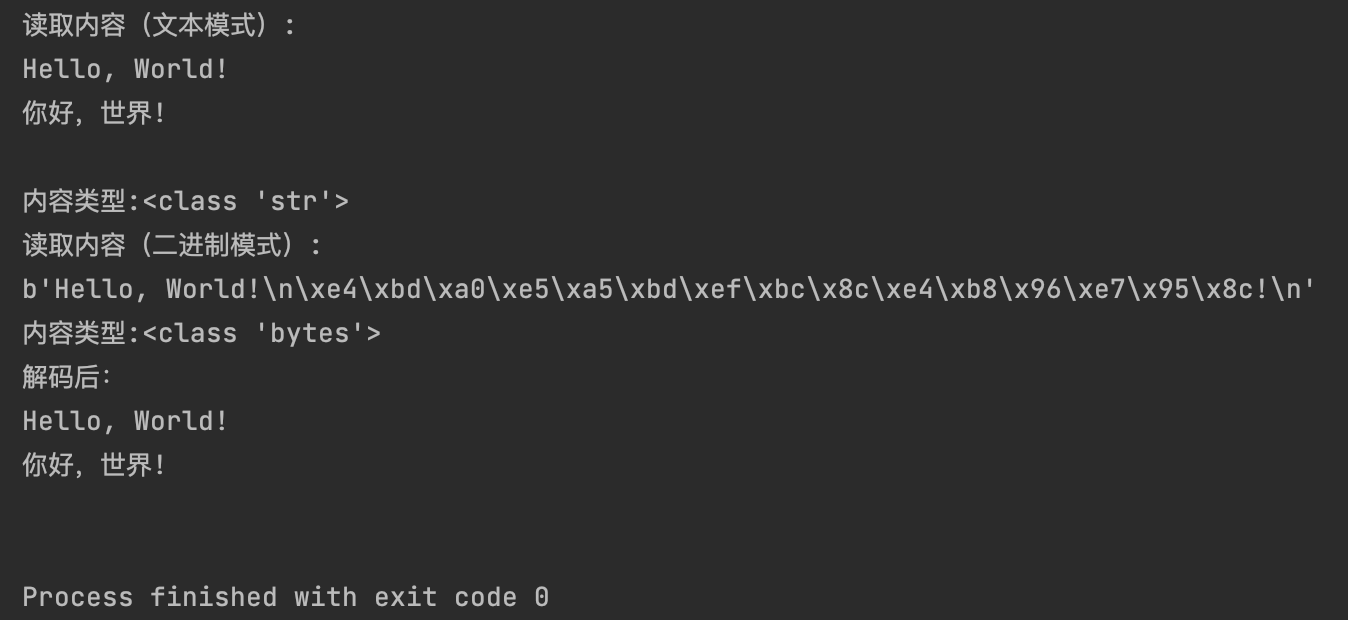
with open("text_file.txt", "r", encoding="utf-8") as f:
content = f.read()
print(f"读取内容(文本模式):\n{content}")
print(f"内容类型:{type(content)}") # str
# 读取文件(二进制模式)
with open("text_file.txt", "rb") as f: # 这里没有encoding参数
cont = f.read()
print(f"读取内容(二进制模式):\n{cont}")
print(f"内容类型:{type(cont)}") # bytes
decoded_cont = cont.decode("utf-8") # 解码
print(f"解码后:\n{decoded_cont}")
(2)二进制模式下写入非文本数据
1
2
3
4
5
with open("binary_data.bin", "wb") as f:
# 写入一些字节数据
f.write(b'\x00\x01\x02\xff')
f.write(bytes([65, 66, 67])) # A, B, C
print(f"二进制文件已经创建")
清理测试文件:
1
2
3
4
5
import os
if os.path.exists("text_file.txt"):
os.remove("text_file.txt")
if os.path.exists("binary_data.bin"):
os.remove("binary_data.bin")
习题2.1
解释为什么在处理图片、音频等文件时,必须使用二进制模式(’b’)而不是文本模式。如果强行使用文本模式会发生什么?
处理图片、音频等文件时,必须使用二进制模式(’b’),而不是文本模式。这是因为这些文件类型包含的是非文本数据,它们是字节序列,而不是由字符编码(如UTF-8、GBK等)构成的文本信息。
图片、音频、视频等文件在计算机内部存储的都是原始的字节数据。这些字节直接代表了像素颜色、声音波形等信息,它们没有像文本文件那样遵循任何字符编码规则。
当你在文本模式下打开文件时,Python(以及其他编程语言)会尝试使用一个字符编码(通常是系统默认编码,或者你指定的编码如
UTF-8)对读入或写入的字节进行自动编解码。如果这些字节不符合任何文本编码规则,那么自动编解码过程就会出错。文本模式下的编解码过程可能会修改或删除某些字节,例如:
- 行末转换: 在不同的操作系统中,文本文件的行结束符表示方式不同(Windows 是
\r\n,Unix/Linux 是\n)。文本模式下,系统可能会自动将\n转换为\r\n(写入时),或将\r\n转换为\n(读取时),这会破坏非文本文件的数据结构。- 编码错误: 遇到无法解码的字节序列时,可能会抛出
UnicodeDecodeError,或者根据错误处理策略(如errors='ignore'或errors='replace')跳过或替换这些字节,导致数据丢失或损坏。如果你强行使用文本模式(例如
open('image.jpg', 'r', encoding='utf-8')或open('audio.mp3', 'w', encoding='utf-8'))来处理图片或音频文件,通常会发生以下几种情况:
UnicodeDecodeError或UnicodeEncodeError: 这是最常见的情况。当你尝试以文本模式读取一个二进制文件时,Python 解释器会尝试将其字节流按照指定的(或默认的)文本编码进行解码。由于图片或音频的字节数据并不符合任何文本编码规范,它很可能会遇到无法识别的字节序列,从而抛出UnicodeDecodeError。同样,如果尝试以文本模式写入非字符串数据或格式错误的字符串,可能会遇到UnicodeEncodeError。- 文件损坏: 即使没有立即抛出错误,系统也可能在内部尝试进行不必要的行末符转换或其他字节操作。这会导致文件内容发生改变,从而损坏原始数据结构。结果就是,图片可能无法打开或显示乱码,音频文件无法播放或出现杂音。
- 行为不确定性: 某些情况下,你可能会读到一些看似“乱码”的字符串,或者写入一些看似成功的“乱码”文件。但实际上,这些操作都没有正确地处理二进制数据,文件已经无法正常使用。
在处理图片、音频、视频或任何其他非文本文件时,始终记住它们是字节流。为了确保数据完整性并避免不必要的编解码过程,务必使用二进制模式(
'rb'用于读取,'wb'用于写入)。
习题2.2
简述文件I/O中缓冲区的优点和潜在的风险。在什么情况下,你可能需要强制刷新缓冲区?
在文件I/O操作中,缓冲区是一个非常重要的概念。它就像一个临时存储区域,位于应用程序和实际物理存储设备(如硬盘)之间。当程序进行读写操作时,数据通常不会直接发送到硬盘,而是先进入这个缓冲区。
优点
- 提高效率(性能优化): 这是缓冲区最主要的优点。
- 减少I/O操作次数: 磁盘I/O操作(读写硬盘)通常比内存操作慢很多。通过缓冲区,程序可以积累一定量的数据后再进行一次性写入,或一次性读取大量数据到缓冲区,避免了频繁、零散的磁盘访问,从而显著提高读写效率。
- 匹配设备速度差异: 缓冲区可以协调CPU(或应用程序)与慢速I/O设备之间的速度差异。CPU可以快速地向缓冲区写入数据,然后继续执行其他任务,而无需等待数据完全写入磁盘;同样,从缓冲区读取数据也比直接从磁盘读取快。
- 数据吞吐量: 通过批处理(batching)数据,缓冲区增加了单位时间内可以处理的数据量,提升了系统的整体吞吐量。
潜在的风险
- 数据丢失风险: 这是最主要的风险。
- 如果程序在数据从缓冲区完全写入磁盘之前崩溃、断电或异常终止,缓冲区中的数据可能会丢失,导致数据不一致或损坏。
- 数据不一致性:
- 当多个程序或进程同时访问同一个文件时,由于数据可能存在于不同进程或操作系统的缓冲区中,而未及时同步到磁盘,可能导致它们读取到旧的数据,造成数据不一致的问题。
强制刷新缓冲区(flush)是指将缓冲区中的所有待写入数据立即写入到底层存储设备,而不管缓冲区是否已满。在以下情况下,你可能需要强制刷新缓冲区:
- 关键数据写入: 当你正在写入对数据完整性要求极高的关键信息时,例如数据库事务日志、配置文件、财务记录或任何程序状态数据。在这种情况下,即使系统崩溃,也希望已写入的数据能够持久化。
- 进程间通信: 当一个进程写入文件,并期望另一个进程能够立即读取到最新的数据时。如果数据停留在缓冲区而没有写入磁盘,其他进程将无法获取到最新的信息。
- 调试和日志记录: 在调试程序或写入重要日志信息时,你可能希望日志能够实时地写入文件,而不是等到缓冲区满或程序结束。这有助于在程序崩溃时捕获到最新的错误信息。
- 程序正常退出前: 虽然大多数文件I/O库在程序正常退出时会自动刷新缓冲区,但在某些特殊情况下(例如,为了确保数据在所有退出路径上都已保存),你可能希望在程序关闭前显式地刷新所有打开的文件缓冲区。
- 文件句柄关闭前: 在关闭文件句柄之前,通常不需要手动调用
flush(),因为close()方法在关闭文件时会隐式地执行刷新操作。然而,如果出于某种原因,你在关闭文件之前需要确保数据已写入,也可以显式调用。
3、文件读写操作
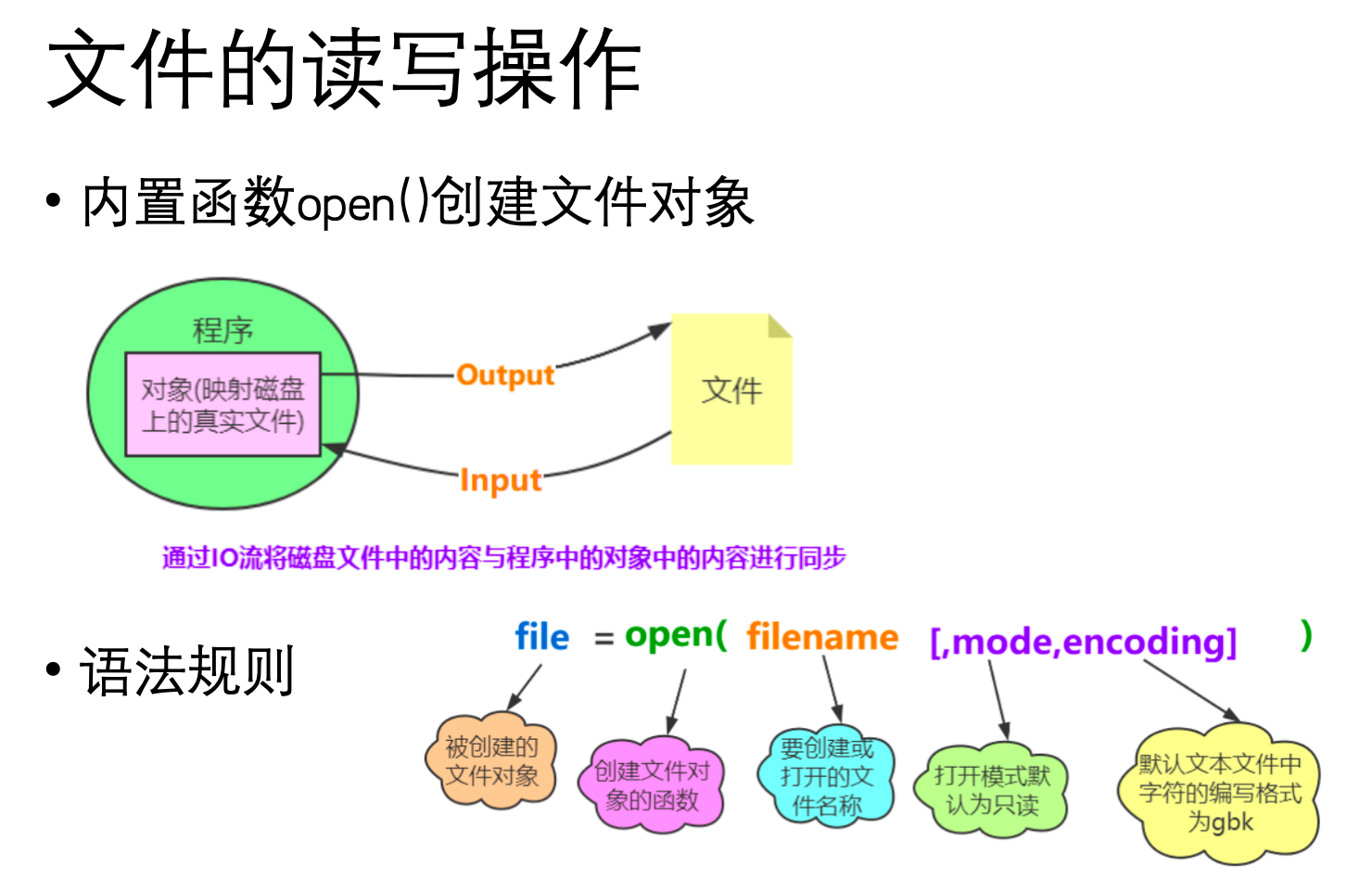
Python通过内置的 open() 函数来打开文件,并返回一个文件对象。文件对象提供了 read(), readline(), readlines() 用于读取,以及 write(), writelines() 用于写入数据。完成操作后,必须使用 close() 方法关闭文件。
(1)open函数
语法:
1
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
-
file: 必需参数,表示要打开的文件路径(可以是相对路径或绝对路径)
-
mode: 可选参数,指定文件打开模式。默认为 ‘r’ (只读文本模式)
-
核心模式:
■ ‘r’:只读(默认)。文件指针位于文件开头。如果文件不存在,抛出 FileNotFoundError。
■ ‘w’:只写。如果文件存在,会截断(清空)文件内容;如果文件不存在,则创建新文件。文件指针位于文件开头。
■ ‘a’:追加。如果文件存在,文件指针位于文件末尾,新内容会追加到文件末尾;如果文件不存在,则创建新文件。
■ ‘x’:独占创建。如果文件已存在,则抛出
FileExistsError。如果文件不存在,则创建并以写入模式打开。 -
组合模式:
■ ‘t’:文本模式(默认)。与 ‘r’, ‘w’, ‘a’, ‘x’ 结合使用,例如 ‘rt’, ‘wt’。
■ ‘b’:二进制模式。与 ‘r’, ‘w’, ‘a’, ‘x’ 结合使用,例如 ‘rb’, ‘wb’。
■
'+':读写模式。与 ‘r’, ‘w’, ‘a’, ‘x’ 结合使用,例如 ‘r+’ (读写,指针在开头),’w+’ (读写,清空文件),’a+’ (读写,指针在末尾)。
-
-
encoding: 仅在文本模式下有效,指定文件的编码格式(如 ‘utf-8’, ‘gbk’)。强烈建议显式指定编码,避免跨平台问题
-
errors: 仅在文本模式下有效,指定编码/解码错误处理方式(如 ‘strict’, ‘ignore’, ‘replace’)
(2)写入操作
○ file_object.write(string):
■ 向文件写入一个字符串(文本模式)或字节串(二进制模式)。
■ 返回写入的字符数(文本模式)或字节数(二进制模式)。
■ 不会自动添加换行符,需要手动添加 \n。
○ file_object.writelines(list_of_strings):
■ 接受一个字符串列表(或任何可迭代的字符串对象),将所有字符串写入文件。
■ 不会自动添加换行符,列表中的每个字符串需要包含换行符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 写入文件
try:
f = open("my_output.txt", "w", encoding="utf-8")
f.write("Hello, Python!!!\n")
f.write("This is the first line.\n")
f.close() # 必须关闭文件
print("my_output.txt已经创建并写入内容...")
except IOError as e:
print(f"写入文件发生异常:{e}")
# 追加
try:
f = open("my_output.txt", "a", encoding="utf-8")
f.write("这行是追加的...\n")
f.write("这行也是追加的...\n")
f.close()
print("追加内容已经写入my_output.txt...")
except IOError as e:
print(f"追加内容出现报错:{e}")

下面是读写图片的例子:
1
2
3
4
5
f1 = open("albert.jpg", "rb")
f2 = open("albert_copy.jpg", "wb")
f2.write(f1.read())
f2.close()
f1.close()
(3)读取操作
○ file_object.read(size=-1):
■ size 为可选参数。如果省略或为负数,则读取文件所有内容。
■ 如果 size 为正数,则读取指定数量的字符(文本模式)或字节(二进制模式)。
■ 文件指针会移动到读取结束的位置。
○ file_object.readline(size=-1):
■ 读取文件的一行内容,包括行尾的换行符 \n。
■ 如果 size 存在,则最多读取 size 个字符/字节。
■ 当到达文件末尾时,返回空字符串 ‘‘。
○ file_object.readlines():
■ 读取文件所有行,并将每行作为一个字符串元素存储在列表中返回。
■ 每个字符串元素都包含行尾的换行符 \n。
○ 迭代文件对象: 文件对象本身是可迭代的,可以直接在 for 循环中逐行读取文件,这种方式效率最高。
例子1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
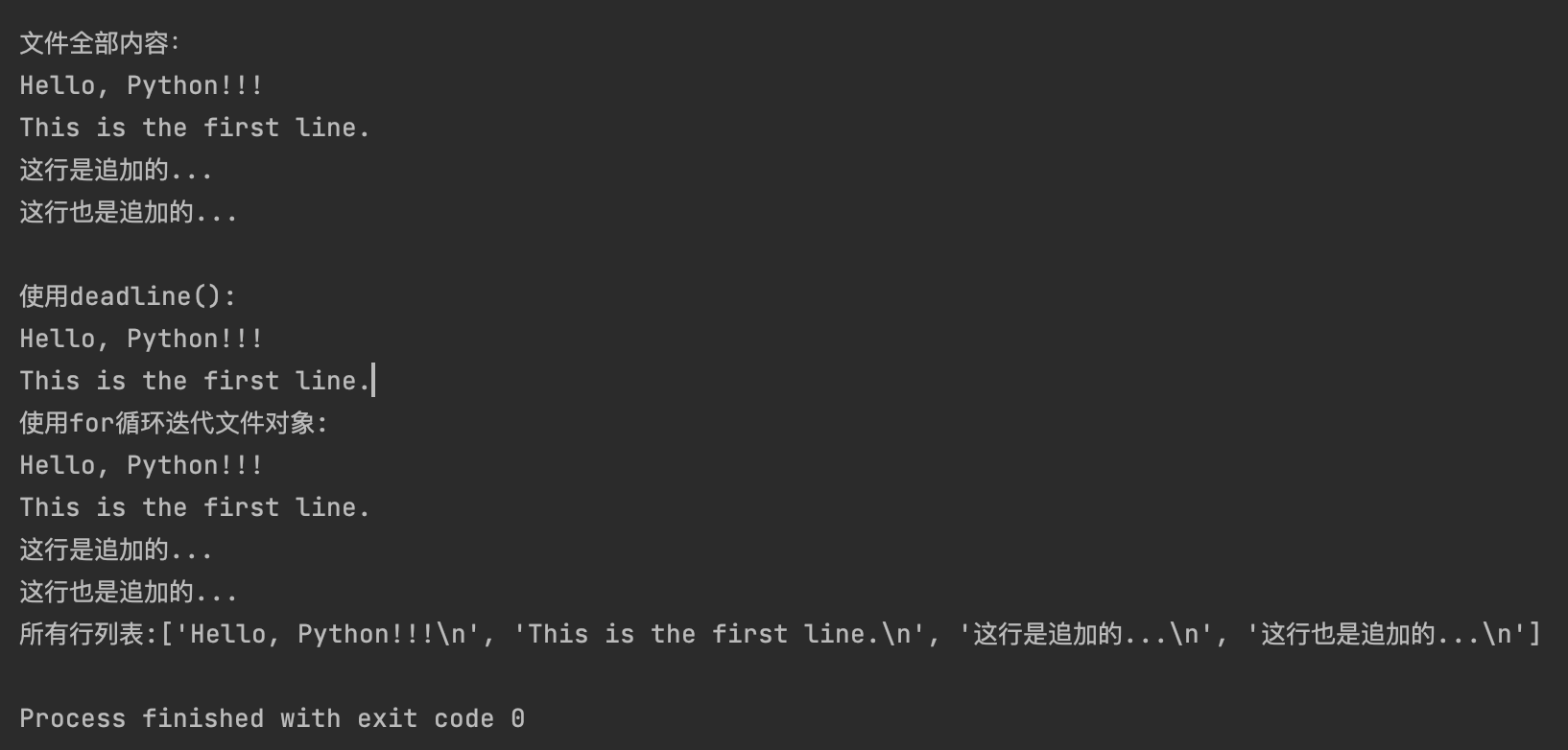
# 读取文件 r模式
try:
f = open("my_output.txt", "r", encoding="utf-8")
content_all = f.read()
print("文件全部内容:")
print(content_all)
f.close()
except FileNotFoundError as e:
print(f"文件不存在,报错:{e}")
except IOError as e:
print(f"文件读取发生异常:{e}")
# 逐行读取
try:
f = open("my_output.txt", "r", encoding="utf-8")
print("使用deadline():")
print(f.readline(), end = "") # 读取第一行
print(f.readline(), end = "") # 读取第二行
f.close()
print("使用for循环迭代文件对象:")
f = open("my_output.txt", "r", encoding="utf-8")
for line in f:
print(line, end='') # line已经包含换行符
f.close()
except IOError as e:
print(f"文件读取发生异常:{e}")
# 读取所有文件内容到列表中
try:
f = open("my_output.txt", "r", encoding="utf-8")
lines = f.readlines()
print(f"所有行列表:{lines}")
f.close()
except IOError as e:
print(f"文件读取发生异常:{e}")
例子2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 15:10
# 读写模式 r+ w+(清空文件)
with open("r_plus_w_plus.txt", "w+", encoding="utf-8") as f:
f.write("First line for w+\n")
f.write("Second line for w+\n")
f.seek(0) # 将文件指针移到开头
content = f.read()
print(f"w+模式写入后读取内容:\n{content}")
# r+模式不会清空文件,但是 文件必须存在
with open("r_plus_w_plus.txt", "r+", encoding='utf-8') as f:
print(f"\n r+初始内容:\n{f.read()}")
f.write("r+ 追加内容...") # 写入到文件末尾
f.seek(0) # 再次移动到开头
print(f"r+模式追加后读取:\n{f.read()}")

(4)关闭文件
○ file_object.close():
■ 释放文件句柄,将缓冲区中所有未写入的数据刷新到磁盘。
■ 重要性: 忘记关闭文件可能导致数据丢失、资源泄露、文件损坏或文件被其他程序锁定。
■ 推荐: 始终使用 with 语句来自动管理文件的打开和关闭。
文件读写操作的原理是基于操作系统提供的文件I/O系统调用。Python的 open() 函数是对这些系统调用的封装。
● 写入: 当调用 write() 时,Python会将数据发送给操作系统。操作系统会将数据放入内核缓冲区,并最终写入磁盘。
● 读取: 当调用 read() 时,Python会向操作系统请求数据。操作系统从磁盘读取数据到内核缓冲区,再传输给Python的应用程序缓冲区,最终返回给程序。
● close(): 调用 close() 会强制操作系统将所有待写入的缓冲区数据刷新到磁盘,并释放文件句柄,解除文件锁定。
1
2
3
4
5
6
# 清理测试文件
import os
if os.path.exists("my_output.txt"):
os.remove("my_output.txt")
if os.path.exists("r_plus_w_plus.txt"):
os.remove("r_plus_w_plus.txt")
习题3.1
创建一个名为 my_log.txt 的文件。
○ 向文件中写入三行日志信息,每行包含当前时间戳和一条消息(例如 [2025-07-09 10:00:00] - Application started.)。
○ 然后,以追加模式向文件中再写入两行新的日志信息。
○ 最后,读取整个文件内容并打印出来。
参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from datetime import datetime
def getTimeAndMsg():
now = datetime.now()
return now.strftime("[%Y-%m-%d %H:%M:%S] - Application started.\n")
with open("my_log.txt", "w", encoding="utf-8") as f:
# 向文件中写入三行日志信息,每行包含当前时间戳和一条消息(例如` [2025-07-09 10:00:00] - Application started.`)。
for i in range(3):
f.write(getTimeAndMsg())
f.close()
# 以追加模式向文件中再写入两行新的日志信息
with open("my_log.txt", "a", encoding="utf-8") as f :
f.write(getTimeAndMsg())
f.write(getTimeAndMsg())
f.close()
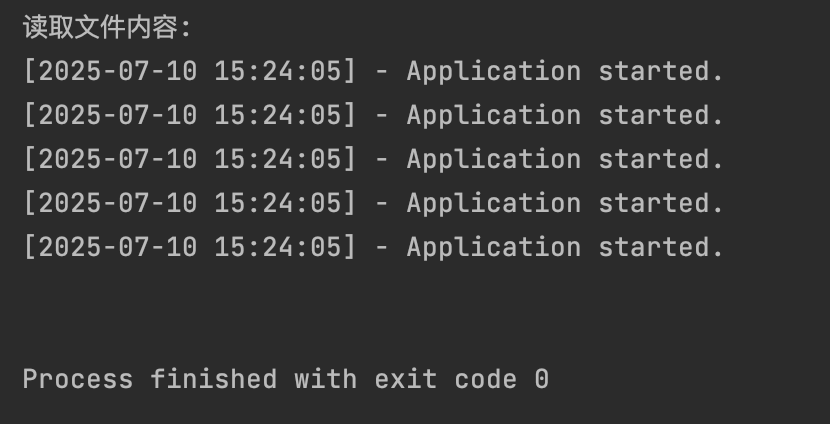
with open("my_log.txt", "r", encoding="utf-8") as f:
# 读取整个文件内容并打印出来。
print(f"读取文件内容:\n{f.read()}")
f.close()
习题3.2
编写一个函数 count_lines(filepath),接收文件路径作为参数。
○ 该函数应打开文件并逐行读取,统计文件中的总行数,并返回该数量。
○ 如果文件不存在,捕获 FileNotFoundError 并返回 -1。
○ 使用 with 语句来确保文件正确关闭。
参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def count_lines(filepath):
"""
打开文件并逐行读取,统计文件中的总行数,并返回该数量
使用 with 语句来确保文件正确关闭。
"""
try:
with open(filepath, "r", encoding="utf-8") as f:
line_count = 0
for line in f:
line_count += 1
return line_count
# 如果文件不存在,捕获 FileNotFoundError 并返回 -1。
except FileNotFoundError as e:
print(f"文件不存在, 报错:{e}")
return -1
# 测试
print(count_lines("my_log.txt"))
print(count_lines("myLog.txt"))

4、文件对象常用的方法

除了基本的读写方法,文件对象还提供了一些其他有用的方法来控制文件指针的位置、强制数据写入磁盘以及检查文件状态。
file_object.tell():
○ 作用: 返回文件当前读写位置的偏移量(以字节为单位)。这个偏移量是从文件开头算起的。
○ 原理: 文件指针是操作系统在内部维护的一个计数器,指示了下一次I/O操作的起始位置。tell() 方法就是查询这个计数器的当前值。在文本模式下,返回值可能不是简单的字节数,因为它会考虑编码转换和换行符处理。
file_object.seek(offset, whence=0):
○ 作用: 改变文件当前读写位置。
○ offset: 偏移量,表示要移动的字节数。
○ whence: 可选参数,指定偏移的起始位置:
■ 0 (或 os.SEEK_SET):默认值,从文件开头开始偏移。offset 必须是正数或零。
■ 1 (或 os.SEEK_CUR):从当前位置开始偏移。offset 可以是正数(向前)或负数(向后)。
■ 2 (或 os.SEEK_END):从文件末尾开始偏移。offset 通常是负数(向文件开头移动),或者为零(移动到文件末尾)。
○ 注意: 在文本模式下使用 seek() 可能会比较复杂,因为它涉及到编码和解码。通常,在文本模式下,seek() 只能用于移动到 tell() 返回的有效位置,或者移动到文件开头 (seek(0))。对于精确的字节定位,推荐使用二进制模式。
○ 原理: seek() 方法会向操作系统发出指令,更新文件句柄内部的文件指针计数器。
file_object.flush():
○ 作用: 强制将内部缓冲区中所有未写入的数据立即写入到磁盘(或操作系统缓冲区)。
○ 原理: 通常,Python的I/O操作会先将数据写入内存缓冲区,待缓冲区满或文件关闭时再写入磁盘。flush() 绕过了这个等待机制,强制进行一次物理写入操作。这在需要确保数据及时持久化(例如,在程序崩溃前保存关键数据)时非常有用。
file_object.readable() / writable() / seekable():
○ 作用: 这些方法返回布尔值,指示文件对象是否支持相应的操作。
○ readable():如果文件可以读取,返回 True。
○ writable():如果文件可以写入,返回 True。
○ seekable():如果文件支持随机访问(即支持 seek() 操作),返回 True。
○ 原理: 这些方法检查文件对象的内部状态和打开模式,以确定文件句柄是否被赋予了相应的权限或能力。
file_object.name / mode / closed 属性:
○ 作用: 这些是文件对象的只读属性,提供文件的元数据。
○ name:返回文件的名称(路径)。
○ mode:返回文件打开时使用的模式(如 ‘r’, ‘w+’, ‘rb’)。
○ closed:如果文件已关闭,返回 True;否则返回 False。
例子1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 15:45
# 准备一个测试文件:
with open("seek_test.txt", "w", encoding="utf-8") as f:
f.write("Hello, world!\n")
f.write("Python is great!\n")
f.write("Line 3, end of line.\n")
with open("seek_test.txt", "r+", encoding="utf-8") as f:
print(f"文件名称:{f.name}")
print(f"打开模式:{f.mode}")
print(f"文件是否关闭:{f.closed}")
print(f"文件是否可读:{f.readable()}")
print(f"文件是否可写:{f.writable()}")
print(f"文件是否可查找:{f.seekable()}")
# 获取当前位置
current_pos = f.tell()
print(f"\n初始文件指针位置:{current_pos}字节")
# 读取一行,文件指针会移动
first_line = f.readline()
print(f"读取第一行:{first_line}")
current_pos = f.tell()
print(f"\n读取一行后文件指针位置:{current_pos}字节")
# seek改变文件位置
f.seek(0) # 移动到文件开头
print(f"seek(0)之后文件指针位置是:{f.tell()}字节")
print(f"从开头读取:{f.readline().strip()}")
# 从文件开头偏移7个字节
f.seek(7, 0)
print(f"seek(7,0)后 文件指针位置:{f.tell()}字节")
print(f"从偏移7处读取:{f.readline().strip()}")
# 从文件末尾向前偏移10个字节(二进制模式下更准确)
f.close()
with open("seek_test.txt", "rb") as bf:
bf.seek(-10, 2)
print(f"二进制模式下seek(-10, 2)后的位置:{bf.tell()}字节")
print(f"末尾偏移10处读取(二进制):{bf.read().decode('utf-8').strip()}")

例子2:flush
1
2
3
4
5
6
7
8
9
10
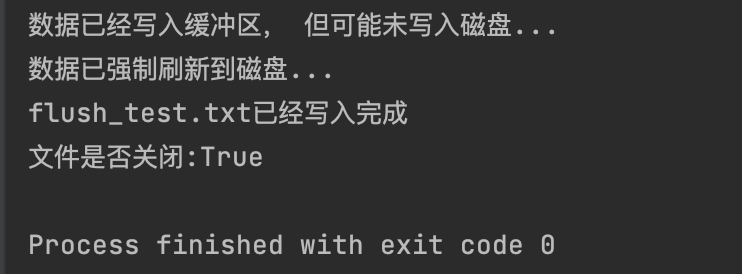
# flush
with open("flush_test.txt", "w", encoding="utf-8") as f:
f.write("This is buffer...")
print("数据已经写入缓冲区, 但可能未写入磁盘...")
f.flush()
print("数据已强制刷新到磁盘...")
# 此时就算程序崩溃,这行数据也已经被保存了
f.write("这是flush之后的数据")
print("flush_test.txt已经写入完成")
print(f"文件是否关闭:{f.closed}") # True, 因为with语句自动关闭了
5、with语句(上下文管理器)
with 语句是Python中处理资源(如文件、网络连接、锁)的推荐方式。它确保资源在使用后被正确地获取和释放,即使在代码块执行过程中发生异常。
在没有 with 语句之前,我们通常需要使用 try...finally 结构来确保文件在操作完成后被关闭, 例如:
1
2
3
4
5
6
7
8
9
10
11
12
f = None
try:
f = open("my_file.txt", "r")
content = f.read()
# 其他操作
except FileNotFoundError as e:
print(f"文件未找到:{e}")
except Exception as e:
print(f"发生异常:{e}")
finally:
if f:
f.close()
这种模式虽然有效,但是代码冗长,且容易出错(例如忘记if f:检查)。
with 语句提供了一种更简洁、更安全的方式来管理资源。
1
2
3
with expression as variable:
# 在这里使用资源 (variable)
# 代码块结束或发生异常时,资源会自动释放
● with 语句要求 expression 返回一个上下文管理器 (Context Manager) 对象。上下文管理器是实现了两个特殊方法(“魔术方法”)的对象:
○ __enter__(self):
■ 在进入 with 语句块时被调用。
■ 它负责设置资源(例如打开文件、获取锁)。
■ 它的返回值(如果有)会被赋给 as 关键字后面的 variable。
○ __exit__(self, exc_type, exc_val, exc_tb):
■ 在退出 with 语句块时被调用,无论代码块是正常结束还是因为异常而退出。
■ 它负责清理资源(例如关闭文件、释放锁)。
■ exc_type, exc_val, exc_tb 分别表示异常类型、异常值和回溯信息。如果 with 块中没有发生异常,这三个参数都将是 None。
■ 如果 __exit__ 方法返回 True,表示它已经处理了异常,异常不会继续传播。如果返回 False 或 None,则异常会继续传播。
open() 函数作为上下文管理器:
Python内置的 open() 函数返回的文件对象就是一个上下文管理器。它内部实现了 __enter__ 和 __exit__ 方法:
● enter:打开文件并返回文件对象本身。
● exit:确保文件被关闭,无论 with 块中发生什么。
自定义上下文管理器:
除了文件对象,你也可以为自己的类实现 enter 和 exit 方法,使其成为上下文管理器,从而管理任何需要设置和清理的资源。
contextlib 模块:
对于简单的上下文管理器,可以使用 contextlib 模块中的 @contextmanager 装饰器,通过一个生成器函数来创建上下文管理器,避免编写完整的类。
with 语句的底层原理是Python解释器在编译时识别这种结构,并将其转换为等效的
try...finally块。当解释器遇到
with expression as variable:时,它会:
调用 expression 返回的上下文管理器对象的
__enter__()方法。将
__enter__()方法的返回值赋给 variable。执行 with 块中的代码。
无论 with 块中的代码是正常执行完毕,还是因为
return,break,continue语句,或者因为异常而退出,finally 机制都会确保上下文管理器对象的__exit__()方法被调用。如果 with 块中发生了异常,该异常的详细信息会作为参数传递给
__exit__()方法。__exit__()可以选择处理这个异常(返回 True)或让它继续传播(返回 False 或 None)。这种机制提供了一种强大的抽象,使得资源管理变得自动化和安全。
(1)使用with语句进行文件读写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 17:07
try:
with open("my_safe_file.txt", "w", encoding="utf-8") as f:
f.write("这是用with语句的写入文件操作...")
f.write("这个文件会被自动关闭...")
# 不需要f.close()
print("my_safe_file.txt已经创建并写入,并自动关闭...")
with open("my_safe_file.txt", "r", encoding="utf-8") as f:
content = f.read()
print(f"读取内容:\n{content}")
print("my_safe_file.txt已经读取,并且自动关闭...")
# 模拟一个异常,即使发生异常,文件也会关闭
with open("error.txt", "w", encoding="utf-8") as f:
f.write("This line is written...")
raise ValueError("模拟一个异常发生...")
f.write("这行不会被写...")
except ValueError as e:
print(f"捕获到异常:{e}, 文件仍然会被关闭...")
finally:
# 验证文件是否关闭, 实际上在with语句块结束后,文件对象,无法验证closed属性
# 但是可以通过尝试打开来间接验证
try:
with open("error.txt") as f:
print(f"error.txt仍然可以被访问(已关闭并释放)...")
except Exception as e:
print(f"无法访问:{e}")

(2)自定义上下文管理器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 17:16
class MyResource:
def __init__(self, name):
self.name = name
self.is_open = False
def __enter__(self):
"""
进入with语句块时,被调用
"""
print(f"正在获取资源{self.name}。。。")
self.is_open = True
return self # 返回自身,赋给as后的变量
def __exit__(self, exc_type, exc_val, exc_tb):
"""
退出with块时,会被调用
"""
print(f"资源{self.name}正在被释放...")
self.is_open = False
if exc_type:
print(f"在{self.name}内部发生了异常:{exc_type.__name__}:{exc_val}")
return True # 如果返回True 异常会被意志,不会向外传播
print(f"资源{self.name}已经释放...")
return False # 返回False或者None 异常会被继续传播
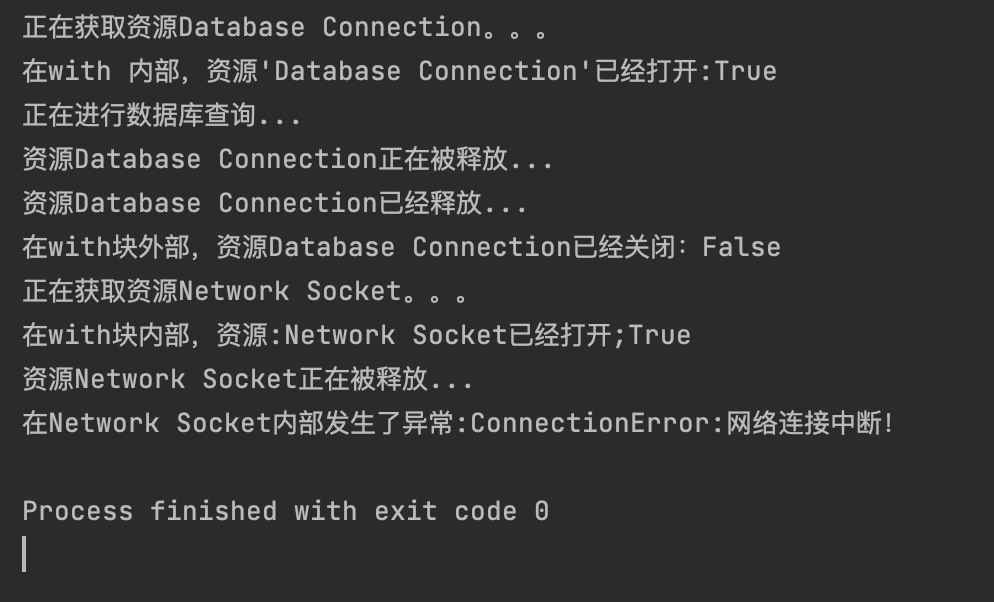
with MyResource("Database Connection") as db_conn:
print(f"在with 内部,资源'{db_conn.name}'已经打开:{db_conn.is_open}")
# 模拟一些操作
print(f"正在进行数据库查询...")
print(f"在with块外部,资源{db_conn.name}已经关闭:{db_conn.is_open}")
# 演示异常情况下的上下文管理器
try:
with MyResource("Network Socket") as net_sock:
print(f"在with块内部,资源:{net_sock.name}已经打开;{net_sock.is_open}")
raise ConnectionError("网络连接中断!") # 模拟异常
except ConnectionError as e:
print(f"在外部捕获到异常:{e}")
(3)使用contextlib里的装饰器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/10 17:46
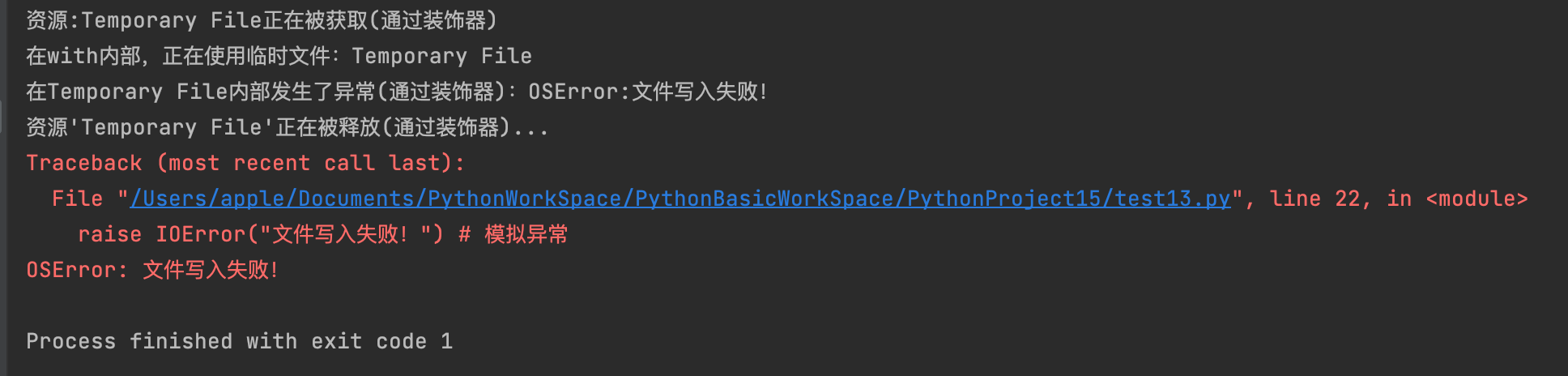
import contextlib
@contextlib.contextmanager
def managed_resource(name):
print(f"资源:{name}正在被获取(通过装饰器)")
try:
yield name # yield 是__enter__的逻辑,yield的值是as后的变量
except Exception as e:
print(f"在{name}内部发生了异常(通过装饰器):{type(e).__name__}:{e}")
# 异常处理逻辑,如果不想传播异常,这里可以不re raise
raise # 如果要重新抛出异常
finally:
print(f"资源'{name}'正在被释放(通过装饰器)...")
with managed_resource("Temporary File") as temp_file:
print(f"在with内部,正在使用临时文件:{temp_file}")
# 模拟文件操作
raise IOError("文件写入失败!") # 模拟异常
习题
创建一个自定义上下文管理器 FileLocker,用于模拟文件锁定。
○ 在 __enter__ 方法中打印“文件已锁定”,并返回一个表示锁定状态的字符串。
○ 在 __exit__ 方法中打印“文件已解锁”。
○ 使用 with FileLocker("report.txt") as lock: 结构来模拟对 report.txt 文件的锁定,并在 with 块内部打印“正在写入报告…”。
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/12 15:19
class FileLocker:
def __init__(self, filename):
self.filename = filename
self.locked = False # 文件没有锁定
# 进入with语句时
def __enter__(self):
self.locked = True
print(f"文件:{self.filename}已锁定")
# 返回一个表示锁定状态的字符串
return "locked"
# 出with语句块时
def __exit__(self, exc_type, exc_val, exc_tb):
self.locked = False
print(f"文件:{self.filename}已解锁")
# 测试
# 使用 `with FileLocker("report.txt") as lock: `结构来模拟对 report.txt 文件的锁定,并在 with 块内部打印“正在写入报告...”。
with FileLocker("report.txt") as lock:
print(f"---- 正在写入报告...")

6、目录操作
Python的 os 模块提供了与操作系统交互的功能,包括文件和目录的创建、删除、重命名、遍历等。os.path 模块则专门用于处理路径相关的操作,而 shutil 模块提供了更高级的文件和目录操作。
os 模块是Python标准库中用于与操作系统进行交互的核心模块。它提供了大量函数来执行文件系统操作、进程管理、环境变量访问等。
(1)获取当前工作目录:
○ os.getcwd():返回当前工作目录的字符串路径。
○ 原理: 调用操作系统的 getcwd() 或类似系统调用。
(2)改变当前工作目录:
○ os.chdir(path):将当前工作目录更改为 path。
○ 原理: 调用操作系统的 chdir() 或类似系统调用。
1
2
3
4
5
6
7
8
9
10
import os, shutil
# 1.获取和改变当前工作目录
# 创建一个临时的目录
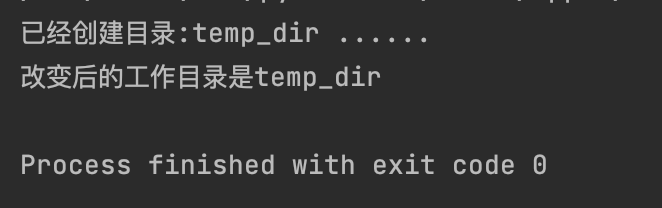
if not os.path.exists("temp_dir"):
os.mkdir("temp_dir")
print(f"已经创建目录:temp_dir ......")
# 改变当前工作目录
os.chdir("temp_dir")
print("改变后的工作目录是temp_dir")
(3)创建目录:
○ os.mkdir(path, mode=0o777):创建单个目录。如果目录已存在,抛出 FileExistsError。
○ os.makedirs(path, mode=0o777, exist_ok=False):递归创建目录(即可以创建多级目录)。
■ exist_ok=True:如果目录已存在,则不抛出错误。
○ 原理: 调用操作系统的 mkdir() 或类似系统调用。makedirs 会在内部循环调用 mkdir。
(4)删除目录:
○ os.rmdir(path):删除空目录。如果目录不为空,抛出 OSError。
○ os.removedirs(path):递归删除空目录。如果子目录被删除后,父目录也变为空,则会继续删除父目录。
○ 原理: 调用操作系统的 rmdir() 或类似系统调用。
1
2
3
4
5
6
7
8
9
10
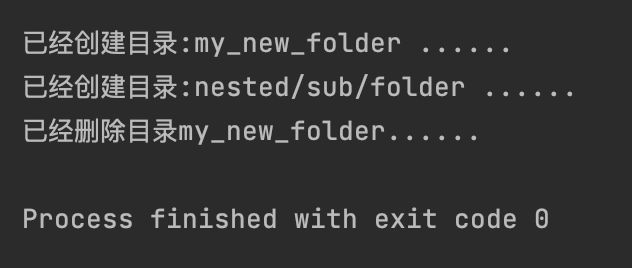
# 创建和删除目录:
os.mkdir("my_new_folder")
print(f"已经创建目录:my_new_folder ......")
# 创建多级目录
os.makedirs("nested/sub/folder", exist_ok=True) # `exist_ok=True`:如果目录已存在,则不抛出错误
print(f"已经创建目录:nested/sub/folder ......")
# 只能删除空目录
os.rmdir("my_new_folder")
print("已经删除目录my_new_folder......")
(5)列出目录内容:
○ os.listdir(path='.'):返回指定路径下所有文件和目录的名称列表。不包含 . 和 ..。
○ 原理: 调用操作系统的 readdir() 或类似系统调用。
1
2
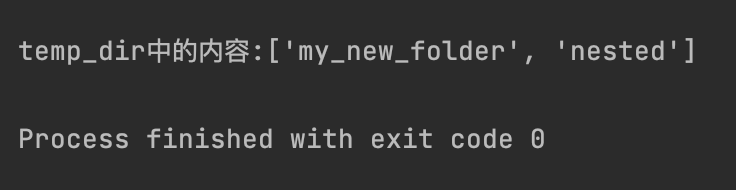
# 列出目录内容:
print(f"temp_dir中的内容:{os.listdir('.')}")
(6)重命名文件或目录:
○ os.rename(src, dst):将文件或目录 src 重命名为 dst。
○ 原理: 调用操作系统的 rename() 或类似系统调用。
1
2
3
4
5
6
7
8
9
import os
# 改变当前工作目录
os.chdir("temp_dir")
# 创建一个文件存在temp_dir中
with open("test_file.txt", "w") as f:
f.write("Hello from test_file.txt...")
# 重命名文件或者目录
os.rename("test_file.txt", "renamed_file.txt")
(7)删除文件:
○ os.remove(path):删除指定路径的文件。
○ 原理: 调用操作系统的 unlink() 或 remove() 系统调用。
1
2
os.remove("renamed_file.txt")
print("renamed_file.txt已经删除")
(8)os.path 模块 (路径操作):
○ os.path.join(path1, path2, ...):智能地拼接路径,自动处理斜杠。
○ os.path.abspath(path):返回路径的绝对路径。
○ os.path.basename(path):返回路径的最后一部分(文件名或目录名)。
○ os.path.dirname(path):返回路径的目录部分。
○ os.path.exists(path):检查路径是否存在。
○ os.path.isfile(path):检查路径是否是文件。
○ os.path.isdir(path):检查路径是否是目录。
○ os.path.split(path):将路径分割为 (dirname, basename)。
○ os.path.splitext(path):将路径分割为 (root, ext)。
○ 原理: 这些函数主要进行字符串操作和路径解析,不涉及实际的文件系统I/O,但它们遵循操作系统特定的路径约定。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
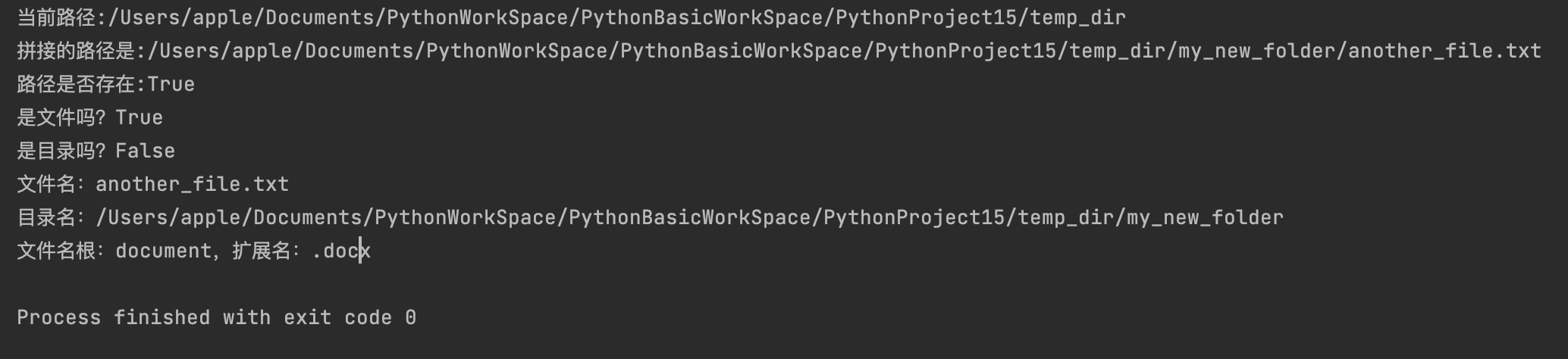
import os
# 改变当前工作目录
os.chdir("temp_dir")
current_path = os.getcwd()
print(f"当前路径:{current_path}")
# 路径拼接
full_path = os.path.join(current_path, "my_new_folder", "another_file.txt")
print(f"拼接的路径是:{full_path}")
print(f"路径是否存在:{os.path.exists(full_path)}")
print(f"是文件吗?{os.path.isfile(full_path)}")
print(f"是目录吗?{os.path.isdir(full_path)}")
print(f"文件名:{os.path.basename(full_path)}")
print(f"目录名:{os.path.dirname(full_path)}")
root, ext = os.path.splitext("document.docx")
print(f"文件名根:{root},扩展名:{ext}")
(9)shutil 模块 (高级文件操作):
○ shutil.copy(src, dst):复制文件。
○ shutil.copytree(src, dst):递归复制目录树。
○ shutil.move(src, dst):移动文件或目录。
○ shutil.rmtree(path):递归删除目录及其所有内容(非常危险,慎用!)。
○ 原理: shutil 模块通常在内部调用 os 模块的底层函数,但提供了更高级、更方便的接口来执行复杂的文件系统操作,例如处理目录的递归复制或删除。
7.os模块打开应用程序
1
2
import os
os.system("open /System/Applications/Calculator.app")
如果是windows:
1
2
import os
os.system("calc.exe")
或者打开可执行文件:(只适用于windows)
1
os.startfile()
8.递归遍历打印文件tree
1
2
3
4
5
6
7
8
import os
current_path = os.getcwd()
lst_files = os.walk(current_path)
for dirpath, dirname, filename in lst_files:
print(dirpath)
print(dirname)
print(filename)
print("=======")
得到输出是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15
['temp_dir']
['test10].py', 'test19.py', 'test09.py', 'test18.py', 'text04.py', 'test08.py', 'albert.jpg', 'test17.py', 'test07.py', 'test13.py', 'test03.py', 'test12.py', 'test02.py', 'my_safe_file.txt', 'test16.py', 'test06.py', 'test11.py', 'test01.py', 'test15.py', 'test05.py', 'test14.py', 'my_log.txt', 'albert_copy.jpg', 'error.txt']
=======
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir
['my_new_folder', 'nested']
[]
=======
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/my_new_folder
[]
['another_file.txt']
=======
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested
['sub']
[]
=======
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested/sub
['folder']
[]
=======
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested/sub/folder
[]
[]
=======
Process finished with exit code 0
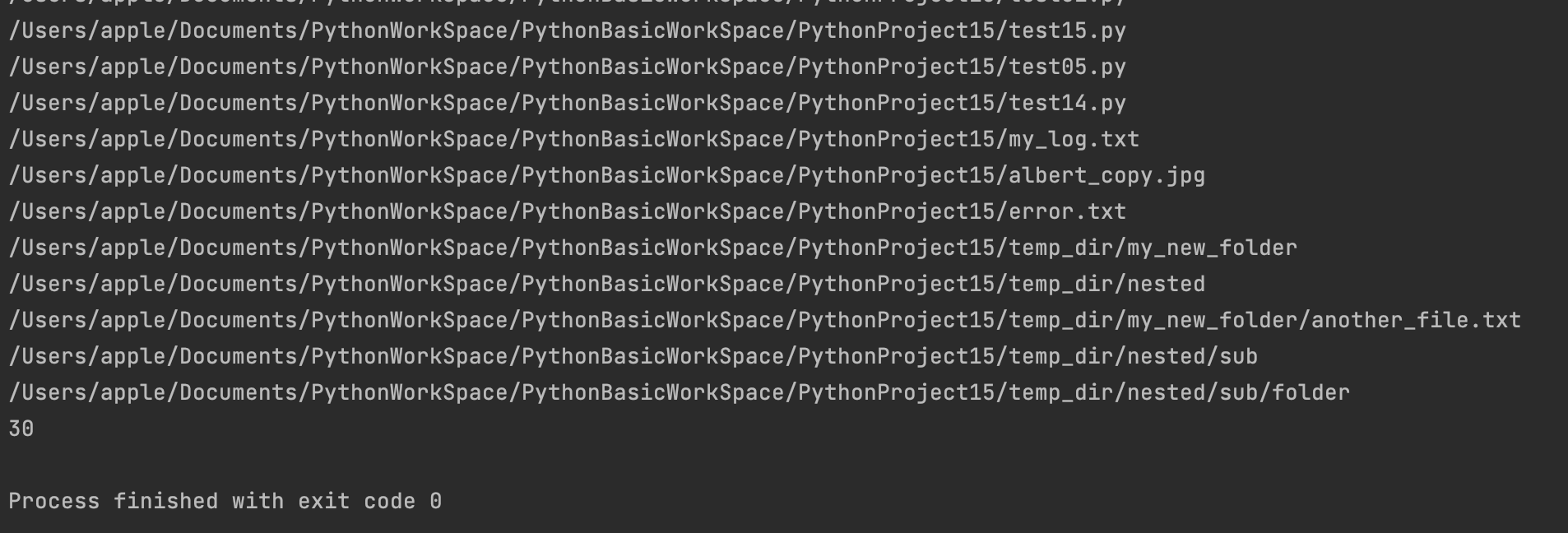
可以做拼接等操作:
1
2
3
4
5
6
7
8
import os
current_path = os.getcwd()
lst_files = os.walk(current_path)
for dirpath, dirname, filename in lst_files:
for dir in dirname:
print(os.path.join(dirpath, dir))
for file in filename:
print(os.path.join(dirpath, file))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test10].py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test19.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test09.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test18.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/text04.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test08.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/albert.jpg
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test17.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test07.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test13.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test03.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test12.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test02.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/my_safe_file.txt
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test16.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test06.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test11.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test01.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test15.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test05.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/test14.py
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/my_log.txt
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/albert_copy.jpg
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/error.txt
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/my_new_folder
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/my_new_folder/another_file.txt
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested/sub
/Users/apple/Documents/PythonWorkSpace/PythonBasicWorkSpace/PythonProject15/temp_dir/nested/sub/folder
用tree命令看到,上面的输出就是打印了每个文件和目录:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
(base) apple@192 PythonProject15 % tree
.
├── albert.jpg
├── albert_copy.jpg
├── error.txt
├── my_log.txt
├── my_safe_file.txt
├── temp_dir
│ ├── my_new_folder
│ │ └── another_file.txt
│ └── nested
│ └── sub
│ └── folder
├── test01.py
├── test02.py
├── test03.py
├── test05.py
├── test06.py
├── test07.py
├── test08.py
├── test09.py
├── test10].py
├── test11.py
├── test12.py
├── test13.py
├── test14.py
├── test15.py
├── test16.py
├── test17.py
├── test18.py
├── test19.py
└── text04.py
5 directories, 25 files
不行的话,可以统计下数量:(上面控制台输出是5个目录,25个文件,一共30个;下面代码输出也是30)
1
2
3
4
5
6
7
8
9
10
11
12
import os
current_path = os.getcwd()
lst_files = os.walk(current_path)
count = 0
for dirpath, dirname, filename in lst_files:
for dir in dirname:
print(os.path.join(dirpath, dir))
count += 1
for file in filename:
print(os.path.join(dirpath, file))
count += 1
print(count)