1、函数的创建和调用
函数就是执行特定任和以完成特定功能的一段代码。
为什么需要函数?
- 复用代码
- 隐藏实现细节
- 可维护性
- 可调试性
- 可读性
函数是组织良好、可重用的代码块,用于执行特定任务。在Python中,使用 def 关键字创建函数,并通过函数名后跟括号 () 来调用。
函数是Python中的“一等公民”(first-class citizens),这意味着它们可以像其他数据类型(如整数、字符串)一样被赋值给变量、作为参数传递给其他函数、或者作为其他函数的返回值。这种特性是函数式编程范式的基石。
● 创建 (定义): 使用 def 关键字后跟函数名、参数列表(可选)和冒号 :。函数体必须缩进。
● 调用: 通过函数名后跟圆括号 () 来执行函数。如果函数定义了参数,调用时需要提供相应数量和类型的实参。
当Python解释器遇到 def 语句时,它不会立即执行函数体内的代码。相反,它会做以下几件事:
创建函数对象: 解释器会创建一个函数对象(一个 function 类的实例)。这个对象包含了函数的元数据,如函数名、参数信息、函数体的字节码(编译后的代码)以及函数定义时的作用域(闭包)。
绑定名称: 将这个函数对象绑定到函数名上。例如,
def my_func(): ...会在当前作用域中创建一个名为my_func的变量,其值就是新创建的函数对象。当函数被调用时:
查找函数对象: 解释器通过函数名查找对应的函数对象。
创建新的栈帧 (Stack Frame): 为这次函数调用创建一个新的执行环境,也称为栈帧。这个栈帧包含了函数的局部变量、参数以及返回地址等信息。
参数绑定: 将调用时传入的实参绑定到函数定义时的形参上。
执行函数体: 解释器开始执行函数对象中存储的字节码。
销毁栈帧: 函数执行完毕(遇到
return语句或函数体结束)后,其对应的栈帧被销毁,控制权返回到调用点。这种机制确保了函数调用的独立性,每次调用都有自己的局部变量副本,互不干扰。
(1)函数的创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def greet(name):
'''
这是一个简单的问候函数。
它接受一个名字作为参数,并打印问候语。
'''
print(f"Hello, {name}")
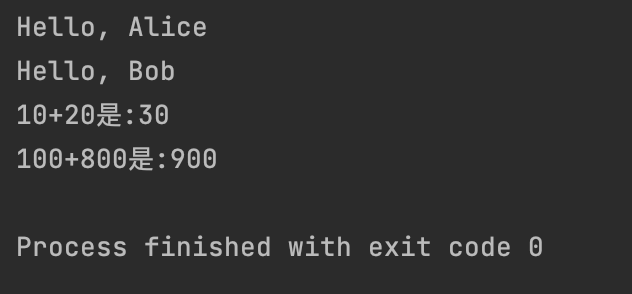
greet("Alice")
greet("Bob")
def add2Num(a, b):
'''
计算并且返回两个数的和
'''
return a + b
res1 = add2Num(10, 20)
print(f"10+20是:{res1}")
res2 = add2Num(100, 800)
print(f"100+800是:{res2}")
(2)函数的调用
上面两个函数:greet(name)和add2Num(a, b)的调用也已经在代码中给出了。
【1】下面解释:函数是“一等公民”的体现:可以将函数赋值给变量,然后通过变量调用函数
1
2
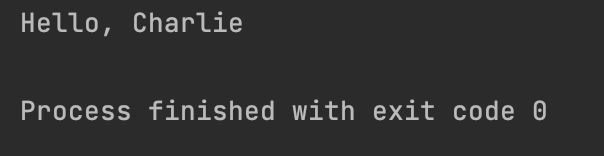
my_greeting_func = greet
my_greeting_func("Charlie")
【2】可以在函数内部定义和调用其他函数 (嵌套函数)
1
2
3
4
5
6
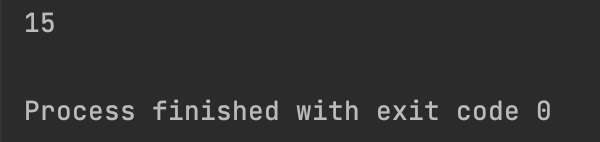
def outer_fun(x):
def inner_fun(y):
return x + y
return inner_fun(10)
res = outer_fun(5)
print(res)
【3】函数可以作为参数传递给其他函数
1
2
3
4
5
6
7
8
9
10
def add2Num(a, b):
'''
计算并且返回两个数的和
'''
return a + b
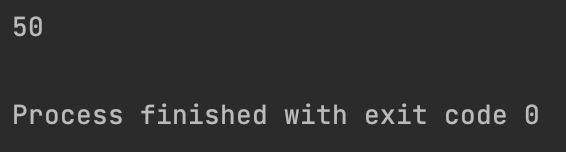
def apply_operation(func, arg1, arg2):
return func(arg1, arg2)
res_add = apply_operation(add2Num, 10, 40)
print(res_add)
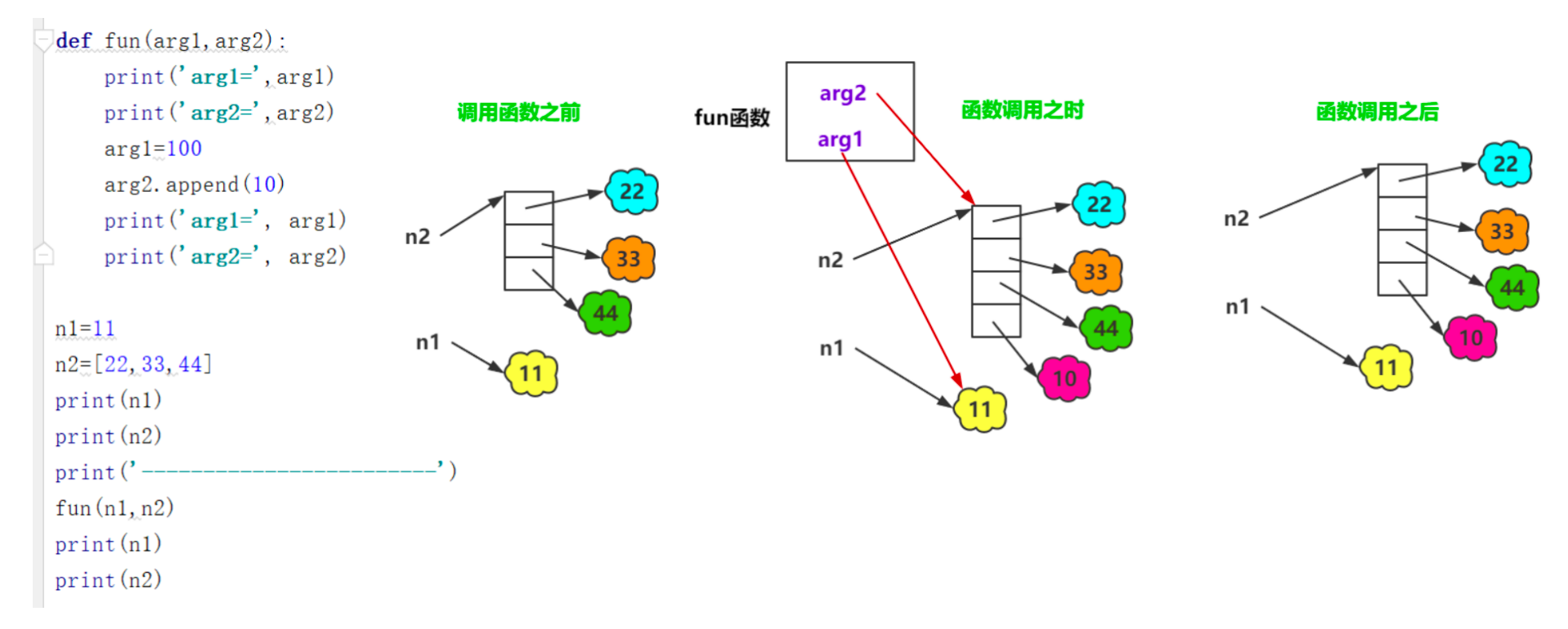
2、函数的参数传递
Python的参数传递机制是“按对象引用传递”(Call by Object Reference),这意味着函数接收的是实参所指向的对象的引用。对于不可变对象,形参的重新赋值不会影响实参;对于可变对象,通过形参对对象内容的修改会影响到实参。
理解Python的参数传递机制对于避免副作用和编写健壮的代码至关重要。Python既不是严格的“按值传递”(Call by Value),也不是严格的“按引用传递”(Call by Reference),而是“按对象引用传递”。
● 不可变对象 (Immutable Objects): 数字 (int, float, complex)、字符串 (str)、元组 (tuple)、frozenset。
-
当不可变对象作为参数传递时,函数内部的形参会获得该对象的引用。
-
如果在函数内部尝试修改形参的值(例如
param = new_value),这实际上是让形参指向了一个新的对象,而原始的实参对象不受影响。 -
原理: 由于不可变对象的值不能改变,任何看似“修改”的操作都会创建一个新的对象。形参被重新绑定到这个新对象,而实参仍然指向原来的对象。
● 可变对象 (Mutable Objects): 列表 (list)、字典 (dict)、集合 (set)、自定义类的实例。
-
当可变对象作为参数传递时,函数内部的形参同样获得该对象的引用。
-
如果在函数内部通过形参修改了对象的内容(例如
list_param.append(item)或dict_param['key'] = value),这些修改会直接作用于原始实参所指向的对象,因此在函数外部也能看到这些变化。 -
如果在函数内部将形参重新赋值为一个新的对象(例如
list_param = [1, 2, 3]),则与不可变对象类似,形参会指向新对象,而原始实参不受影响。
原理: 可变对象在内存中有一个固定的地址,但其内部的数据结构可以被修改。形参和实参都指向这个相同的内存地址,因此通过任何一个引用进行的修改都会反映在同一个对象上。
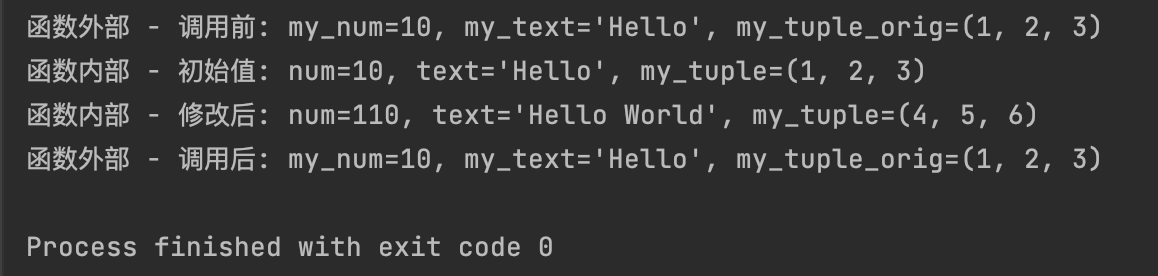
(1)不可变对象作为参数
函数外部变量的值没有改变,因为形参的重新赋值只是改变了形参的指向,而没有改变实参所指向的对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def modify_immutable(num, text, my_tuple):
print(f"函数内部 - 初始值: num={num}, text='{text}', my_tuple={my_tuple}")
num += 100 # 重新绑定num到新的整数对象
text += " World" # 重新绑定text到新的字符串对象
my_tuple = (4, 5, 6) # 重新绑定my_tuple到新的元组对象
print(f"函数内部 - 修改后: num={num}, text='{text}', my_tuple={my_tuple}")
my_num = 10
my_text = "Hello"
my_tuple_orig = (1, 2, 3)
print(f"函数外部 - 调用前: my_num={my_num}, my_text='{my_text}', my_tuple_orig={my_tuple_orig}")
modify_immutable(my_num, my_text, my_tuple_orig)
print(f"函数外部 - 调用后: my_num={my_num}, my_text='{my_text}', my_tuple_orig={my_tuple_orig}")
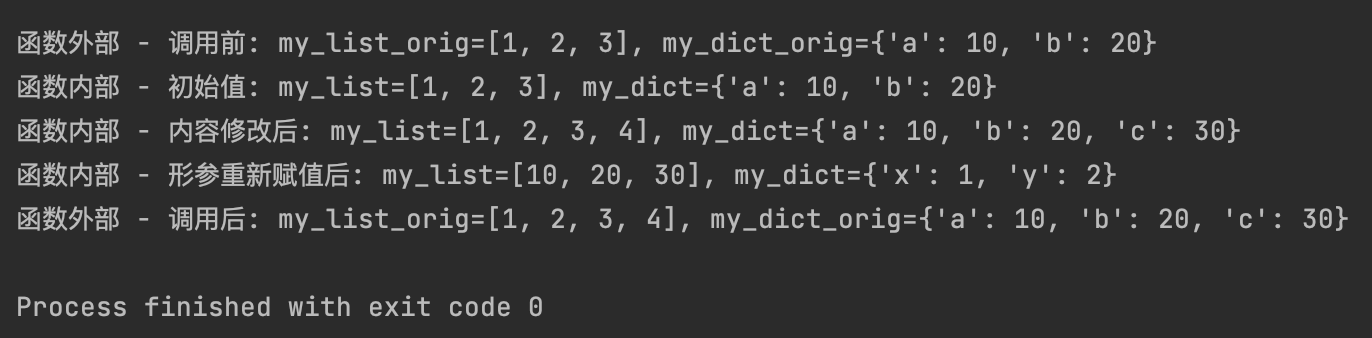
(2)可变对象作为参数
若参数是列表和字典,内容会被修改。函数内部对形参的重新赋值没有影响外部。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def modify_mutable(my_list, my_dict):
print(f"函数内部 - 初始值: my_list={my_list}, my_dict={my_dict}")
my_list.append(4) # 修改列表内容
my_dict['c'] = 30 # 修改字典内容
print(f"函数内部 - 内容修改后: my_list={my_list}, my_dict={my_dict}")
my_list = [10, 20, 30]
my_dict = {'x': 1, 'y': 2}
print(f"函数内部 - 形参重新赋值后: my_list={my_list}, my_dict={my_dict}")
my_list_orig = [1, 2, 3]
my_dict_orig = {'a': 10, 'b': 20}
print(f"函数外部 - 调用前: my_list_orig={my_list_orig}, my_dict_orig={my_dict_orig}")
modify_mutable(my_list_orig, my_dict_orig)
print(f"函数外部 - 调用后: my_list_orig={my_list_orig}, my_dict_orig={my_dict_orig}")
(3)默认参数的可变对象陷阱
默认参数在函数定义时被评估一次(这个空列表 [] 只在函数定义时创建一次。它不是在每次调用 my_function 时都重新创建一个)。由于默认参数是同一个可变对象,每次调用如果没有显式提供新参数,就会修改这个共享的对象。这导致了函数调用的“副作用”,即函数的行为不再独立,而是受之前调用留下的状态影响。对于不可变对象(如数字、字符串、元组、None),这没有问题。但对于可变对象(如列表、字典、集合),这意味着所有后续调用(在没有显式提供该参数的情况下)都将引用并修改同一个对象,导致意想不到的行为。
解决办法是使用 None 作为默认值,并在函数体内部检查 None,然后惰性地创建可变对象。通过这种方式,我们确保了在没有显式提供参数的情况下,每次函数调用都会操作一个独立的、新创建的可变对象,从而避免了共享默认可变对象带来的意外行为。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def add_to_list(item, my_list=[]): # 默认参数是一个可变对象
my_list.append(item)
return my_list
list1 = add_to_list(1)
print(f"第一次调用: {list1}") # [1]
list2 = add_to_list(2) # 预期 [2] 但实际是 [1, 2]
print(f"第二次调用: {list2}") # [1, 2] - 陷阱!
list3 = add_to_list(3, []) # 显式提供列表,避免陷阱
print(f"第三次调用 (显式提供列表): {list3}") # [3]
# 避免陷阱的正确做法
def add_to_list_safe(item, my_list=None):
if my_list is None:
my_list = []
my_list.append(item)
return my_list
print("\n--- 避免默认参数可变对象陷阱 ---")
list_safe1 = add_to_list_safe(1)
print(f"安全方式第一次调用: {list_safe1}") # [1]
list_safe2 = add_to_list_safe(2)
print(f"安全方式第二次调用: {list_safe2}") # [2]

3、函数的返回值
函数可以通过 return 语句将值传递回调用方。一个函数可以返回任何类型的对象,包括多个值(作为元组返回)或不返回任何值(隐式返回 None)。
return 语句用于退出函数并将一个值(或多个值)传回给调用它的代码。
● 单个返回值: 最常见的情况,return expression 将 expression 的结果作为返回值。
● 多个返回值: Python允许函数返回多个值,实际上是将这些值打包成一个元组返回。调用方可以通过元组解包来获取这些值。
● 无返回值: 如果函数没有 return 语句,或者只有 return 而没有指定值,函数将隐式返回特殊值 None。None 是Python中的一个单例对象,表示“无”或“空”。
● 提前退出: return 语句会立即终止函数的执行,即使后面还有代码。
当解释器执行到 return 语句时:
计算返回值: return 后面的表达式会被计算。
栈帧销毁与值传递: 当前函数的栈帧被销毁。计算出的返回值被放置在一个特殊的位置(通常是CPU寄存器或栈上的特定位置),以便调用函数能够访问到它。
控制权返回: 程序执行的控制权从被调用的函数跳转回调用它的代码行。调用函数可以捕获这个返回值,并将其赋值给一个变量。
对于多个返回值,Python的实现机制是:在 return 语句中,多个值被自动打包成一个元组,然后这个元组作为单个对象返回。调用方在接收时,如果使用多个变量来接收,Python会自动进行元组解包。
(1)返回单个值
1
2
3
4
def get_square(num):
return num * num
res_square = get_square(5)
print(f"5的平方是:{res_square}")
(2)返回多个值 (作为元组返回,可解包)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def get_user_info(user_id):
if user_id == 1:
return "Alice", 30, "Engineer"
elif user_id == 2:
return "Bob", 32, "Designer"
else:
return None, None, None
name, age, occupation = get_user_info(1)
print(f"姓名:{name}, 年龄:{age}, 职业:{occupation}")
# 也可以不解包,直接接收元组
user_info_tuple = get_user_info(2)
print(f"用户信息:{user_info_tuple}")
# 处理不存在的用户
name, age, occupation = get_user_info(99)
print(f"用户99的信息: 姓名={name}, 年龄={age}, 职业={occupation}")

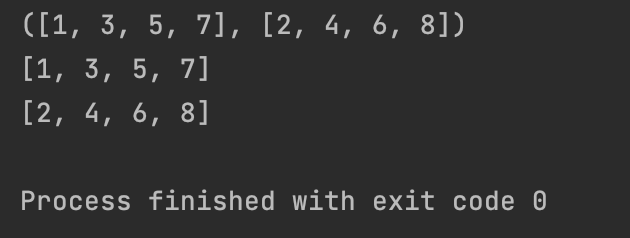
再看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
def fun(nums):
odd = []
even = []
for n in nums:
if n % 2:
odd.append(n)
else:
even.append(n)
return odd,even
res = fun([1,2,3,4,5,6,7,8])
print(res)
print(res[0])
print(res[1])
(3)无返回值 (隐式返回 None)
1
2
3
4
5
def print_message(msg):
print(f"消息:{msg}")
return_value = print_message("Hello there!")
print(f"print_message 函数的返回值: {return_value}") # 输出 None

(4)提前退出函数
1
2
3
4
5
6
7
8
9
10
11
12
def find_first_even(numbers):
for num in numbers:
# 找到第一个偶数后立即返回
if num % 2 == 0:
return num
return "没有偶数"
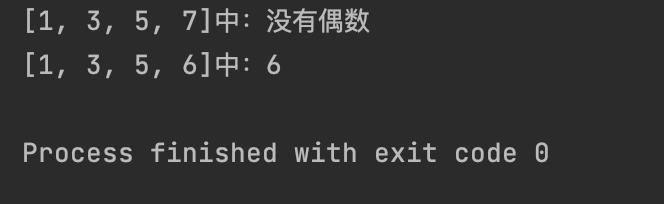
res1 = find_first_even([1, 3, 5, 7])
print(f"[1, 3, 5, 7]中:{res1}")
res2 = find_first_even([1, 3, 5, 6])
print(f"[1, 3, 5, 6]中:{res2}")
4、函数的参数定义
Python提供了灵活的参数定义方式,包括位置参数、关键字参数、默认参数、可变位置参数 (*args)、可变关键字参数 (**kwargs),以及Python 3引入的仅位置参数 (/) 和仅关键字参数 (*)。
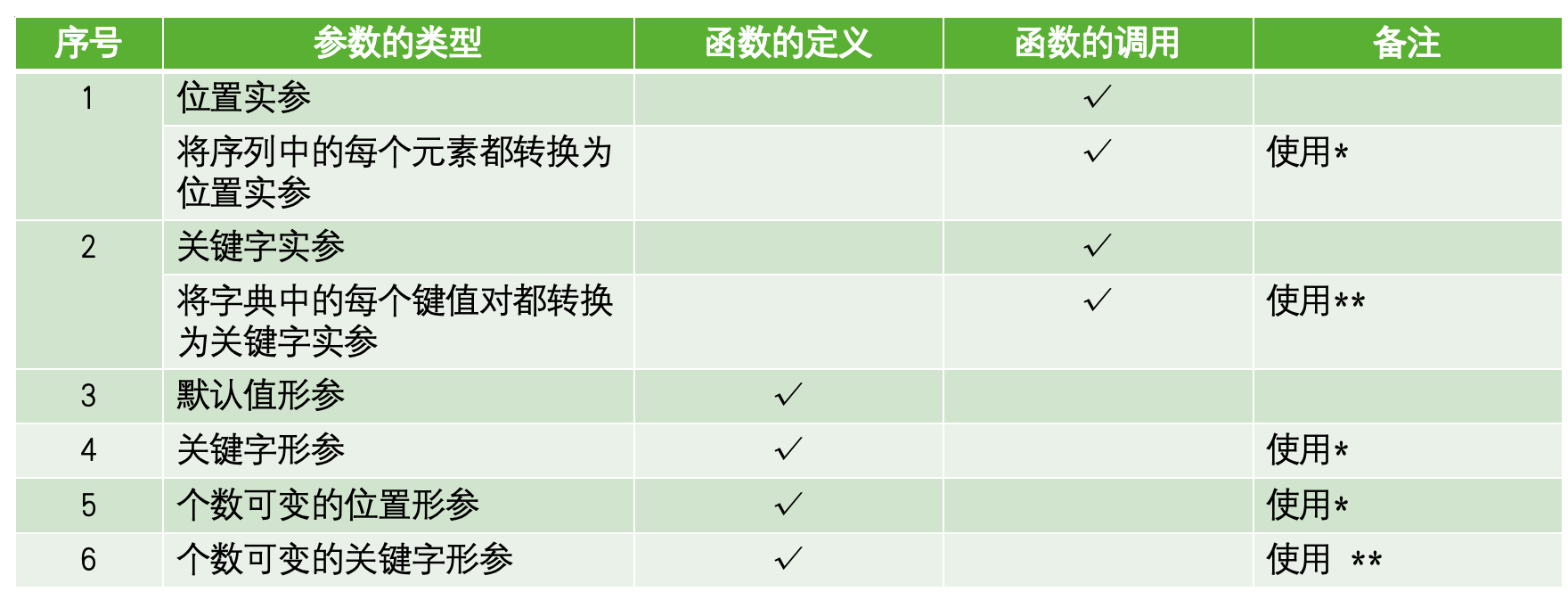
- 位置参数 (Positional Arguments):
○ 按照参数定义的顺序进行匹配。
○ 调用时必须提供,且顺序必须与定义时一致。
○ 示例: def func(a, b):
- 关键字参数 (Keyword Arguments):
○ 在调用时通过 param_name=value 的形式指定,与定义时的顺序无关。
○ 提高了代码的可读性,尤其是在函数有多个参数时。
○ 示例: func(b=20, a=10)
- 默认参数 (Default Arguments):
○ 在定义时为参数指定一个默认值。如果调用时没有为该参数提供实参,则使用默认值。
○ 默认参数必须放在非默认参数之后。
○ 重要陷阱: 默认值在函数定义时只计算一次。如果默认值是可变对象(如列表、字典),那么所有不提供该参数的函数调用将共享同一个可变对象,可能导致意外的副作用。
○ 示例: def func(a, b=10):
- 可变位置参数 (
*args):
○ 允许函数接受任意数量的位置参数。
○ 在函数内部,*args 会被收集为一个元组 (tuple)。
○ *args 必须放在所有普通参数和默认参数之后,但在 **kwargs 之前。
○ 示例: def func(a, *args):
- 可变关键字参数 (**kwargs):
○ 允许函数接受任意数量的关键字参数。
○ 在函数内部,**kwargs 会被收集为一个字典 (dict),其中键是参数名,值是参数值。
○ **kwargs 必须是函数定义中的最后一个参数。
○ 示例: def func(a, **kwargs):
- 仅位置参数 (
/) (Python 3.8+):
○ def func(a, b, /, c, d):
○ 在 / 之前的参数 (a, b) 只能通过位置传递,不能通过关键字传递。
○ 提高了API的清晰度,防止用户依赖参数名。
- 仅关键字参数 (
*):
○ def func(a, *, b, c):
○ 在 * 之后的参数 (b, c) 只能通过关键字传递,不能通过位置传递。
○ * 可以单独使用,也可以与 *args 结合使用(此时 *args 在 * 之后)。
○ 示例: def func(*, b, c): 或 def func(a, *args, b, c):
一个函数定义中,参数的顺序必须是:
def func(位置参数, 仅位置参数/, 默认参数, *args, 仅关键字参数*, **kwargs):
Python解释器在解析函数定义时,会根据这些特殊语法(如
*,**,/)来构建函数的签名(signature)。这个签名定义了函数接受参数的规则。当函数被调用时,解释器会根据调用时提供的实参(位置或关键字)与函数签名进行匹配:
● 位置匹配: 按照从左到右的顺序,将实参绑定到形参。
● 关键字匹配: 将实参的关键字名与形参名进行匹配。
●
*args和**kwargs的收集: 如果有未被普通形参接收的位置实参,它们会被收集到*args元组中。如果有多余的关键字实参,它们会被收集到**kwargs字典中。● 仅位置/仅关键字参数的强制:
/和*符号在解析阶段就强制了参数的传递方式,如果违反规则,会在调用时立即抛出TypeError。这种灵活的参数机制使得Python函数能够适应各种复杂的调用场景,并提供清晰的API设计。
(1)位置参数和关键字参数
1
2
3
4
5
6
7
8
9
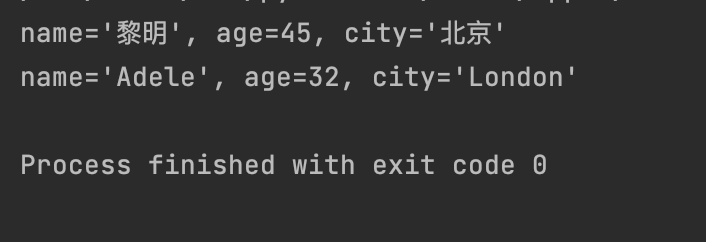
def describe_person(name, age, city):
print(f"{name=}, {age=}, {city=}")
# 位置参数
describe_person("黎明", 45, "北京")
# 关键字参数,顺序无关
describe_person(age=32, name="Adele", city="London")
# 位置参数不能在关键字参数之后, 报错
# describe_person("Halsey", city="布鲁克林区", 30)
(2)默认参数
1
2
3
4
5
6
7
8
9
10
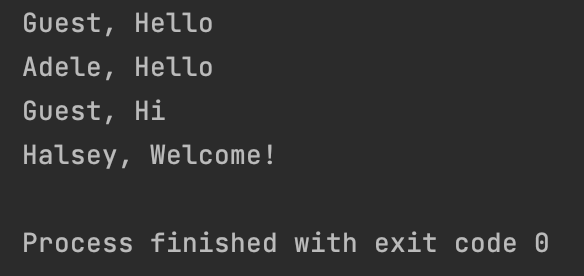
def greet(name="Guest", msg="Hello"):
print(f"{name}, {msg}")
# 使用【所有的】默认参数
greet()
# 覆盖 name
greet("Adele")
# 覆盖 message
greet(msg="Hi")
# 覆盖所有
greet("Halsey", "Welcome!")
(3)可变位置参数
1
2
3
4
5
6
def sum_all_numbers(title, *numbers):
sum_all = sum(numbers)
print(f"{title}: {numbers} 的总和是:{sum_all}")
sum_all_numbers("计算和", 1, 2, 3)
sum_all_numbers("另一个和", 10, 20, 30, 40, 50)
sum_all_numbers("空和") # numbers 会是一个空元组 ()

(4)可变关键字参数
1
2
3
4
5
6
7
8
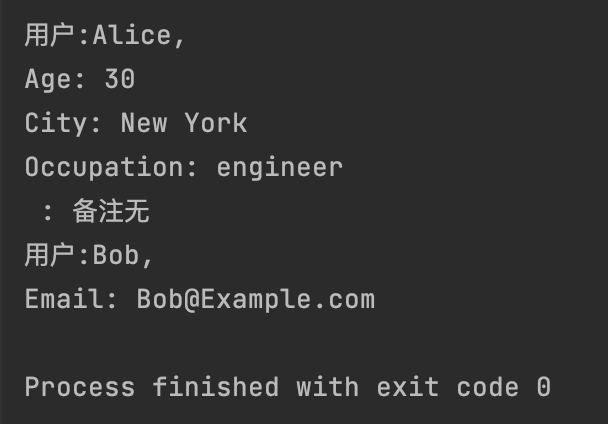
def print_user_details(name, **details):
print(f"用户:{name},")
for key, value in details.items():
print(f"{key.replace('_', ' ').title()}: {value}")
print_user_details("Alice", age=30, city="New York", occupation="engineer", _="备注无")
print_user_details("Bob", email="Bob@Example.com")
(5)仅位置参数 (/) 和 仅关键字参数 (*) - Python 3.8+
目前我的python 版本是:
1
2
result = subprocess.run(["python", "--version"], check=True, capture_output=True, text=True)
print(result)

版本是3.11.7,满足3.8+的要求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
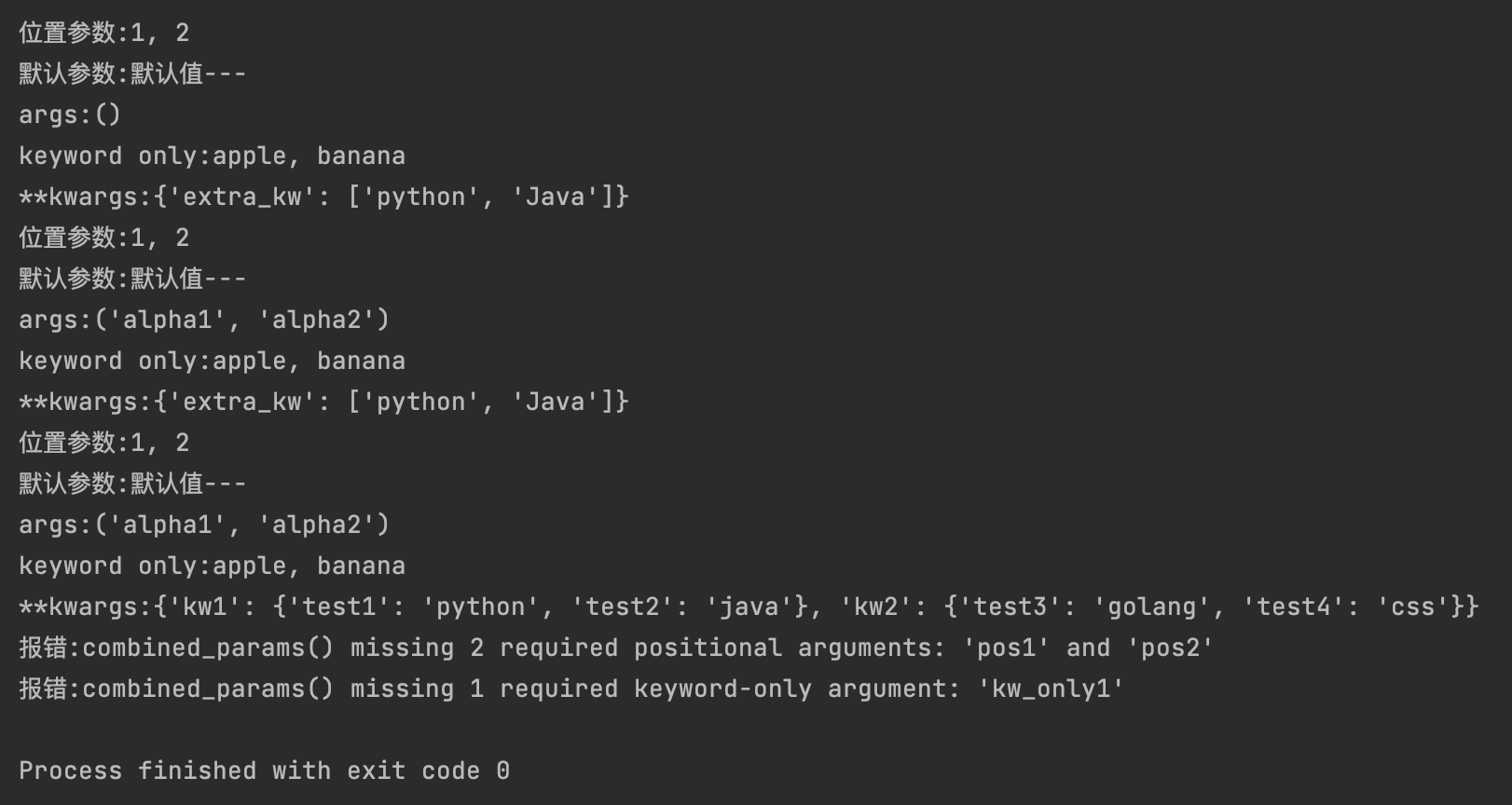
def combined_params(pos1, pos2, /, default_args="default", *args, kw_only1, kw_only2="kw_default", **kwargs):
print(f"位置参数:{pos1}, {pos2}")
print(f"默认参数:{default_args}")
print(f"args:{args}")
print(f"keyword only:{kw_only1}, {kw_only2}")
print(f"**kwargs:{kwargs}")
# 正确调用
combined_params(1, 2, "默认值---", kw_only1 = "apple", kw_only2 = "banana", extra_kw = ["python", "Java"])
combined_params(1, 2, "默认值---","alpha1", "alpha2", kw_only1 = "apple", kw_only2 = "banana", extra_kw = ["python", "Java"])
combined_params(1, 2, "默认值---","alpha1", "alpha2", kw_only1 = "apple", kw_only2 = "banana", kw1 = {"test1": "python","test2": "java" }, kw2 = {"test3": "golang","test4": "css" })
# 错误调用:
try:
combined_params(pos_only1=1, pos_only2=2, kw_only1="req_kw")
except TypeError as e:
print(f"报错:{e}") # combined_params() missing 2 required positional arguments: 'pos1' and 'pos2'
try:
combined_params(1, 2, "my_default", 3, 4, "req_kw")
except TypeError as e:
print(f"报错:{e}") # combined_params() missing 1 required keyword-only argument: 'kw_only1'
(6)函数调用时
1
2
3
4
5
6
list1 = [10, 20, 30]
# 报错的写法:fun(list1)
fun(*list1)
dict1 = {"a": 100, "b": 200, "c":300}
# 报错的写法: fun(dict1)
fun(**dict1)

5、变量的作用域
变量的作用域决定了程序中变量的可见性和生命周期。Python遵循LEGB规则(Local, Enclosing function locals, Global, Built-in),用于查找变量的顺序。
Python的作用域规则是基于函数定义的,而不是基于代码块(如 if 语句或 for 循环)。
LEGB 规则: 当Python查找一个变量时,它会按照以下顺序进行搜索:
- L (Local - 局部作用域):
○ 当前函数内部定义的变量。
○ 函数参数也是局部变量。
○ 生命周期:从函数被调用开始,到函数执行结束。
○ 原理: 局部变量存储在函数的栈帧中。每次函数调用都会创建一个新的栈帧,因此局部变量是独立的。
- E (Enclosing function locals - 闭包函数外的函数作用域 / 嵌套作用域):
○ 如果一个函数定义在另一个函数内部(即嵌套函数),外部函数的局部变量对于内部函数来说就是其“闭包”作用域。
○ 内部函数可以访问外部函数的变量,即使外部函数已经执行完毕,只要内部函数(闭包)还存在引用。
○ 原理: 当内部函数被创建时,它会“记住”其定义时的外部作用域(环境)。即使外部函数执行完毕,这个环境(包括外部函数的局部变量)也会被保留下来,供内部函数访问。这正是闭包的实现机制。
- G (Global - 全局作用域):
○ 在模块(文件)的顶层定义的变量。
○ 在整个模块中都可见。
○ 原理: 全局变量存储在模块的命名空间字典中。
- B (Built-in - 内建作用域):
○ Python解释器预定义的名称,如 print(), len(), True, None 等。
○ 这些名称在任何地方都可见。
○ 原理: 内建名称存储在一个特殊的字典中,解释器在找不到其他作用域中的变量时会查找这里。
变量赋值与作用域:
● 默认情况下,在函数内部对变量进行赋值操作(例如 x = 10),如果 x 之前未在当前函数作用域内定义,Python会将其视为创建了一个新的局部变量 x。
● 要在一个函数内部修改全局变量,必须使用 global 关键字声明该变量。
● 要在一个嵌套函数内部修改外部(非局部)函数的变量,必须使用 nonlocal 关键字声明该变量(Python 3.0+)。
生命周期:
● 局部变量:随函数调用而生,随函数结束而灭。
● 全局变量:随模块导入而生,随程序结束而灭。
● 闭包中的外部变量:只要闭包函数还存在引用,这些变量就会被保留。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
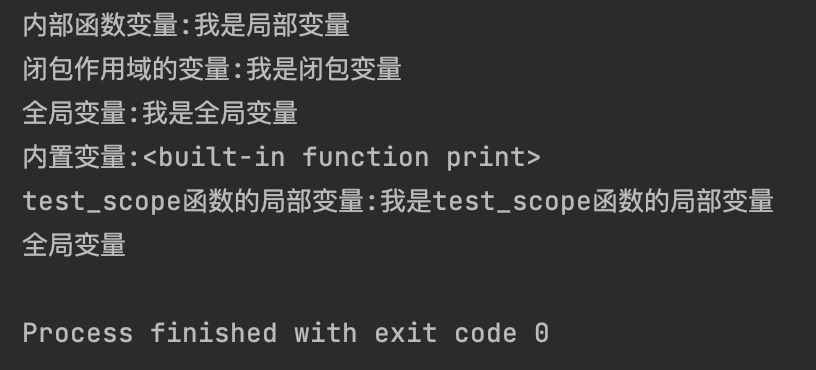
global_var = "我是全局变量"
def outer_function():
# 外部函数的局部作用域,对于内部函数来说是闭包作用域
enclosing_var = "我是闭包变量"
def inner_function():
# 内部函数的局部作用域
local_var = "我是局部变量"
print(f"内部函数变量:{local_var}")
print(f"闭包作用域的变量:{enclosing_var}")
print(f"全局变量:{global_var}")
print(f"内置变量:{print}")
# 调用内部函数
inner_function()
def scope_for_test():
local_to_test = "我是test_scope函数的局部变量"
print(f"test_scope函数的局部变量:{local_to_test}")
print(f"全局变量")
# print(f"闭包的变量:{enenclosing_var}") # 报错
# 测试
outer_function()
scope_for_test()
(1)global关键字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
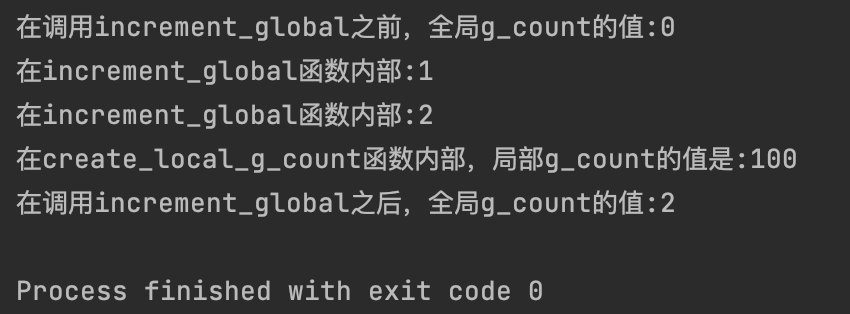
g_count = 0
def increment_global():
# 声明 g_count 是全局变量
global g_count
g_count += 1
print(f"在increment_global函数内部:{g_count}")
def create_local_g_count():
# 创建一个局部变量 g_count,不影响全局的 g_count
g_count = 100
print(f"在create_local_g_count函数内部,局部g_count的值是:{g_count}")
print(f"在调用increment_global之前,全局g_count的值:{g_count}")
increment_global()
increment_global()
create_local_g_count()
print(f"在调用increment_global之后,全局g_count的值:{g_count}")
(2)nonlocal 关键字 (用于嵌套函数修改外部非全局变量)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def counter():
# 外部函数的局部变量
count = 0
def increment():
# 声明 count 是外部函数的变量,而不是局部变量
nonlocal count
count += 1
print(f"在increment中,count={count}")
return count
return increment # 返回内部函数 (闭包)
# my_counter 现在是一个闭包
my_counter = counter()
print(f"第一次调用:{my_counter()}")
print(f"第二次调用:{my_counter()}")
print(f"第三次调用:{my_counter()}")
# 另一个闭包实例,拥有独立的 count
another_counter = counter()
print(f"另一个闭包,第一次调用: {another_counter()}")
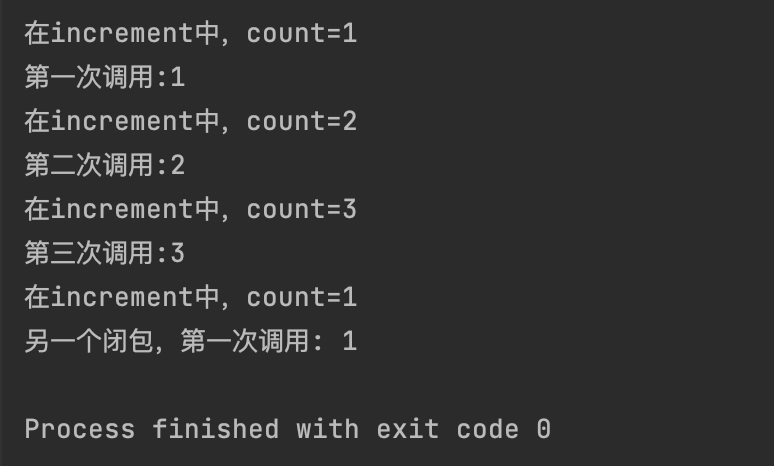
解释:当
counter函数执行完毕并返回increment函数时,即使counter自身的执行环境已经消失,increment函数仍然“携带”着它所需要的count变量的引用。这就是闭包的形成。
6、递归函数
递归函数是一种在函数定义中调用自身的函数。它通过将问题分解为更小的、相同类型的问题来解决,直到达到一个可以直接解决的“基本情况”(Base Case)。
递归是编程中一种强大的解决问题的方法,尤其适用于那些可以被分解为与原问题结构相同但规模更小的子问题。一个有效的递归函数必须包含两个关键部分:
- 基本情况 (Base Case):
○ 递归的终止条件。当问题规模达到基本情况时,函数不再调用自身,而是直接返回一个结果。
○ 这是防止无限递归(栈溢出)的关键。
- 递归步骤 (Recursive Step):
○ 函数调用自身来解决一个或多个规模更小的子问题。
○ 每次递归调用都必须使问题更接近基本情况。
递归的优缺点:
● 优点: 代码通常更简洁、优雅,更符合某些问题的自然逻辑(如树遍历、分治算法)。
● 缺点:
○ 性能开销: 每次函数调用都会产生新的栈帧,带来额外的内存和时间开销。
○ 栈溢出: 如果递归深度过大(没有基本情况或基本情况无法达到),会导致“RecursionError: maximum recursion depth exceeded”错误,因为调用栈的空间是有限的。Python默认的递归深度限制通常是1000。
○ 可读性: 对于不熟悉递归的人来说,理解递归逻辑可能更困难。
递归的执行依赖于函数调用栈(Call Stack)。
当一个函数被调用时,其参数、局部变量以及返回地址等信息会被压入栈中。
当递归函数调用自身时,一个新的栈帧会被创建并压入栈顶。
这个过程重复进行,直到达到基本情况。
当基本情况被满足时,函数开始返回,其对应的栈帧从栈顶弹出,返回值传递给上一层调用。
这个“弹栈”和返回值传递的过程持续进行,直到最初的函数调用完成,最终结果被返回。
尾递归优化 (Tail Recursion Optimization - TRO):
某些编程语言(如Scheme、Scala)支持尾递归优化。如果一个递归调用是函数中最后一个操作(即函数在递归调用后不再进行任何其他计算),编译器/解释器可以优化掉新的栈帧创建,直接重用当前栈帧,从而避免栈溢出。
Python不原生支持尾递归优化。 即使你的递归函数是尾递归形式,Python解释器仍然会为每次递归调用创建新的栈帧。因此,在Python中,深度很大的递归仍然可能导致栈溢出。对于需要处理大量数据的递归问题,通常建议转换为迭代(循环)实现,或者使用
sys.setrecursionlimit()临时增加递归深度(但要小心内存消耗)。
(1)阶乘函数 (经典递归示例)
1
2
3
4
5
6
7
8
9
10
11
12
13
def factorial(n):
# 0! = 1, 1!= 1
if n < 0 :
raise ValueError("阶乘不支持负数")
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
res0 = factorial(0)
res1 = factorial(1)
res5 = factorial(5)
res99 = factorial(99)
print(f"0!是:{res0}, 1!是:{res1}, 5!是:{res5}, 99!是:{res99}")

(2)斐波那契数列 (低效但直观的递归示例)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# F(n) = F(n-1) + F(n-2)
# 基本情况: F(0) = 0, F(1) = 1
# 基本情况: F(2) = F(0) + F(1)
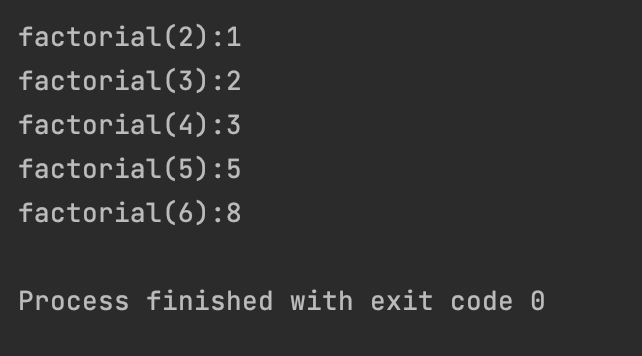
def fibonacci(n):
if n < 0:
raise ValueError("斐波那契不支持负数")
if n == 0:
return 0
if n == 1:
return 1
return fibonacci(n - 2) + fibonacci(n - 1)
res2 = fibonacci(2)
print(f'factorial(2):{res2}')
print(f'factorial(3):{fibonacci(3)}')
print(f'factorial(4):{fibonacci(4)}')
print(f'factorial(5):{fibonacci(5)}')
print(f'factorial(6):{fibonacci(6)}')
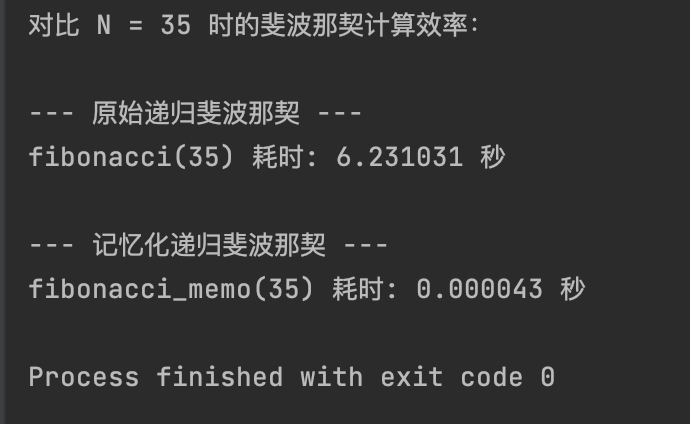
实际上,上述斐波那契函数存在大量重复计算,效率很低。通常会使用动态规划(记忆化)或迭代方式优化。
下面是优化后的斐波那契 (使用字典进行记忆化):
1
2
3
4
5
6
7
8
9
10
11
12
def fibonacci_memo(n, memo={}):
if n < 0:
raise ValueError("斐波那契不支持负数")
if n in memo:
return memo[n]
if n == 0:
return 0
if n == 1:
return 1
result = fibonacci_memo(n - 1, memo) + fibonacci_memo(n - 2, memo)
memo[n] = result
return result
一个效率对比的测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# --- 效率对比 ---
test_n = 35 # 选择一个较大的 N 值来体现效率差异
print(f"对比 N = {test_n} 时的斐波那契计算效率:\n")
# 测量原始递归函数
# setup:定义要测试的函数
# stmt:要执行的代码语句
# number:执行的次数
print("--- 原始递归斐波那契 ---")
try:
time_original = timeit.timeit(f'fibonacci({test_n})', globals=globals(), number=1)
print(f"fibonacci({test_n}) 耗时: {time_original:.6f} 秒")
except RecursionError:
print(f"fibonacci({test_n}) 发生递归深度错误,无法计算或耗时过长。")
except Exception as e:
print(f"fibonacci({test_n}) 发生错误: {e}")
print("\n--- 记忆化递归斐波那契 ---")
try:
time_memo = timeit.timeit(f'fibonacci_memo({test_n})', globals=globals(), number=1)
print(f"fibonacci_memo({test_n}) 耗时: {time_memo:.6f} 秒")
except Exception as e:
print(f"fibonacci_memo({test_n}) 发生错误: {e}")
(3)递归设置最大深度 (慎用,可能导致内存问题)
1
2
3
4
5
import sys
print(f"\n默认递归深度限制: {sys.getrecursionlimit()}")
sys.setrecursionlimit(2000) # 可以尝试增加,但要小心
print(f"新的递归深度限制: {sys.getrecursionlimit()}")
(4)递归遍历目录 (示例)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import os
def list_files_recursive(path, indent=0):
print(" " * indent + f"Listing: {os.path.basename(path)}/")
try:
for item in os.listdir(path):
item_path = os.path.join(path, item)
if os.path.isdir(item_path):
list_files_recursive(item_path, indent + 1) # 递归调用
else:
print(" " * (indent + 1) + item)
except PermissionError:
print(" " * (indent + 1) + "[Permission Denied]")
except FileNotFoundError:
print(" " * (indent + 1) + "[Path Not Found]")
# 创建一个简单的测试目录结构
# import shutil
# if os.path.exists("test_dir"):
# shutil.rmtree("test_dir")
# os.makedirs("test_dir/subdir1/subsubdir", exist_ok=True)
# os.makedirs("test_dir/subdir2", exist_ok=True)
# with open("test_dir/file1.txt", "w") as f: f.write("hello")
# with open("test_dir/subdir1/file2.txt", "w") as f: f.write("world")
# print("\n--- 递归遍历目录示例 ---")
# list_files_recursive("test_dir")
# shutil.rmtree("test_dir") # 清理测试目录