1、字符串的驻留机制
字符串驻留是Python(以及其他一些语言)为优化内存使用和提高字符串比较效率而采用的一种机制。它会为某些短的、简单的字符串在内存中维护一个唯一的副本,当创建相同内容的字符串时,直接引用这个副本而不是创建新的对象。
在Python中,字符串是不可变的序列。为了提高性能,Python解释器会对其内部的某些字符串进行“驻留”(Interning)。这意味着如果两个或多个字符串变量持有相同内容的特定类型字符串,它们可能实际上指向内存中的同一个字符串对象。这样可以减少内存消耗,并在比较这些字符串时加速操作,因为只需要比较它们的内存地址(id)即可。
【1】哪些字符串会被驻留?
通常,满足以下条件的字符串更容易被驻留:
● 由字母、数字、下划线组成的短字符串。
● 在编译时确定的字符串字面量(例如直接在代码中定义的 s = “hello”)。
● 空字符串 ““。
● 单个字符的字符串。
驻留机制的几种情况(交互模式)
- 字符串的长度为0或1时
- 符合标识符的字符串
- 字符串只在编译时进行驻留,而非运行时
- [-5,256]之间的整数数字
交互模式指的是:
PyCharm对字符串进行了优化处理
【2】哪些字符串通常不会被驻留?
● 包含空格、特殊字符或非ASCII字符的字符串。
● 通过运行时拼接、操作生成的字符串。
● 从外部输入(如文件读取、网络请求)获得的字符串。
Python解释器在启动时会预先创建或在运行时遇到特定模式的字符串时,将其存储在一个内部的“驻留池”(intern pool)中。当代码中出现字符串字面量时,解释器会首先检查驻留池中是否已经存在相同内容的字符串。如果存在,就直接返回现有字符串对象的引用;如果不存在,则创建新的字符串对象并将其添加到驻留池中,然后返回新对象的引用。
is 运算符用于比较两个对象的内存地址,而
==运算符用于比较两个对象的值。通过观察 is 运算符的结果,可以判断字符串是否被驻留。在需要进行字符串拼接时建议使用 str类型的join方法,而非
+,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率要比”+“效率高
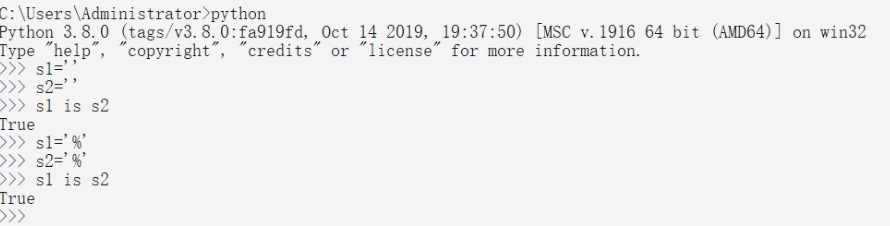
【1】简单的字符串字面量通常会被驻留
1
2
3
4
5
s1 = "Hello"
s2 = "Hello"
print(s1 is s2) # 比较id
print(id(s1), id(s2))
print(s1 == s2) # 比较值
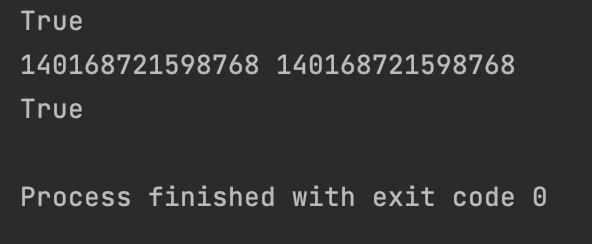
【2】包含空格或特殊字符的字符串通常不会被驻留 (但也不是绝对,取决于Python版本和实现细节)
1
2
3
4
5
s3 = "Hello World"
s4 = "Hello World"
print(s3 is s4) # 比较id
print(id(s3), id(s4))
print(s3 == s4) # 比较值
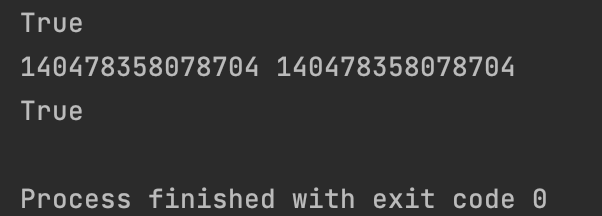
【3】运行时拼接的字符串通常不会被驻留
1
2
3
4
5
6
7
8
str1 = "Hello World"
str2 = "Hello"
str3 = str2 + " World"
print(str1)
print(str3)
print(str1 == str3) # 值相同 返回True
print(str1 is str3) # 地址不同 返回False
print(id(str1), id(str3))
【4】可以强制驻留字符串 (sys.intern)
1
2
3
4
5
import sys
str4 = sys.intern("very_long_string_for_interning_test_123")
str5 = sys.intern("very_long_string_for_interning_test_123")
print(str4 == str5)
print(str4 is str5)
2、字符串的常用操作
Python字符串提供了一系列内置方法,用于处理、查找、替换、分割、连接以及修改字符串的大小写和格式等。这些方法都是非破坏性的,即它们会返回一个新的字符串,而不是修改原始字符串。
由于字符串是不可变的,所有对字符串的操作都不会改变原字符串,而是返回一个新的字符串对象。掌握这些常用操作对于高效地处理文本数据至关重要。
字符串的不可变性是其核心。当执行
s.replace('a', 'b')这样的操作时,Python不是在 s 所在的内存地址上修改字符,而是在内部创建一个新的字符串,将替换后的内容写入新字符串的内存空间,然后返回这个新字符串的引用。原字符串 s 仍然存在于内存中,其内容保持不变,直到没有引用指向它时才会被垃圾回收。这种设计简化了字符串的管理,并使得字符串在多线程环境下更安全,因为它不需要担心并发修改的问题。
【1】查找和计数
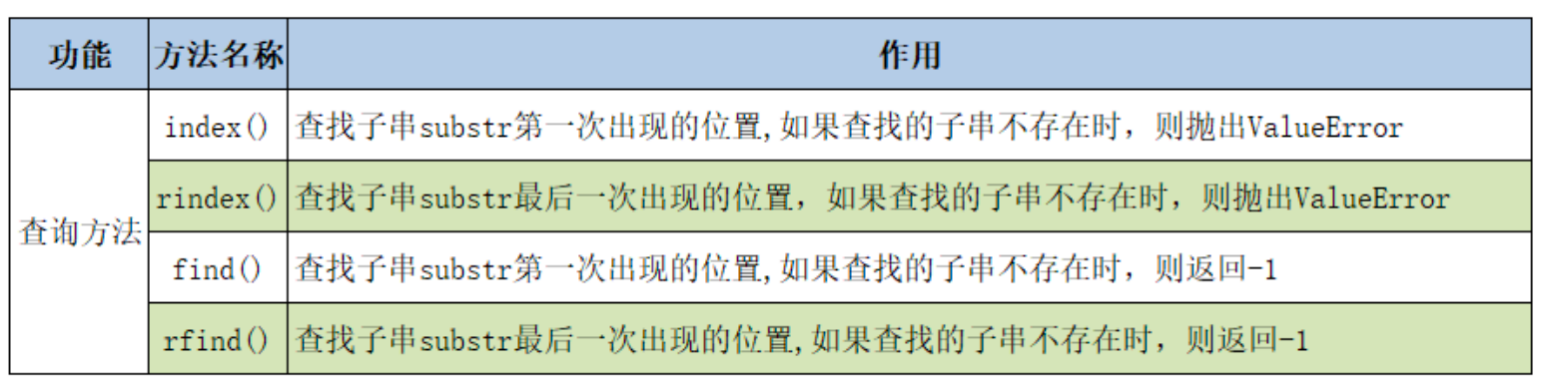
- count(): 统计子字符串出现的次数
- find(): 查找子字符串第一次出现的位置,如果未找到则返回 -1
- rfind(): 查找子字符串最后一次出现的位置
- index(): 查找子字符串第一次出现的位置,如果未找到则报错 ValueError
1
2
3
4
5
6
7
8
9
10
11
12
my_string = " Hello Python World! Python is great. "
print(f"原字符串:{my_string}")
print(f"Python在字符串中出现的次数:{my_string.count('Python')}")
print(f"Python第一次出现的位置:{my_string.find('Python')}")
print(f"Java第一次出现的位置:{my_string.find('java')}")
print(f"Python最后一次出现的位置:{my_string.rfind('Python')}")
print(f"Python第一次出现的位置(index):{my_string.index('Python')}")
try:
print(f"Java第一次出现的位置:{my_string.index('java')}")
except ValueError as e:
print(f"报错:{e}")
【2】替换
- replace(): 替换子字符串,返回新字符串,可以指定替换次数
1
2
3
4
5
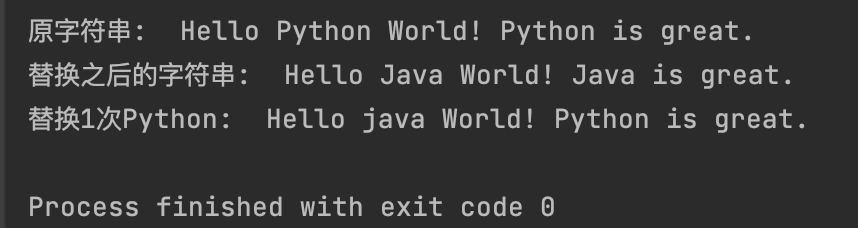
print(f"原字符串:{my_string}")
new_String = my_string.replace("Python", "Java")
print(f"替换之后的字符串:{new_String}")
new_String2 = my_string.replace("Python", "java", 1)
print(f"替换1次Python:{new_String2}")
【3】分割和连接
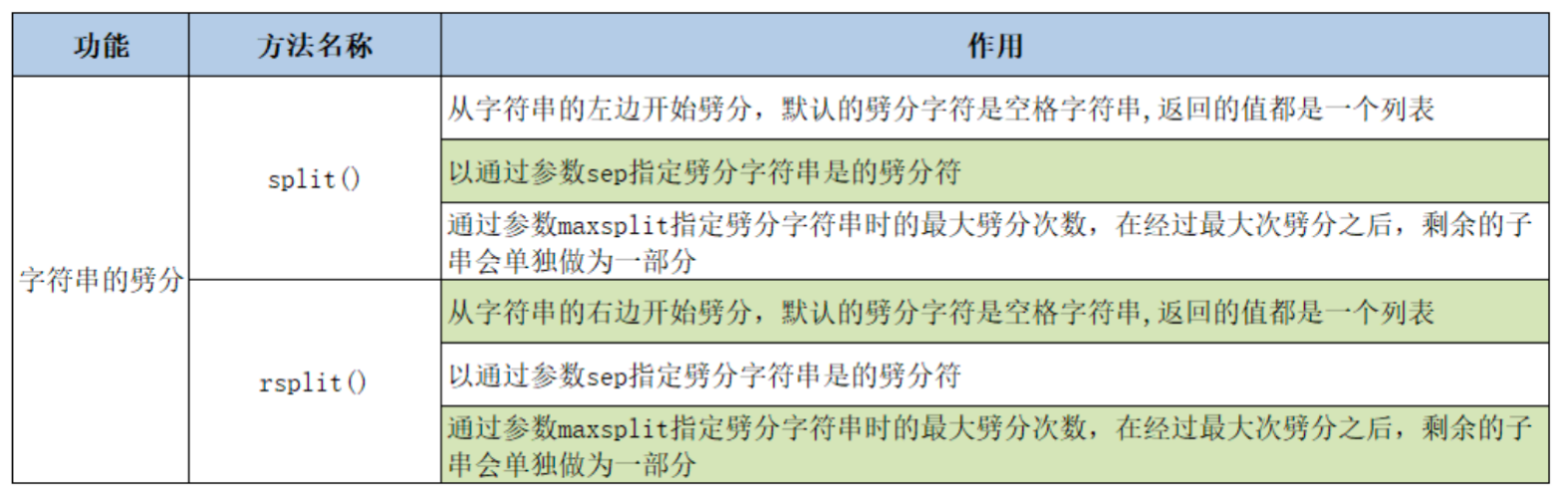
- split(): 根据指定分隔符分割字符串,返回列表
- strip() 常常用于去除首尾空白后进行分割
- splitlines(): 按行分割
1
2
3
4
5
6
7
print(f"原始字符串:{my_string}")
# 注意:strip先去除字符串前后的空格,然后再用空字符串分割
list_from_str = my_string.strip().split(" ")
print(f"分割后的字符串列表:{list_from_str}")
str_multi_lines = "Line1\nLine2\r\nLine3"
list_from_multi_lines = str_multi_lines.splitlines()
print(f"按行分割结果:{list_from_multi_lines}")

- join(): 使用指定字符串连接序列中的元素
1
2
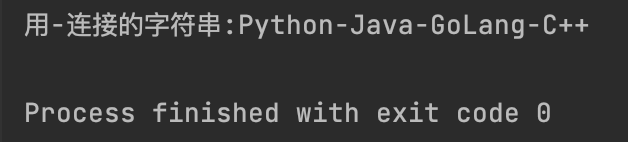
str_from_join = "-".join(["Python", "Java", "GoLang", "C++"])
print(f"用-连接的字符串:{str_from_join}")
关于maxsplit参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
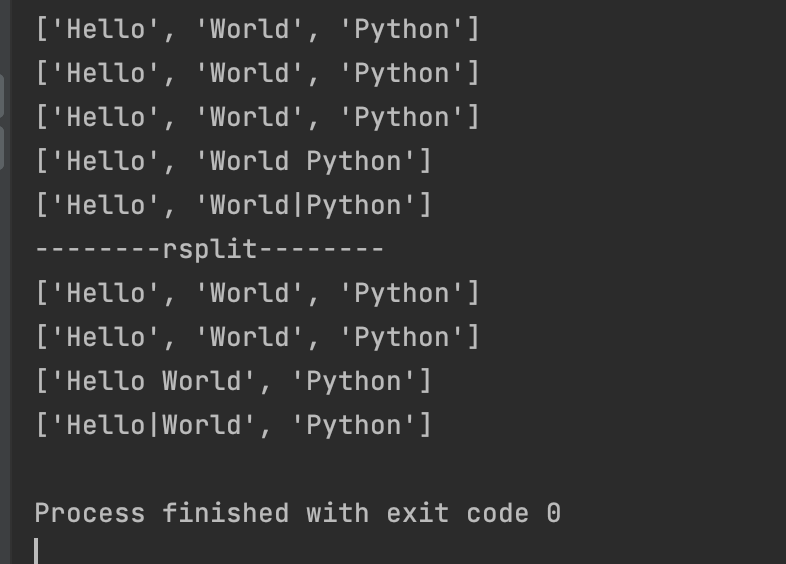
s1 = "Hello World Python"
print(s1.split()) # 默认空格进行分割
s2 = "Hello|World|Python"
print(s2.split("|")) # sep可以省略
print(s2.split(sep="|"))
# maxsplit 指定分出几个即可
print(s1.split(sep=" ", maxsplit=1))
print(s2.split(sep="|", maxsplit=1))
print("--------rsplit--------")
# rsplit
print(s1.rsplit())
print(s2.rsplit("|"))
print(s1.rsplit(sep=" ", maxsplit=1))
print(s2.rsplit(sep="|", maxsplit=1))
【4】去除空白
- strip(): 去除字符串两端的空白字符 (空格, 换行符, 制表符等)
- lstrip(): 去除字符串左端的空白字符
- rstrip(): 去除字符串右端的空白字符
1
2
3
4
5
6
7
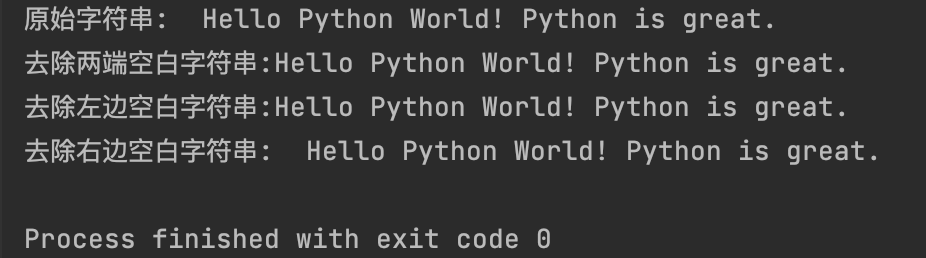
print(f"原始字符串:{my_string}")
strip_str_all = my_string.strip()
print(f"去除两端空白字符串:{strip_str_all}")
strip_str_left = my_string.lstrip()
print(f"去除左边空白字符串:{strip_str_left}")
strip_str_right = my_string.rstrip()
print(f"去除右边空白字符串:{strip_str_right}")
【5】大小写转换
- lower(): 转换为小写
- upper(): 转换为大写
- capitalize(): 首字母大写,其余小写
- title(): 每个单词首字母大写
- swapcase(): 大小写互换
1
2
3
4
5
6
7
8
9
10
11
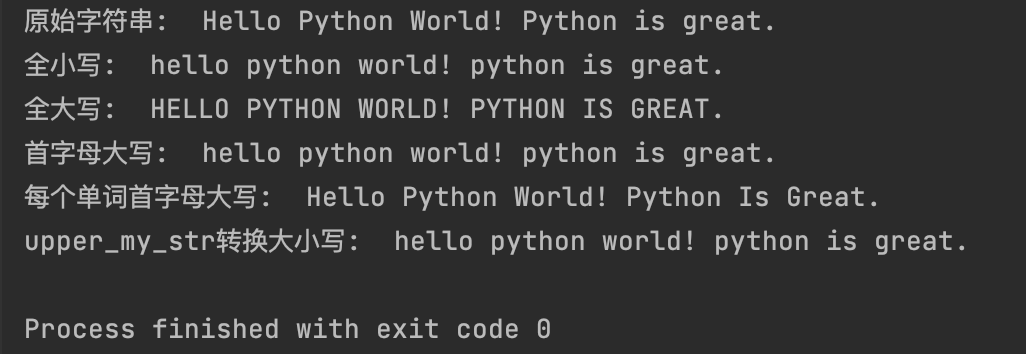
print(f"原始字符串:{my_string}")
lower_my_str = my_string.lower()
print(f"全小写:{lower_my_str}")
upper_my_str = my_string.upper()
print(f"全大写:{upper_my_str}")
capitalize_my_str = my_string.capitalize()
print(f"首字母大写:{capitalize_my_str}")
title_my_str = my_string.title()
print(f"每个单词首字母大写:{title_my_str}")
swapcase_upper_my_str = upper_my_str.swapcase()
print(f"upper_my_str转换大小写:{swapcase_upper_my_str}")
【6】判断类操作 (返回 True/False)
- startswith(): 判断是否以指定前缀开始
- endswith(): 判断是否以指定后缀结束
- isdigit(): 判断是否只包含数字 (False for empty string or contains other chars)
- isalpha(): 判断是否只包含字母
- isalnum(): 判断是否只包含字母和数字
- isspace(): 判断是否只包含空白字符
1
2
3
4
5
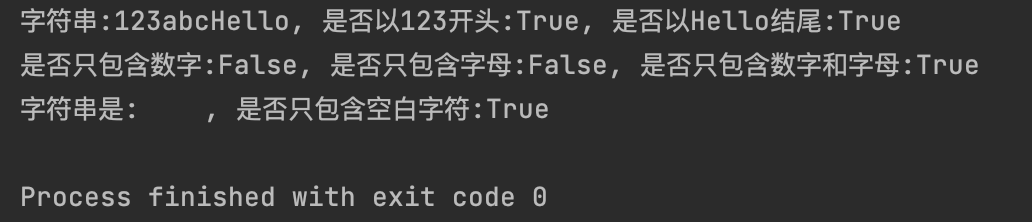
my_str = "123abcHello"
print(f"字符串:{my_str}, 是否以123开头:{my_str.startswith('123')}, 是否以Hello结尾:{my_str.endswith('Hello')}")
print(f"是否只包含数字:{my_str.isdigit()}, 是否只包含字母:{my_str.isalpha()}, 是否只包含数字和字母:{my_str.isalnum()}")
my_str2 = " "
print(f"字符串是:{my_str2}, 是否只包含空白字符:{my_str2.isspace()}")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
s='hello,python'
print('1.',s.isidentifier()) #False
print('2.','hello'.isidentifier()) #True
print('3.','张三_'.isidentifier()) #True
print('4.','张三_123'.isidentifier()) #True
print('5.','\t'.isspace()) #True
print('6.','abc'.isalpha()) #True
print('7.','张三'.isalpha()) #True
print('8.','张三1'.isalpha()) #False
print('9.','123'.isdecimal()) #True
print('10.','123四'.isdecimal()) # False
print('11.','ⅡⅡⅡ'.isdecimal()) # False
print('12.','123'.isnumeric()) #True
print('13.','123四'.isnumeric())#True
print('14.','ⅡⅡⅡ'.isnumeric()) #True
print('15.','abc1'.isalnum()) #True
print('16.','张三123'.isalnum()) #True
print('17.','abc!'.isalnum()) #False
【7】对齐
1
2
3
4
5
6
7
8
9
10
11
12
13
14
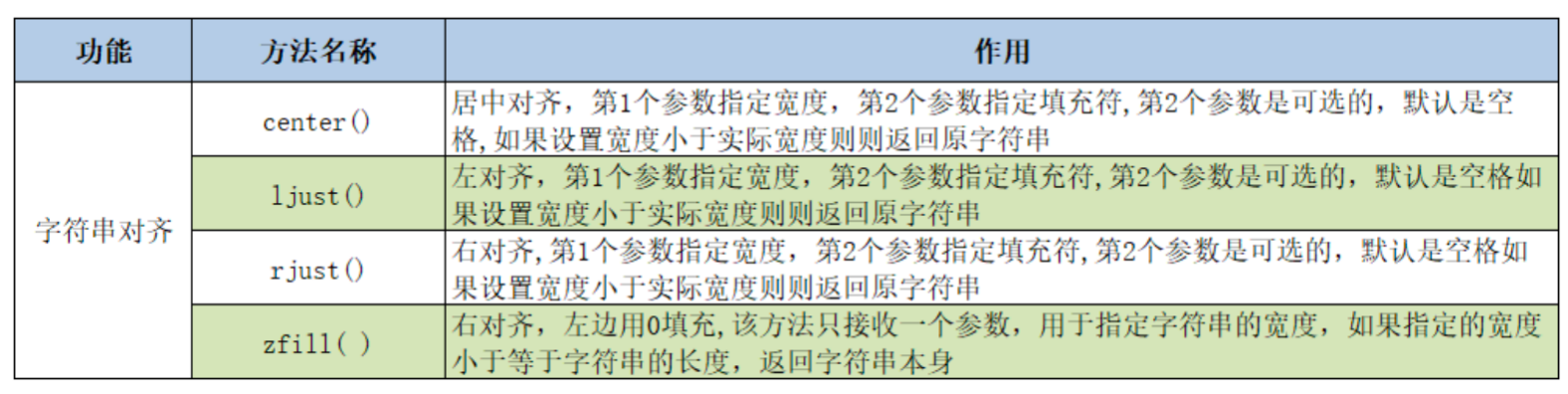
s = "Hello"
s_num = "123"
print(s.center(10))
print(s.center(10, "*"))
print(f"宽度小于实际宽度,返回原字符串:{s.center(3)}")
print(s.ljust(10))
print(s.ljust(10, "*"))
print(s.ljust(3, "*"))
print(s.rjust(10))
print(s.rjust(10, "*"))
print(s.rjust(3, "*"))
print(s_num.zfill(5))
s_signed_num = "-42"
print(s_signed_num.zfill(7)) # 填充在-号之后
3、字符串的比较
Python中字符串的比较是基于字符的Unicode编码值进行的,遵循字典序(lexicographical order)。可以使用比较运算符 (==, !=, <, >, <=, >=) 进行比较。
字符串的比较遵循字典序原则。这意味着比较从字符串的第一个字符开始,逐个字符进行比较。如果两个字符串在某个位置的字符不相等,那么它们的Unicode编码值决定了哪个字符串“更大”或“更小”。如果一个字符串是另一个字符串的前缀,那么较短的字符串被认为是“小于”较长的字符串(例如 “apple” < “applepie”)。
● == 和 !=:检查字符串的内容是否相等。
● <, >, <=, >=:基于字典序进行比较。
【1】相等性比较 (== 和 !=) 注意:Python是大小写敏感的语言
1
2
3
4
5
6
7
8
9
10
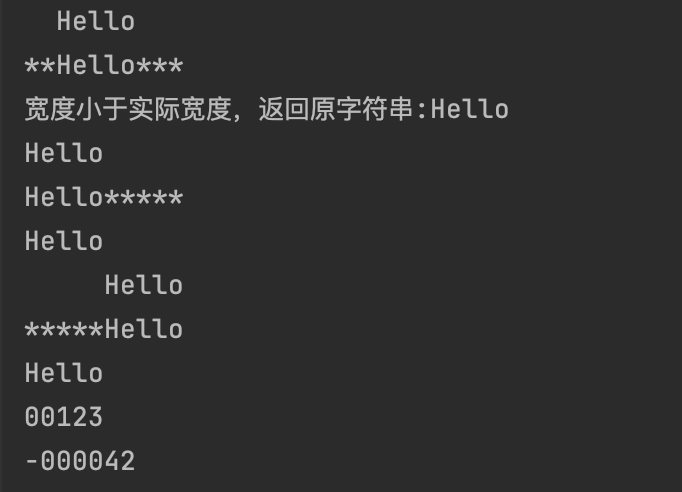
s1 = "apple"
s2 = "banana"
s3 = "Apple"
s4 = "apple"
s5 = "applepie"
print(f"s1: '{s1}', s2: '{s2}', s3: '{s3}', s4: '{s4}', s5: '{s5}'")
print(f"s1 == s4:{s1 == s4}")
print(f"s1 == s3:{s1 == s3}")
print(f"s1 != s4:{s1 != s4}")
【2】字典序比较 (<, >, <=, >=)
1
2
3
4
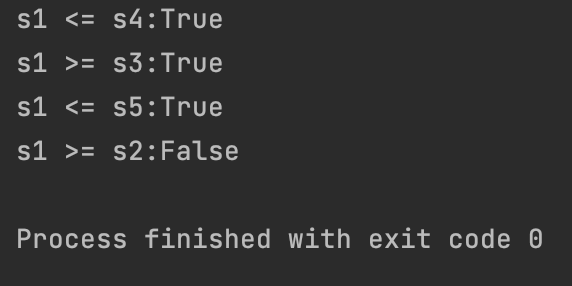
print(f"s1 <= s4:{s1 <= s4}")
print(f"s1 >= s3:{s1 >= s3}")
print(f"s1 <= s5:{s1 <= s5}")
print(f"s1 >= s2:{s1 >= s2}")
【3】比较中文 (也是基于Unicode码点)
1
2
3
4
5
6
7
s_chinese1 = "你好"
s_chinese2 = "世界"
s_chinese3 = "你好啊"
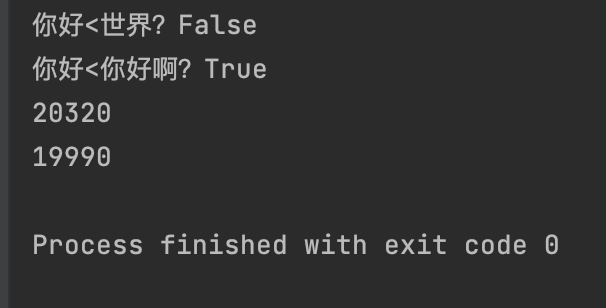
print(f"你好<世界?{s_chinese1 < s_chinese2}")
print(f"你好<你好啊?{s_chinese1 < s_chinese3}")
print(ord(s_chinese1[0]))
print(ord(s_chinese2[0]))
4、字符串的切片操作
字符串切片是一种强大的操作,允许你从字符串中提取子串。它使用方括号 [] 结合冒号 : 来指定起始索引、结束索引(不包含)和步长。
字符串切片是Python序列(如列表、元组、字符串)通用的操作。它的语法是 [start:end:step]。
● start:切片开始的索引(包含)。如果省略,默认为 0(从头开始)。
● end:切片结束的索引(不包含)。如果省略,默认为字符串的长度(直到末尾)。
● step:切片的步长(默认为 1)。可以设置为负数以倒序切片。
索引可以是正数(从0开始)或负数(从-1开始,表示倒数第一个字符)。
字符串切片操作本质上是创建原字符串的一个新的副本。Python会根据切片参数计算出需要包含的字符,然后将这些字符复制到一个新的字符串对象中并返回其引用。由于字符串是不可变的,切片操作不会影响原始字符串。这与C/C++等语言中可能返回原字符串子视图(引用)不同,Python的切片总是返回一个独立的新字符串。
【1】基本切片 (start:end)
1
2
3
4
5
6
7
8
text = "Python Programming"
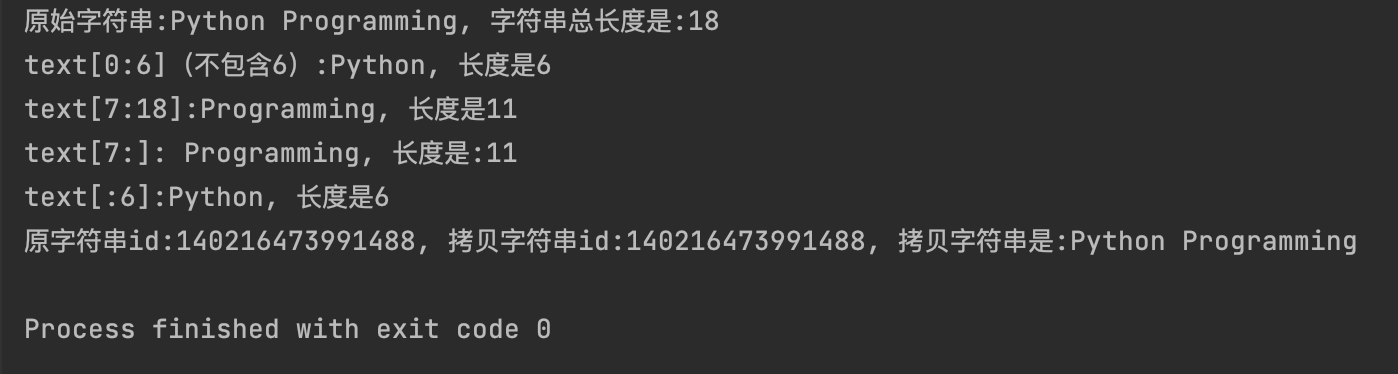
print(f"原始字符串:{text}, 字符串总长度是:{len(text)}")
print(f"text[0:6](不包含6):{text[0:6]}, 长度是{len(text[0:6])}")
print(f"text[7:18]:{text[7:18]}, 长度是{len(text[7:18])}")
print(f"text[7:]: {text[7:]}, 长度是:{len(text[7:18])}")
print(f"text[:6]:{text[:6]}, 长度是{len(text[:6])}")
copy_text = text[:]
print(f"原字符串id:{id(text)}, 拷贝字符串id:{id(copy_text)}, 拷贝字符串是:{copy_text}")
浅拷贝:仅复制对象本身,嵌套对象仍共享引用。使用 copy.copy() 或对象的 copy() 方法。
深拷贝:递归复制对象及其所有嵌套对象,创建完全独立的副本。使用 copy.deepcopy()。
上面的
[:]也属于浅拷贝。
【2】负数索引切片
1
2
3
4
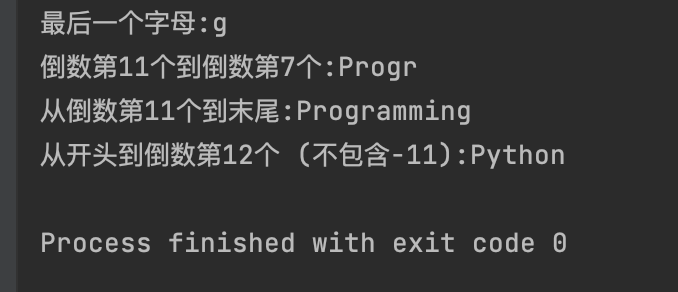
print(f"最后一个字母:{text[-1]}")
print(f"倒数第11个到倒数第7个:{text[-11:-6]}")
print(f"从倒数第11个到末尾:{text[-11:]}")
print(f"从开头到倒数第12个 (不包含-11):{text[:-12]}")
【3】带步长切片 (start:end:step)
1
2
3
4
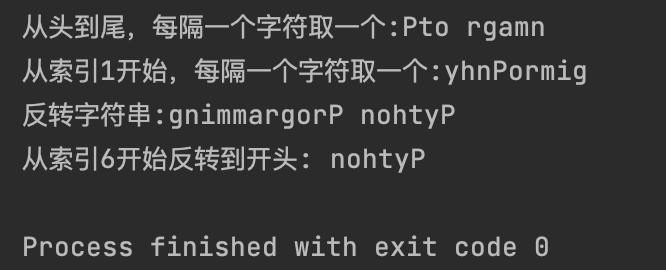
print(f"从头到尾,每隔一个字符取一个:{text[::2]}")
print(f"从索引1开始,每隔一个字符取一个:{text[1::2]}")
print(f"反转字符串:{text[::-1]}")
print(f"从索引6开始反转到开头:{text[6::-1]}")
【4】超出范围的索引 (不会报错,只会返回有效部分)
1
2
print(f"索引超出范围, 正常返回整个字符串:{text[0:100]}")
print(f"字符串长度:{len(text)}, 返回空字符串,不报错:{text[20:]}")

5、格式化字符串
字符串格式化是将变量或表达式的值插入到字符串模板中的过程。Python提供了多种格式化字符串的方法:旧式的 % 运算符、str.format() 方法和现代的 f-string(格式化字符串字面量)。
字符串格式化是构建动态文本输出的关键。
-
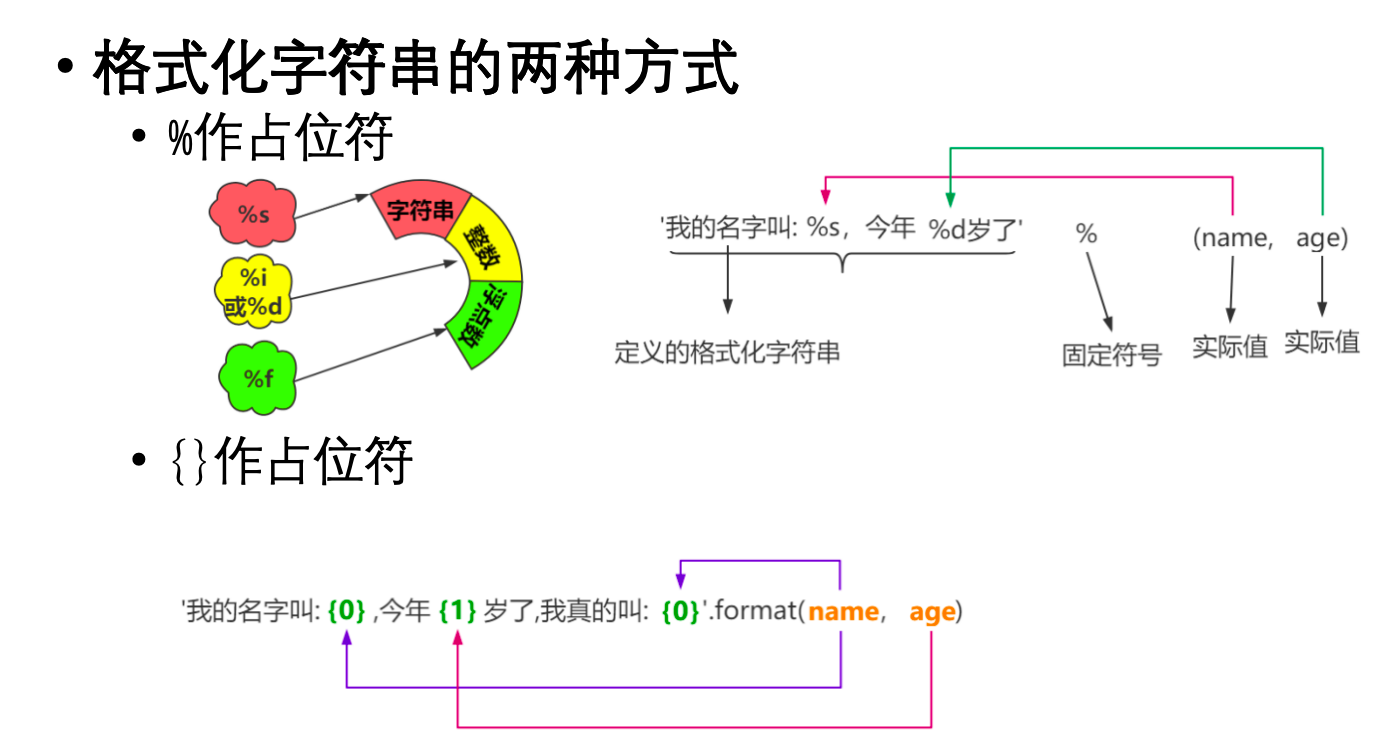
%运算符 (旧式): 类似于C语言的 printf 风格。使用%s(字符串),%d(整数),%f(浮点数) 等占位符。 -
str.format()方法: 更灵活,使用{}作为占位符,可以通过位置或关键字参数填充。支持更复杂的格式化选项(如对齐、精度等)。 -
f-string (格式化字符串字面量) (推荐): Python 3.6+ 引入,最现代、简洁、高效的方式。在字符串前加
f或F,并在{}中直接嵌入变量或表达式。
无论哪种方法,其核心都是将字符串模板中的占位符或表达式替换为实际的值,并根据指定的格式规则(如精度、对齐)生成一个新的字符串。
●
%运算符: 内部实现会将占位符和值进行匹配,然后将值转换为字符串并插入到相应的位置。这种方式在处理不同类型时需要精确匹配占位符类型,否则可能导致 TypeError。●
str.format(): 采用了更灵活的解析器,它会扫描{}占位符,并根据其内部的字段名、位置或格式说明符从 format() 的参数中查找对应的值。这种方法通常通过创建一个“迷你语言”来解析格式说明符,从而实现复杂的格式化。● f-string: 在编译时直接将表达式的值嵌入到字符串中。这使得 f-string 在运行时不需要额外的解析步骤,因此通常比
format()或%运算符更快。它本质上是语法糖,Python解释器在编译阶段就会将其转换为一系列字符串拼接和转换的操作。f-string能够直接访问当前作用域的变量,这使得它非常直观和强大。
代码学习:
【1】使用 % 运算符 (旧式)
1
2
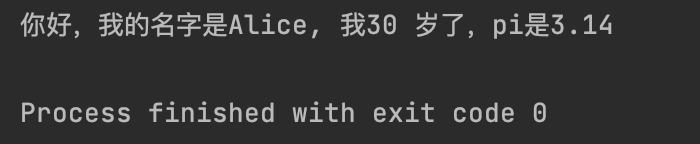
message_percent = "你好,我的名字是%s, 我%d 岁了,pi是%.2f" %(name, age, pi)
print(message_percent)
如果用格式化字典:
1
2
3
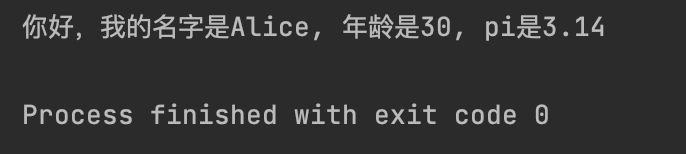
data_dict = {"name": "Bob", "age": 23}
message_dict_percent = "姓名是:%(name)s, 年龄是%(age)d" %data_dict
print(message_dict_percent)

【2】使用 str.format() 方法
1
2
message_format_pos = "你好,我的名字是{}, 年龄是{}, pi是{:.2f}".format(name, age, pi)
print(message_format_pos)
关键字参数:
1
2
message_format_kw = "[kw]:你好,我的名字是{n}, 年龄是{a},pi的估计值是{p:.2f}".format(n = name, a = age, p = pi)
print(message_format_kw)

混合使用:
1
2
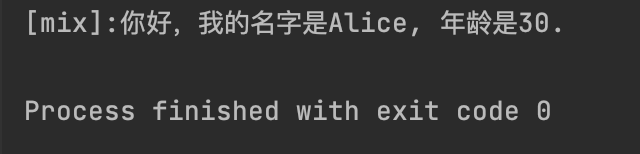
message_format_mix = "[mix]:你好,我的名字是{}, 年龄是{a}.".format(name, a = age)
print(message_format_mix)
对齐和填充:这个倒是挺有意思的
1
2
3
4
5
6
7
8
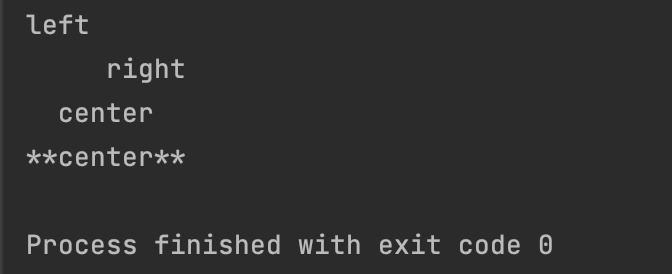
# 左对齐,宽度10
print("{:<10}".format("left"))
# 右对齐,宽度10
print("{:>10}".format("right"))
# 居中,宽度10
print("{:^10}".format("center"))
# 居中,用 * 填充
print("{:*^10}".format("center"))
【3】使用 f-string (推荐)
1
2
message_fstring = f"大家好,我的名字是{name}, 我今年{age}岁了, 我还知道pi大约是{pi:.2f}"
print(message_fstring)

嵌入表达式:
1
print(f"10 divided by 3 is {10/3:.3f}")

调用函数:
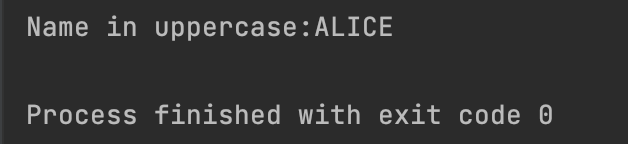
1
print(f"Name in uppercase:{name.upper()}")
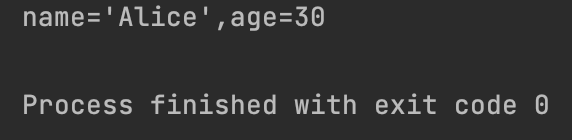
可以使用调试等号 = (Python 3.8+)
1
print(f"{name=},{age=}")
【4】指定宽度的格式化:当需要确保数字在输出时占据固定的列宽,以便于对齐表格数据或生成整齐的报告时,宽度修饰符非常有用。它会自动在不足宽度的左侧填充空格,实现右对齐效果。
1
2
3
4
5
6
7
8
9
10
11
12
pi = 3.1415926
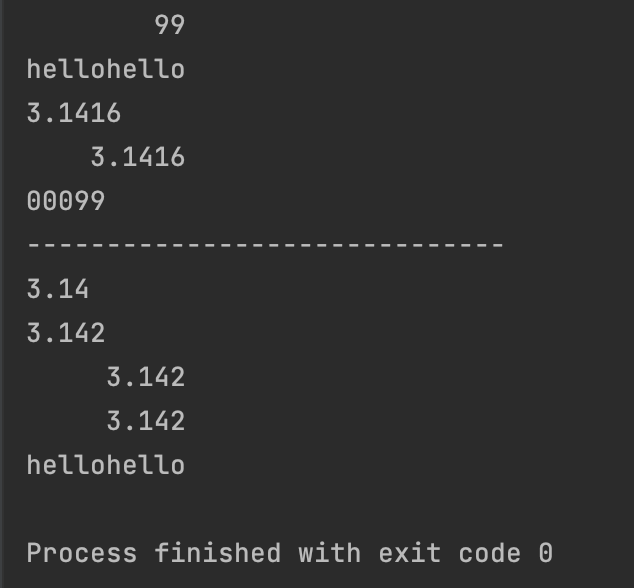
print("%10d" % 99)
print("hellohello") # 为了验证宽度而输出,一共10
print("%.4f"%pi)
print("%10.4f"%pi) # 同时指定宽度和精度
print('{:05d}'.format(99))
print("------------------------------")
print("{0:.3}".format(pi)) # 0表示占位符,表示第几个数,这里的3是有效数字
print("{0:.3f}".format(pi)) # 0表示占位符,表示第几个数,这里的3是小数点后几位
print("{0:10.3f}".format(pi)) # 0表示占位符,表示第几个数,这里的3是小数点后几位,10是指宽度
print("{:10.3f}".format(pi)) # 占位符0可以省略不写
print("hellohello")
6、字符串的编码转换
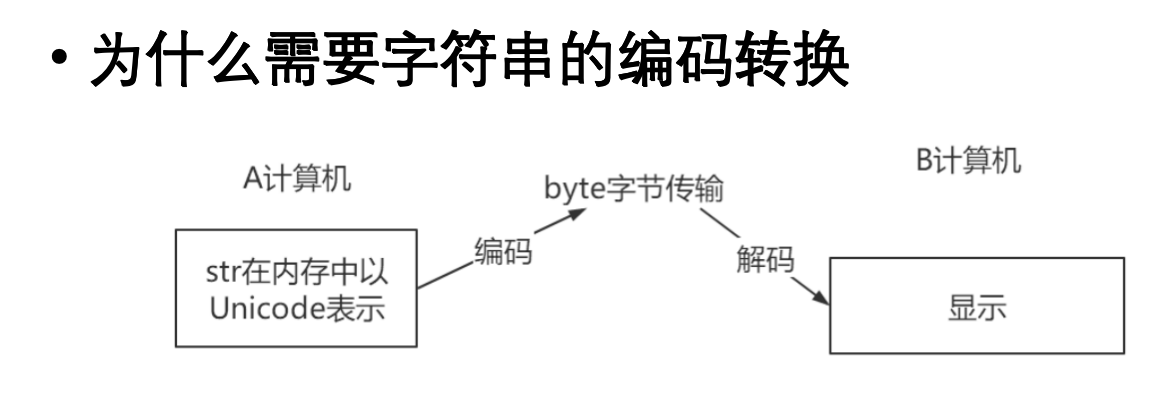
字符串的编码转换涉及将字符串(Unicode)转换为字节串(bytes)以及将字节串解码为字符串。这是处理文件I/O、网络通信以及不同字符集之间交互的关键。

在Python 3中,字符串默认是Unicode(str 类型),它是一种抽象的字符表示,不关心字符在内存中是如何存储的。而字节串(bytes 类型)是实际存储在内存或磁盘上的二进制数据,它由0-255范围内的整数组成,表示字节序列。
● 编码(Encoding): 将 Unicode 字符串转换为字节串。这个过程需要指定一个编码格式(如 ‘UTF-8’, ‘GBK’, ‘Latin-1’ 等),将字符映射为字节序列。
- 方法:
str.encode(encoding='utf-8', errors='strict')
● 解码(Decoding): 将字节串转换为 Unicode 字符串。这个过程同样需要指定一个编码格式,将字节序列解析为字符。
- 方法:
bytes.decode(encoding='utf-8', errors='strict')
errors 参数用于指定编码/解码过程中遇到无法处理的字符/字节时如何处理:通常在处理文件I/O时,尤其是不确定文件编码时,会用到 errors 参数
● ‘strict’ (默认): 遇到无法编码/解码的字符/字节时,抛出 UnicodeEncodeError 或 UnicodeDecodeError。
● ‘ignore’: 忽略无法编码/解码的字符/字节。
● ‘replace’: 用问号或其他占位符替换无法编码/解码的字符/字节。
● ‘xmlcharrefreplace’ (仅编码): 用XML字符引用替换。
● ‘backslashreplace’ (仅编码): 用反斜杠转义序列替换。
计算机内部存储和传输数据都是以字节的形式。当我们在Python中处理文本时,字符串是Unicode对象,它表示字符的概念,而不是它们底层的二进制表示。要将这些字符发送到文件、网络或任何需要二进制数据的目标,就需要进行“编码”。编码器会根据所选的编码规则(例如UTF-8),将每个Unicode字符映射为一串特定的字节。
反之,当从文件、网络或其他二进制源读取数据时,我们得到的是字节串。为了将这些字节理解为人类可读的文本,就需要进行“解码”。解码器会根据所选的编码规则,将字节序列解析回其对应的Unicode字符。如果解码器使用的编码与数据实际编码不匹配,就会导致“乱码”或 UnicodeDecodeError。
UTF-8 是一种变长编码,能够表示Unicode中的所有字符,并且对ASCII字符(英文字母、数字等)兼容,是目前Web和跨平台应用中最常用的编码方式。
【1】编码 (字符串 -> 字节串):
Unicode 字符串 (str 类型)
1
2
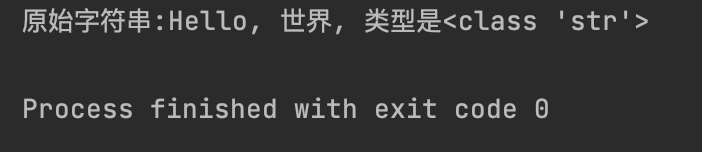
my_string = "Hello, 世界"
print(f"原始字符串:{my_string}, 类型是{type(my_string)}")
(1)使用 UTF-8 编码,注意:中文字符在UTF-8中会占用3个字节
1
2
encoded_utf8 = my_string.encode("utf-8")
print(f"UTF-8编码:{encoded_utf8}, 类型是{type(encoded_utf8)}")

(2)尝试使用 GBK 编码 (假设字符串包含中文),并非所有编码都能处理所有字符,GBK是中国大陆常用编码
1
2
3
4
5
try:
encoded_gbk = my_string.encode("gbk")
print(f"GBK编码:{encoded_gbk}, 类型是{type(encoded_gbk)}")
except UnicodeEncodeError as e :
print(f"报错:{e}")

【2】解码 (字节串 -> 字符串)
(1)使用 UTF-8 解码 (与编码时使用的编码一致)
1
2
decoded_utf8 = encoded_utf8.decode("utf-8")
print(f"UTF解码之后:{decoded_utf8}, 类型是:{type(decoded_utf8)}")

尝试使用错误的编码进行解码 (会导致乱码或报错):
1
2
3
4
5
6
try:
# 假设 encoded_utf8 是用 UTF-8 编码的字节,但尝试用 GBK 解码
s = encoded_utf8.decode('gbk')
print(f"GBK解码后:{s}, 类型是:{type(s)}")
except UnicodeDecodeError as e:
print(f"报错:{e}")

显然出现了乱码
【3】errors 参数的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
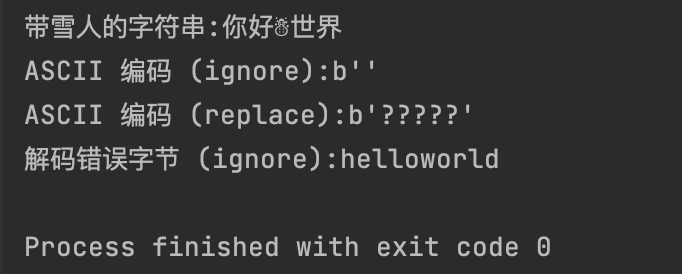
err_s = "你好" + chr(0x2603) + "世界" # chr(0x2603) 是 Unicode 的一个雪人符号
print(f"带雪人的字符串:{err_s}")
# 编码时忽略错误
encoded_ignore = err_s.encode("ascii", errors='ignore')
print(f"ASCII 编码 (ignore):{encoded_ignore}")
# 编码时替换错误
encoded_replace = err_s.encode("ascii", errors="replace")
print(f"ASCII 编码 (replace):{encoded_replace}") # 被替换成问号
# 解码时忽略错误
# 假设我们有一个错误编码的字节串 (例如,一个UTF-8字符串被误认为ASCII编码)
bad_bytes = b'hello\xe4\xbd\xa0\xe5\xa5\xbdworld' # \xe4\xbd\xa0\xe5\xa5\xbd 是 "你好" 的UTF-8编码
decoded_bad_ignore = bad_bytes.decode("ascii", errors="ignore")
print(f"解码错误字节 (ignore):{decoded_bad_ignore}")