1、什么叫模块
模块是Python代码的组织单位,它是一个包含Python定义和语句的文件。通过模块,我们可以将相关的代码组织在一起,提高代码的重用性、可维护性和可读性。
在Python中,一个 .py 文件就是一个模块。模块可以定义函数、类、变量,或者包含可执行的代码。当一个模块被导入(import)到另一个Python程序中时,该模块中的定义就可以被使用。
模块的优点:
-
代码重用: 将常用功能封装在模块中,可以在不同的程序中多次导入和使用,避免重复编写代码。
-
代码组织: 将大型程序分解为多个小模块,每个模块负责一个特定的功能,使代码结构清晰,易于管理。
-
命名空间隔离: 每个模块都有自己的独立命名空间,可以避免不同模块之间命名冲突的问题。这意味着你可以在不同的模块中使用相同的变量名或函数名,而不会相互干扰。
-
可维护性: 当需要修改某个功能时,只需要修改对应的模块,而不会影响到程序的其他部分。
-
可测试性: 模块化使得对单个功能单元进行独立测试变得更加容易。
当Python解释器执行
import module_name语句时,它会执行以下操作:
- 搜索模块文件: 解释器会在一系列预定义的路径(
sys.path)中查找名为module_name.py的文件。这些路径包括:○ 当前工作目录。
○ PYTHONPATH 环境变量指定的目录。
○ Python安装目录下的标准库目录。
○
site-packages目录(第三方库安装位置)。
编译和执行: 如果找到模块文件,Python会将其编译成字节码(
.pyc文件,如果需要且有权限),然后执行模块中的所有顶级代码。创建模块对象: 解释器会创建一个模块对象。这个模块对象是一个特殊的Python对象,其
__dict__属性包含了模块中定义的所有全局名称(函数、类、变量等)。添加到
sys.modules: 模块对象会被添加到sys.modules字典中。sys.modules是一个全局字典,用于缓存已导入的模块。下次再导入同一个模块时,Python会直接从sys.modules中获取,避免重复导入和执行。绑定名称: 最后,模块对象会被绑定到当前导入模块的命名空间中。例如,
import my_module会在当前命名空间中创建一个名为my_module的变量,它引用了导入的模块对象。
导入方式:
● import module_name:导入整个模块。使用时需要通过 module_name.function() 或 module_name.variable 访问。
● import module_name as alias:导入整个模块并为其指定一个别名。
● from module_name import item_name:从模块中导入特定的函数、类或变量到当前命名空间,可以直接使用 item_name。
● from module_name import item1, item2:导入多个特定项。
● from module_name import *:导入模块中的所有公共名称到当前命名空间。不推荐,因为它可能导致命名冲突,使代码难以阅读和维护。
准备一个my_calculator.py模块文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 14:41
# 这是一个简单的计算器模块
PI = 3.14159 # 模块级别的变量
def add(a, b):
"""
计算2个数的和
"""
return a + b
def substract(a, b):
"""
计算2个数的差
"""
return a - b
def multiply(a, b):
"""
计算2个数的乘积
"""
return a * b
def divide(a, b):
"""
计算2个数的商
"""
return a / b
class Calculator:
"""
一个简单的计算器类
"""
def __init__(self, initial_value):
self.value = initial_value
def add(self, num):
self.value += num
return self.value
def get_value(self):
return self.value
准备主程序文件main_app.py,与my_calculator.py模块文件在同一个目录下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 14:45
# 导入整个模块
import my_calculator
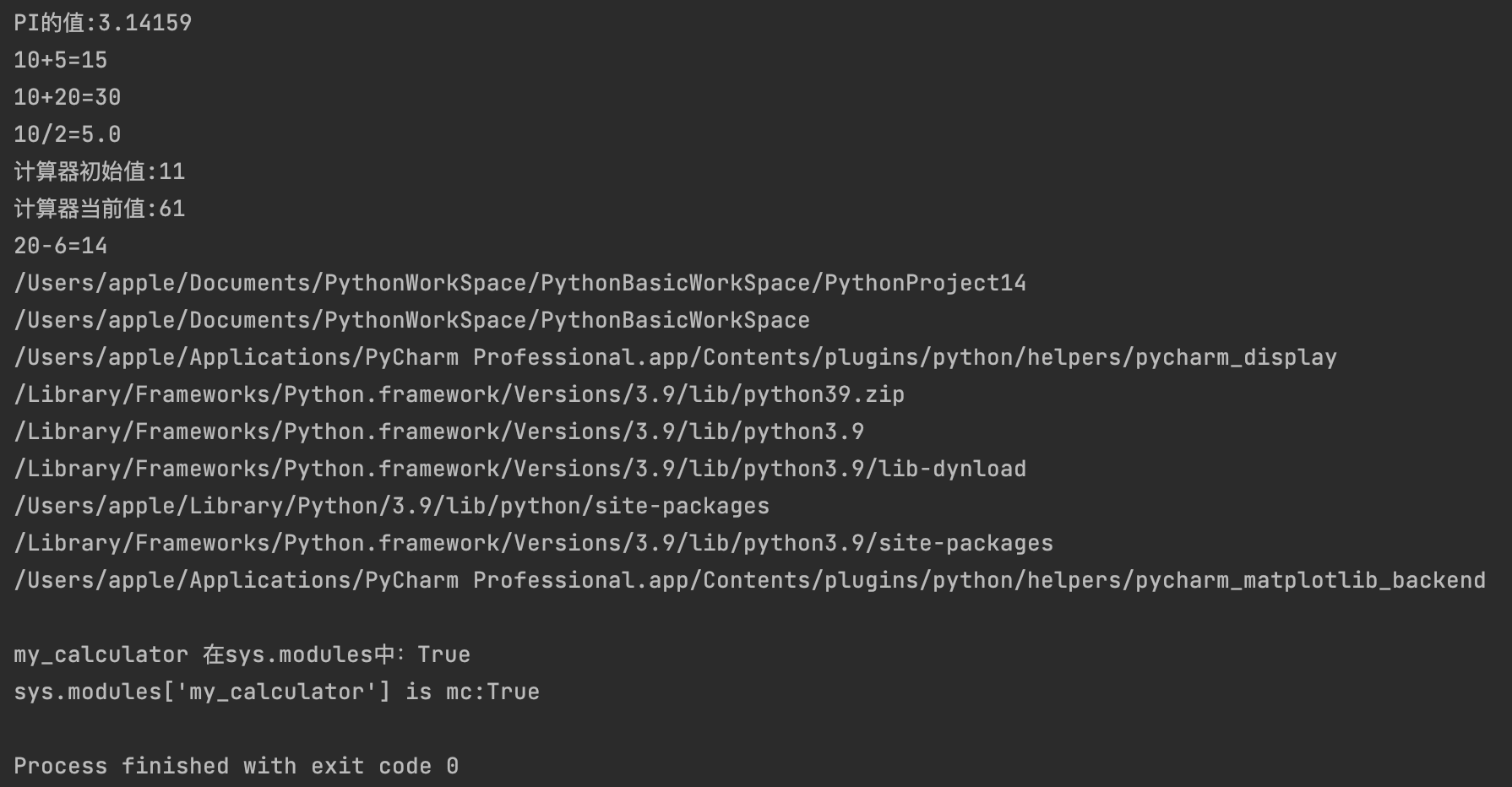
print(f"PI的值:{my_calculator.PI}")
print(f"10+5={my_calculator.add(10, 5)}")
# 导入时使用别名
import my_calculator as mc
print(f"10+20={mc.add(10, 20)}")
# 从模块中导入特定项
from my_calculator import divide, Calculator
print(f"10/2={divide(10, 2)}")
c = Calculator(11)
print(f"计算器初始值:{c.get_value()}")
c.add(50)
print(f"计算器当前值:{c.get_value()}")
# 尝试导入所有(不推荐)
from my_calculator import *
print(f"20-6={substract(20, 6)}")
# sys.path sys.modules
import sys
for p in sys.path:
print(p)
print()
print(f"my_calculator 在sys.modules中:{'my_calculator' in sys.modules}")
print(f"sys.modules['my_calculator'] is mc:{sys.modules['my_calculator'] is mc}")
习题1.1
创建一个名为 string_utils.py 的模块,其中包含以下函数:
○ reverse_string(s): 接收一个字符串,返回其反转后的字符串。
○ is_palindrome(s): 接收一个字符串,判断它是否是回文(忽略大小写和空格),返回 True 或 False。
○ count_vowels(s): 接收一个字符串,返回其中元音字母(a, e, i, o, u)的数量(忽略大小写)。
然后,在另一个Python文件(例如 main.py)中导入并使用这些函数,测试它们的功能。
参考答案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 14:55
"""
○ `reverse_string(s)`: 接收一个字符串,返回其反转后的字符串。
○ `is_palindrome(s)`: 接收一个字符串,判断它是否是回文(忽略大小写和空格),返回 True 或 False。
○ `count_vowels(s)`: 接收一个字符串,返回其中元音字母(a, e, i, o, u)的数量(忽略大小写)。
"""
import copy
def reverse_string(s):
"""
接收一个字符串,返回其反转后的字符串。
"""
return s[::-1]
def is_palindrome(s):
"""
接收一个字符串,判断它是否是回文(忽略大小写和空格),返回 True 或 False。
"""
# 移除空格并转换为小写
processed_s = "".join(char.lower() for char in s if char.isalnum())
return processed_s == processed_s[::-1]
def count_vowels(s):
"""
接收一个字符串,返回其中元音字母(a, e, i, o, u)的数量(忽略大小写)。
"""
ans = 0
vowels = "aeiou"
for i in s:
if i.lower() in vowels:
ans += 1
return ans
1
2
3
4
5
import string_utils
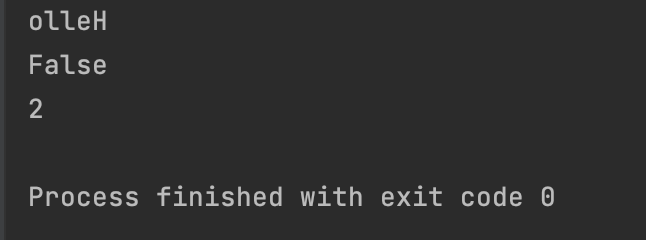
s = "Hello"
print(string_utils.reverse_string(s))
print(string_utils.is_palindrome(s))
print(string_utils.count_vowels(s))
习题1.2
创建一个名为 geometry.py 的模块,其中包含:
○ 一个常量 PI = 3.14159。
○ 一个函数 circle_area(radius),计算圆的面积。
○ 一个函数 rectangle_perimeter(length, width),计算矩形的周长。
在 main.py 中,使用 import geometry as geo 导入模块,并计算一个半径为5的圆的面积和一个长为10、宽为4的矩形的周长。
参考答案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 15:16
# 常量
PI = 3.14159
"""
○ 一个函数 `circle_area(radius)`,计算圆的面积。
○ 一个函数` rectangle_perimeter(length, width)`,计算矩形的周长。
"""
def circle_area(radius):
return PI * radius * radius
def rectangle_perimeter(length, width):
return length * width
1
2
3
4
5
6
7
8
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 15:18
import geometry as geo
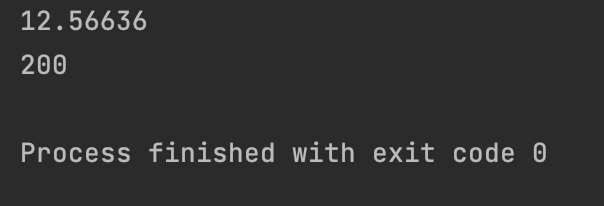
print(geo.circle_area(2))
print(geo.rectangle_perimeter(10, 20))
2、自定义模块
自定义模块是开发者为了组织自己的代码而创建的 .py 文件。通过将相关的功能封装在自定义模块中,可以提高代码的结构性、可重用性和可维护性。
创建自定义模块非常简单,只需将你的Python代码(函数、类、变量等)写入一个 .py 文件,该文件的名称就是模块的名称。
创建步骤:
-
编写代码: 在一个文本编辑器或IDE中创建一个新文件,例如
my_module.py。 -
添加内容: 在该文件中编写你的Python代码,例如定义函数、类或变量。
-
保存文件: 将文件保存为
.py扩展名。
使用步骤:
-
放置模块: 确保你的自定义模块文件(例如
my_module.py)位于Python解释器可以找到的路径中。最简单的方法是将其放在与你正在运行的主程序文件相同的目录下。 -
导入模块: 在你的主程序文件中使用
import语句导入你的自定义模块。 -
使用模块内容: 通过模块名(或别名)来访问模块中定义的函数、类或变量。
模块的命名约定:
● 模块名应全小写,并使用下划线 _ 分隔单词(例如 my_utility_functions.py)。
● 避免使用Python内置模块的名称(如 math, os, sys 等),以防名称冲突。
● 避免使用特殊字符或数字开头。
当Python解释器遇到 import 语句时,它会按照
sys.path中定义的顺序搜索模块文件。一旦找到你的my_module.py文件,它就会编译并执行其中的代码,创建一个模块对象,并将其添加到sys.modules缓存中,最终在当前命名空间中创建一个引用。因此,自定义模块与Python标准库模块或第三方模块在使用方式上并没有本质区别,它们都遵循相同的导入和查找机制。
3、以主程序的形式执行
if __name__ == "__main__": 是Python中一个非常常见的惯用法,用于判断当前模块是被直接运行(作为主程序)还是被导入到其他模块中。这使得模块既可以作为独立的脚本执行,也可以作为可导入的库使用。
当一个Python文件被执行时,Python解释器会给这个文件中的一个特殊内置变量 __name__ 赋值。
● 如果文件被直接运行: 此时,__name__ 变量的值会被设置为字符串 "__main__"。
● 如果文件被导入: 此时,__name__ 变量的值会被设置为模块本身的名称(即文件名,不带 .py 后缀)。
利用这个特性,我们就可以编写如下结构的代码my_module.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 15:47
def some_function():
print("执行some_function...")
if __name__ == '__main__':
# 只有当 my_module.py 被直接运行时,这里的代码才会执行
print("`my_module.py`执行中...")
some_function()
# 可以在这里放一些测试代码、命令行解析逻辑等
用途:
-
模块的测试代码: 在
if __name__ == "__main__":块中放置模块的测试代码。当你直接运行模块时,测试代码会执行;当你将模块导入到其他程序时,测试代码不会执行,避免了不必要的副作用。 -
命令行工具: 许多命令行工具的入口点都在这个块中,用于解析命令行参数并执行相应逻辑。
-
示例用法: 提供模块的简单使用示例,方便其他开发者快速了解如何使用该模块。
Python解释器在加载和执行任何
.py文件时,都会在文件顶层的作用域中定义一些特殊的内置变量。__name__就是其中之一。它的值由解释器根据当前文件是如何被调用的来决定。● 直接执行: 当你通过
python my_script.py命令运行一个文件时,解释器会将该文件视为程序的入口点。为了标识这个入口点,解释器会将该文件的__name__变量设置为"__main__"。● 作为模块导入: 当你通过
import my_module语句在一个文件中导入另一个文件时,被导入的文件(my_module.py)会被当作一个普通的模块来处理。此时,解释器会将my_module.py文件中的__name__变量设置为其模块名"my_module"。这个机制使得Python程序能够灵活地在“可执行脚本”和“可复用库”之间切换身份,而无需为每种用途创建单独的文件。
习题3.1
创建一个名为 data_analyzer.py 的模块。
○ 在其中定义一个函数 analyze_list(data_list),该函数接收一个数字列表,并返回一个包含其平均值、最大值和最小值的字典。
○ 在 if __name__ == "__main__": 块中,添加测试代码:创建一个示例数字列表,调用 analyze_list 函数,并打印结果。
○ 在另一个文件 report_generator.py 中导入 data_analyzer 模块,并使用 analyze_list 函数处理另一个列表,打印结果。观察 data_analyzer.py 中的测试代码是否在 report_generator.py 运行时执行。
参考答案:data_analyzer.py 模块:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 15:53
def analyze_list(data_list):
"""
接收一个数字列表,并返回一个包含其平均值、最大值和最小值的字典。
"""
sum = 0
min_value = data_list[0]
max_value = data_list[0]
for i in data_list:
sum += i
if i < min_value:
min_value = i
if i > max_value:
max_value = i
avg = sum / len(data_list)
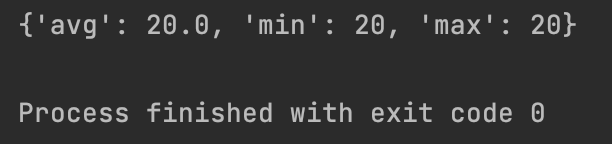
return {"avg": avg, "min": min_value, "max": max_value}
if __name__ == '__main__':
l = [10, 20, 30, 40]
dic1 = analyze_list(l)
print(dic1)
report_generator.py:
1
2
3
4
5
6
7
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 15:56
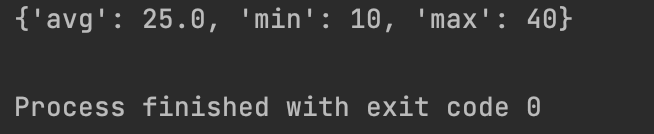
import data_analyzer
l = [20, 20, 20]
res = data_analyzer.analyze_list(l)
print(res)
4、python中的包
包是组织Python模块的方式,它是一个包含 __init__.py 文件的目录。包可以包含子包和模块,形成一个层次结构,有助于管理大型项目和避免命名冲突。
随着项目规模的增大,单个模块可能无法有效组织所有代码。包提供了一种将相关模块分组的机制,类似于文件系统中的文件夹。
包的结构:
一个典型的Python包结构如下:
1
2
3
4
5
6
7
8
9
my_project/
├── main.py
├── my_package/
│ ├── __init__.py
│ ├── module_a.py
│ ├── module_b.py
│ └── sub_package/
│ ├── __init__.py
│ └── module_c.py
__init__.py 文件:是将一个目录标识为Python包的关键文件。无论该文件是空的还是包含代码,它的存在都告诉Python解释器这是一个包,而不是普通的目录。当一个包被导入时(例如 import my_package),__init__.py 文件中的代码会首先被执行。
○ 用途:
■ 初始化包: 可以用来设置包级别的变量、执行一次性初始化代码。
■ 控制 from package import * 行为: 在 __init__.py 中定义 __all__ 变量(一个字符串列表),可以指定当使用 from package import * 时哪些模块或名称会被导入。
■ 简化导入: 可以在 __init__.py 中导入子模块或子包中的常用项,从而允许用户直接通过 from my_package import some_function_from_module_a 而无需 from my_package.module_a import some_function_from_module_a。
导入包和模块:
- 绝对导入 (Absolute Imports):
○ 从项目的根目录(通常是 sys.path 中的一个目录)开始,指定模块的完整路径。
○ 示例: import my_package.module_a
○ 示例: from my_package.sub_package import module_c
○ 优点: 清晰明确,不易混淆,推荐用于跨包导入。
- 相对导入 (Relative Imports):
○ 在包内部,使用点 . 来表示当前包的相对路径。
○ from . import module_b:导入当前包下的 module_b。
○ from .sub_package import module_c:导入当前包下的 sub_package 中的 module_c。
○ from .. import module_a:导入上一级包中的 module_a。
○ 用途: 适用于在同一个包内的模块之间进行导入,避免硬编码包名,使包更具可移植性。
○ 注意: 相对导入只能在包内部使用,不能在直接运行的脚本中使用。
● 包的加载: 当Python解释器遇到
import package_name时,它会首先在sys.path中查找名为package_name的目录。●
__init__.py的作用: 一旦找到目录,解释器会查找并执行该目录下的__init__.py文件。这个文件的执行结果(例如定义的变量、导入的模块)会成为包的命名空间。没有__init__.py的目录不会被视为包。● 层级命名空间: 包的导入创建了一个嵌套的命名空间。例如,
import my_package.module_a会在当前命名空间中创建一个my_package对象,而my_package对象内部又有一个module_a属性,指向module_a模块对象。●
sys.modules的扩展: 导入包时,包本身和其中被导入的模块都会被添加到sys.modules中。例如,import my_package.module_a会将my_package和my_package.module_a都添加到sys.modules。● 相对导入的解析: 相对导入是基于当前模块的
__package__属性(该属性存储了模块所属的包的名称)来解析路径的。解释器会根据__package__和点号的数量来确定要导入的模块的绝对路径。
为了演示包,我们需要创建一个目录结构。
1
2
3
4
5
6
7
8
9
10
# 假设你的项目根目录是 'my_project'
# my_project/
# ├── main.py
# └── my_app_package/
# ├── __init__.py
# ├── utils.py
# ├── models.py
# └── services/
# ├── __init__.py
# └── data_service.py
my_app_package/__init__.py内容:
1
2
3
4
5
6
7
8
9
10
11
12
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 16:07
# 这个文件可以是空的,但是它的存在就定义了my_app_package是一个包
print("初始化my_app_package...") # 导入包时会执行
# 可以在这里导入常用的子模块或者函数,简化外部导入
from . import utils
from .services import data_service
# 定义 from my_app_package import * 时导入的内容
__all__ = ['utils', 'models']
my_app_package/utils.py内容
1
2
3
4
5
6
7
8
9
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 16:07
def format_name(first, last):
return f"({first}, {last})"
def capitalize_words(text):
return text.title()
my_app_package/models.py内容
1
2
3
4
5
6
7
8
9
10
11
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 16:07
class User:
def __init__(self, user_id, username):
self.user_id = user_id
self.username = username
def get_full_info(self):
return f"User ID:{self.user_id}, Username:{self.username}"
my_app_package/services/__init__.py的内容:
1
2
3
4
5
6
7
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 16:07
# 这个文件也可以是空的
print("初始化my_app_package/services子包...")
my_app_package/services/data_service.py的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 16:08
def fetch_data_from_db(query):
return f"对于查询{query}, 从数据库中取数据..."
def save_data_to_db(data):
return f"将数据{data}存到数据库中..."
# 演示相对导入
from .. import utils
from ..models import User
def process_user_data(user_obj):
formatted_data = utils.format_name(user_obj.username, "Doe")
print(f"处理数据:{formatted_data}")
my_project/main.py项目根目录下面的main.py的内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
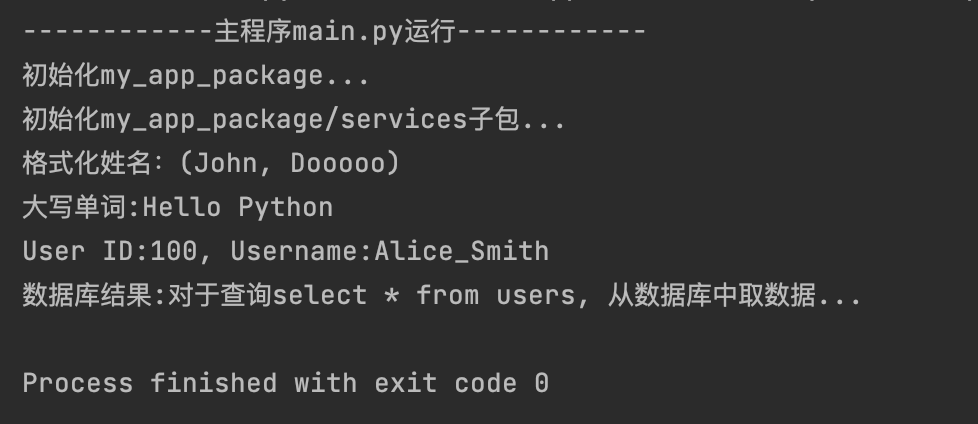
print("------------主程序main.py运行------------")
# 绝对导入
import my_app_package.utils
from my_app_package.models import User
from my_app_package.services import data_service
print(f"格式化姓名:{my_app_package.utils.format_name('John', 'Dooooo')}")
print(f"大写单词:{my_app_package.utils.capitalize_words('hello python')}")
user1 = User(100, "Alice_Smith")
print(user1.get_full_info())
db_res = data_service.fetch_data_from_db("select * from users")
print(f"数据库结果:{db_res}")
1
2
3
4
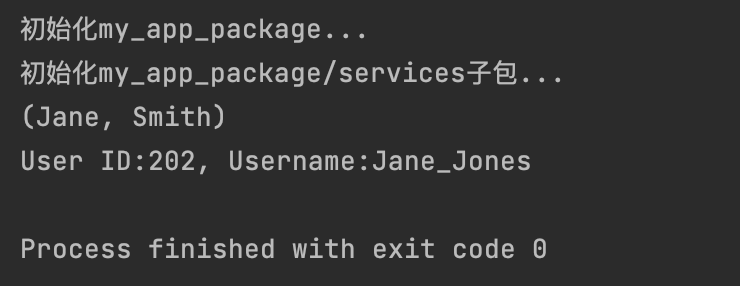
# from package import * 行为 定义在__init__.py中的__all__
from my_app_package import *
print(utils.format_name("Jane", "Smith"))
print(models.User(202, "Jane_Jones").get_full_info())
5、python中常用的内置模块
6、第三方模块的安装及使用
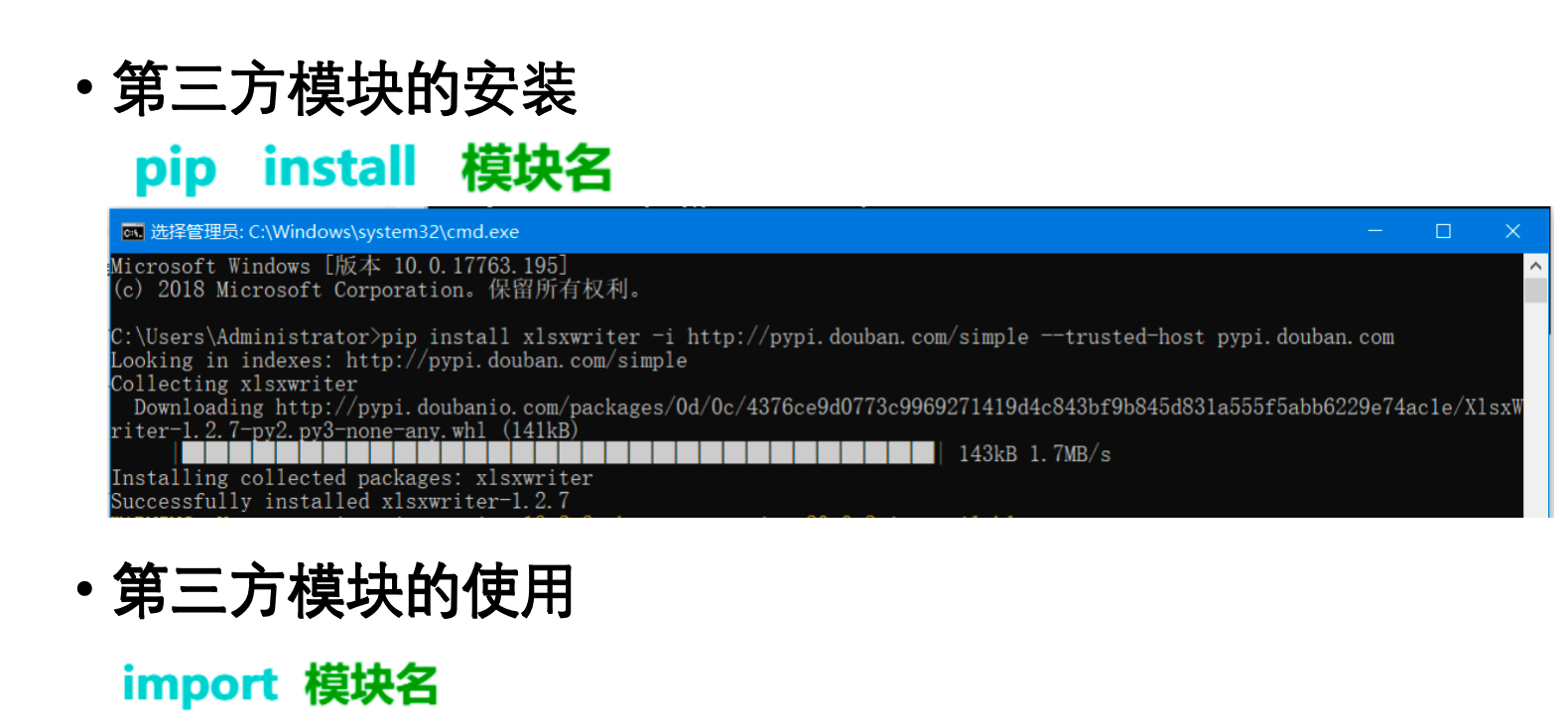
第三方模块是由Python社区开发的,不在Python标准库中的模块。它们通过包管理器 pip 进行安装,极大地扩展了Python的功能,涵盖了从Web开发到数据科学的各种领域。
Python的强大生态系统很大程度上归功于其庞大的第三方模块库。这些模块通常托管在Python包索引(PyPI - The Python Package Index)上,通过 pip 工具进行安装。
pip (Pip Installs Packages):
● pip 是Python的官方推荐包管理器,用于安装和管理Python包。
● Python 3.4+ 版本通常会自带 pip。
常用 pip 命令:
● 安装包: pip install package_name
○ 例如:pip install requests (用于HTTP请求)
○ 例如:pip install numpy (用于科学计算)
● 安装指定版本: pip install package_name==version
○ 例如:pip install requests==2.28.1
● 升级包: pip install --upgrade package_name
● 卸载包: pip uninstall package_name
● 查看已安装包: pip list 或 pip freeze (后者以 requirements.txt 格式输出)
● 生成依赖文件: pip freeze > requirements.txt (将当前环境中的所有包及其版本保存到文件中)
● 从文件安装依赖: pip install -r requirements.txt (根据 requirements.txt 文件安装所有列出的包)
虚拟环境 (Virtual Environments):
● 概念: 虚拟环境是一个独立的Python运行环境,它允许你在不同的项目中使用不同版本的Python和不同的第三方库,而不会相互冲突。
● 为什么要使用:
○ 项目隔离: 每个项目都有自己的依赖,避免“依赖地狱”。
○ 避免权限问题: 无需管理员权限即可安装和管理包。
○ 可复制性: 通过 requirements.txt 文件,可以轻松复制项目依赖环境。
● 常用工具:
○ venv (Python 3.3+ 内置模块)
○ conda (Anaconda发行版自带的包管理器,功能更强大,也支持非Python包)
1
2
3
4
5
6
7
8
9
10
11
12
13
# 博客地址: https://kirsten-1.github.io/
# 创建者: kirsten-1
# 时间: 2025/7/9 17:19
import schedule
import time
def job():
print("Hello World")
schedule.every(3).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)
