Python 字典是一种非常强大的数据结构,用于存储键值对。它在许多编程场景中都非常有用,例如数据查找、配置管理等。
1.什么是字典
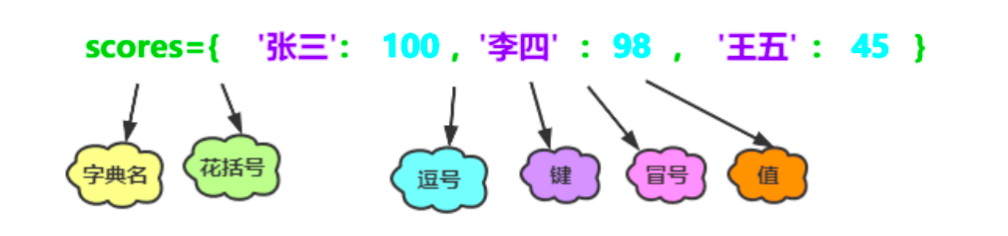
dict:Python内置的数据结构之一,与列表一样是一个可变序列,以键值对的方式存储数据,字典是一个无序的序列
字典是 Python 中一种可变(mutable)、无序(unordered)的键值对(key-value pair)集合。每个键值对都将一个键(key)映射到一个值(value)。
● 键(Key): 字典的键必须是唯一的,且必须是不可变(immutable)的数据类型,如字符串、数字、元组(如果元组只包含不可变元素)。
● 值(Value): 字典的值可以是任何数据类型,包括数字、字符串、列表、元组,甚至另一个字典。值可以重复。
● 无序性: 在 Python 3.7+ 版本中,字典会保持插入顺序。但在早期的 Python 版本中,字典是无序的。尽管如此,从概念上讲,我们仍然将其视为无序集合,不应依赖于特定的顺序来访问元素。
● 可变性: 字典是可变的,这意味着可以添加、删除或修改字典中的键值对。
原理补充:字典的可变性是指其在内存中的存储结构(哈希表)是可以在不重新创建整个对象的情况下进行修改的。可以直接在现有字典上添加、删除或修改键值对,而无需创建新的字典对象。这与字符串或元组等不可变类型形成对比,它们的任何修改操作都会返回一个新的对象。
字典的无序性(在 Python 3.7+ 之前)来源于其底层哈希表的实现。哈希表为了追求高效的查找速度,通过哈希函数将键映射到内存中的任意位置,而不是按照线性顺序存储。因此,元素的物理存储顺序与其逻辑插入顺序无关。Python 3.7+ 引入的保持插入顺序是 CPython 实现的一个优化,它在底层增加了一个额外的结构来记住插入顺序,但这并没有改变字典作为基于哈希的键值对集合的根本性质。
举一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
student_info = {
'name': "张三",
'age': 20,
'major': "计算机科学",
'courses': ["Python编程", "数据结构", "算法分析"]
}
print(student_info)
# 访问字典中的值
print(f"学生姓名:{student_info['name']}")
print(f"学生年龄:{student_info['age']}")
print(f"学生选修课程:{student_info['courses']}")

2.字典的原理
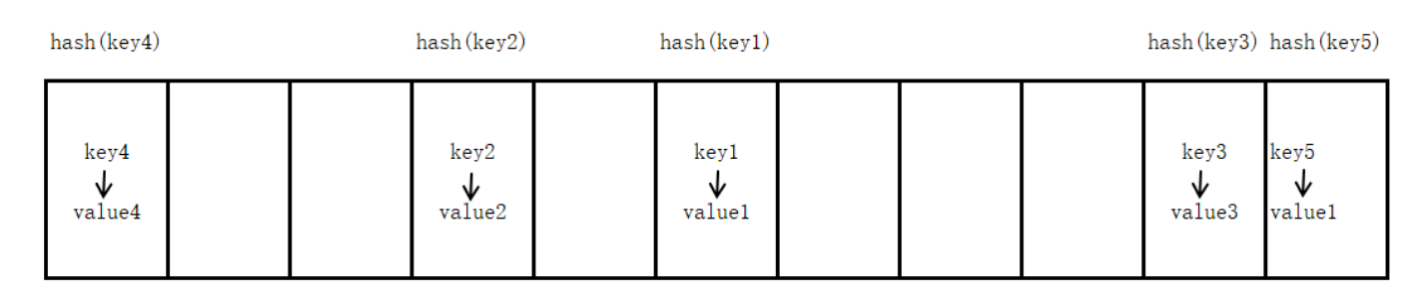
Python 字典的底层实现是基于哈希表(Hash Table)。哈希表是一种数据结构,它通过哈希函数将键映射到数组中的特定位置,从而实现快速的数据查找。
(1)哈希表的工作原理
哈希函数:将一个键(key)放入字典时,Python 会首先对该键应用一个哈希函数。哈希函数会计算出一个整数值,称为哈希值(hash value)。一个好的哈希函数应该能够将不同的键均匀地分布在哈希表的各个位置,并尽量减少冲突。
哈希值通常会通过取模运算(hash_value % array_size)转换为数组的一个索引。这个索引就是该键值对在哈希表底层数组中的存储位置。
不同的键可能会生成相同的哈希值,或者不同的哈希值通过取模运算后映射到相同的数组索引。这种情况称为哈希冲突。Python 字典采用开放寻址法(Open Addressing)来解决冲突。当发生冲突时,系统会按照预定的探测序列(probe sequence)查找下一个可用的空槽来存储键值对。这个探测序列通常是线性的或二次的。
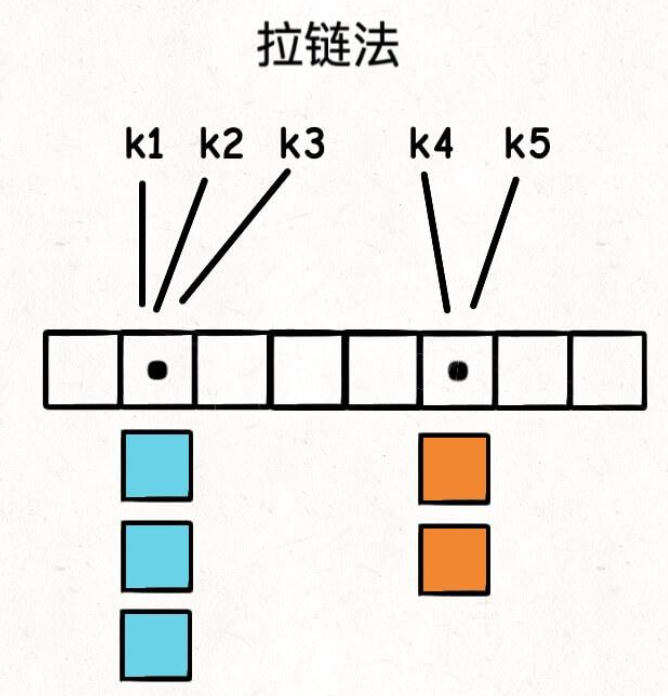
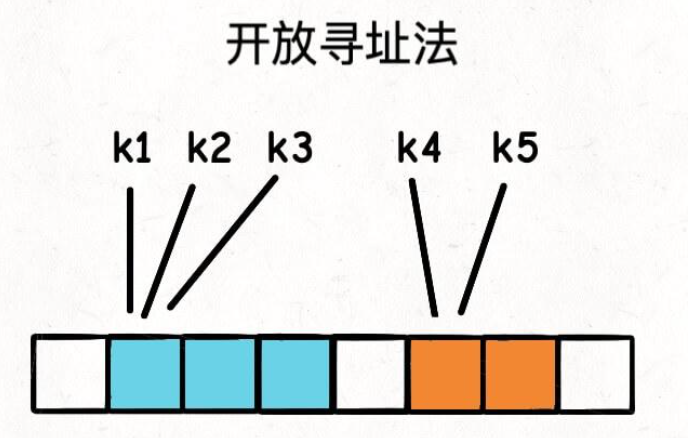
开放寻址法: 不使用链表,而是当哈希冲突发生时,寻找哈希表中的下一个空闲位置。Python 字典的具体实现是探测序列(probe sequence):当一个键的哈希值发生冲突时,Python 会尝试计算一系列新的位置,直到找到一个空闲位置或者找到原有的键。
【动态扩容】当哈希表中的元素数量达到一定比例(称为负载因子,load factor)时,为了维持查询效率,哈希表会自动进行扩容(通常是翻倍),并重新计算所有现有键的哈希值,将它们重新分配到新的更大的哈希表中。这个过程称为rehash,虽然会带来一定的性能开销,但保证了后续操作的平均 O(1) 复杂度。
只有可哈希的对象才能被哈希函数处理并生成哈希值。Python 中内置的不可变类型(如整数、浮点数、字符串、元组)都是可哈希的。自定义对象默认是不可哈希的,除非实现了 hash 和 eq 方法。
(2)字典操作的时间复杂度
● 插入、删除、查找(平均情况): O(1)。由于哈希表的特性,这些操作通常只需要常数时间。
● 插入、删除、查找(最坏情况): O(n)。在极端情况下(例如所有键都发生哈希冲突,或者哈希表退化为链表),这些操作可能会退化为线性时间。但由于 Python 优秀的哈希函数和冲突解决策略,这种情况非常罕见。
● 迭代: O(n)。遍历字典中的所有键值对需要线性时间,因为它需要访问所有存储的元素。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 元组如果只包含不可变元素,也可以作为键
my_tuple = (1, 2, 3, "Hello", 90.90)
mydict = {my_tuple: "value for tuple"}
print(mydict[my_tuple])
# 列表是可变的,不能作为字典的键,会引发 TypeError
try:
list1 = [1, 2, 3]
mydict[list1] = "value for list"
print(mydict[list1])
except TypeError as e:
print(f"报错:{e}") # 报错:unhashable type: 'list'
# 集合是可变的,不能作为字典的键,会引发 TypeError
try:
my_set = {1, 2, 3}
mydict[my_set] = "value for set"
print(mydict[my_set])
except TypeError as e:
print(f"报错:{e}") # 报错:unhashable type: 'set'
3.字典的创建与删除
(1)字典的创建
字典的创建本质上是在内存中分配一块用于存储哈希表的数据结构。
- 方法1:使用花括号
{},这是最常用和最直接的方式。 - 方法2:使用
dict()构造函数 - 方法3:使用
dict.fromkeys()方法,使用一个可迭代对象作为键,并为所有键设置一个相同的值(默认为 None)
●
{}和dict(): 这两种方式都会初始化一个空的哈希表结构。当您直接提供键值对时,Python 会对每个键进行哈希运算,并将其和对应的值存储到哈希表中的合适位置。●
dict.fromkeys(): 这种方法会遍历提供的键列表,对每个键进行哈希,并将它们与指定的值(或默认的 None)一起插入到新的哈希表中。它通常比循环插入更高效,因为它可以在内部优化哈希表的构建过程。当使用循环逐个插入元素时,每次迭代都会涉及一系列操作:查找哈希函数、计算哈希值、查找桶、处理冲突(如果存在)、然后插入键值对。这些操作会重复进行。而
dict.fromkeys()能够批量处理这些键,可能采用更有效的数据结构构建策略,减少了每次插入的单独开销。
dict.fromkeys()更高效的根本原因在于它是一个高度优化的内置方法,能够在底层批量处理键的哈希和插入过程,并减少了 Python 解释器在循环中逐个操作所带来的额外开销。因此,当你需要使用相同的值为多个键创建字典时,dict.fromkeys()是一个更高效且推荐的选择。
例子:
【1】使用花括号{}创建字典:
1
2
3
4
5
6
7
# 创建一个空字典
dict1 = {}
print(f"空字典:{dict1}", type(dict1))
# 创建有初试键值对的字典
dict2 = {"name": "张三", "age": 28, "height": 175.9}
print(f"创建有初试键值对的字典:{dict2}", type(dict2), dict2["name"])

【2】使用dict()构造函数创建字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 创建空字典
dict_none = dict()
print(f"用dict()创建空字典:{dict_none}")
# 创建一个User字典
dict_u = dict(username = "小米", password = 12345678)
print(f"用dict()创建一个字典:{dict_u}, 姓名是{dict_u['username']}, 账号密码是:{dict_u['password']}")
# 从键值对的迭代器 (如列表的元组对) 创建字典
l = [("张三", 25), ("李四", 29), ("小红", 34)]
dict_u_group = dict(l)
print(f"从键值对的迭代器 (如列表的元组对) 创建字典:{dict_u_group}")
# 从其他字典创建字典 (浅拷贝)
dict_u_copy = dict(dict_u)
print(f"浅拷贝:{dict_u_copy}")
【3】dict.fromkeys(),值相同
1
2
3
4
5
6
7
# dict.fromkeys()
dict1 = dict.fromkeys(["a", "b", "c"])
print(f"dict.fromkeys()创建字典:{dict1}") # {'a': None, 'b': None, 'c': None} 值都是None
# 指定值
dict2 = dict.fromkeys(["操作系统", "数据结构", "计算机组成原理", "计算机网络"], 150)
print(f"指定值创建:{dict2}")

(2)字典的删除
- 使用 del 语句删除整个字典: 删除后字典变量将不再存在,尝试访问会引发 NameError。
- 使用 clear() 方法清空字典: 字典本身依然存在,但内部所有键值对都被移除。
例子:
【1】使用del删除字典:
1
2
3
4
5
6
7
dict1 = {"A": 1, "B": 2}
print(f"删除前的字典:{dict1}")
del dict1
try:
print(f"删除后的字典:{dict1}")
except NameError as e:
print(f"报错:{e}")
【2】使用clear()清空字典
1
2
3
4
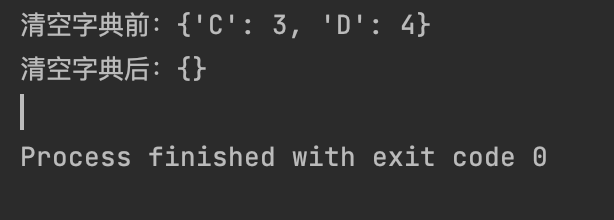
dict2 = {"C": 3, "D": 4}
print(f"清空字典前:{dict2}")
dict2.clear()
print(f"清空字典后:{dict2}")
del dict_name完全解除变量名与字典对象之间的绑定。一旦变量名被删除,如果没有任何其他引用指向该字典对象,那么 Python 的垃圾回收机制会在适当的时候回收该字典所占用的内存。
.clear()方法会遍历字典内部的哈希表,将所有的键值对移除,但字典对象本身(及其分配的底层哈希表结构)仍然存在于内存中。它只是将字典重置为空状态,而不是销毁字典对象。
4.字典的查询操作
(1)访问单个元素
- 使用方括号
[]: 通过键访问对应的值。如果键不存在,会引发 KeyError。 - 使用
get()方法: 通过键获取对应的值。如果键不存在,get() 方法会返回 None (默认值),或者您可以指定一个默认值。
例子:
1
2
3
4
5
6
7
8
9
# []访问元素
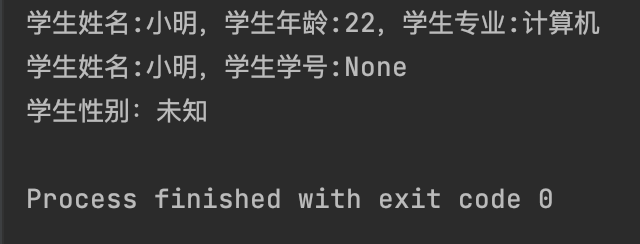
student_info = {"name": "小明", "age": 22, "major": "计算机"}
print(f"学生姓名:{student_info['name']},学生年龄:{student_info['age']},学生专业:{student_info['major']}")
# get访问元素
print(f"学生姓名:{student_info.get('name')},学生学号:{student_info.get('no')}")
# 键不存在指定值
print(f"学生性别:{student_info.get('sex', '未知')}")
当使用
[]访问字典时,Python 会计算提供键的哈希值,然后根据哈希值在底层哈希表中查找对应的位置。如果找到匹配的键,就返回其关联的值。如果哈希计算出的位置没有找到该键(无论是由于键不存在,还是由于冲突解决导致它在其他位置),就会引发 KeyError。这种操作的平均时间复杂度是 O(1),因为它直接通过哈希值定位。
get()方法的工作原理与[]类似,也是通过哈希值查找。但其不同之处在于,当键不存在时,它不会引发错误,而是返回一个默认值(默认为 None)。这在处理可能不存在的键时提供了更健壮的错误处理机制,避免了try-except块的开销,使得代码更简洁。
(2)检查键是否存在

使用 in 关键字: 检查指定的键是否存在于字典中。返回 True 或 False。
例子:
1
2
3
4
config = {'port': 8080, 'host':'localhost'}
print(f"检查端口号是否存在:{'port' in config}")
print(f"检查主机名是否存在:{'host' in config}")
print(f"检查IP地址是否存在:{'ip' in config}")

in 关键字检查键是否存在也是基于哈希表的快速查找原理。Python 会计算待查找键的哈希值,并在哈希表中尝试定位。如果找到了这个键,则返回 True;否则返回 False。这个操作的平均时间复杂度也是 O(1)。它利用了哈希表的常数时间查找特性。
(3)获取所有键、所有值、所有键值对

keys()、values() 和 items() 方法返回的都不是列表,而是字典视图对象 (Dictionary View Objects)。
- keys() 方法: 返回一个包含字典所有键的视图对象。
- values() 方法: 返回一个包含字典所有值的视图对象。
- items() 方法: 返回一个包含字典所有键值对(以元组形式 (key, value))的视图对象。
● 视图对象 (View Objects): 这些对象提供了字典元素的动态视图。这意味着它们不会复制字典中的所有键、值或键值对,而是提供一个类似迭代器的接口,允许在字典被修改时仍然能看到最新的数据。它们是惰性求值的,只有在迭代它们时,才会实际获取数据。这避免了在创建视图时就复制所有数据,从而节省了内存。
● 当对视图对象执行
list()转换时,才会实际遍历并收集所有元素到一个新的列表中。items()的结果用list转换后,list中每个元素是元组。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
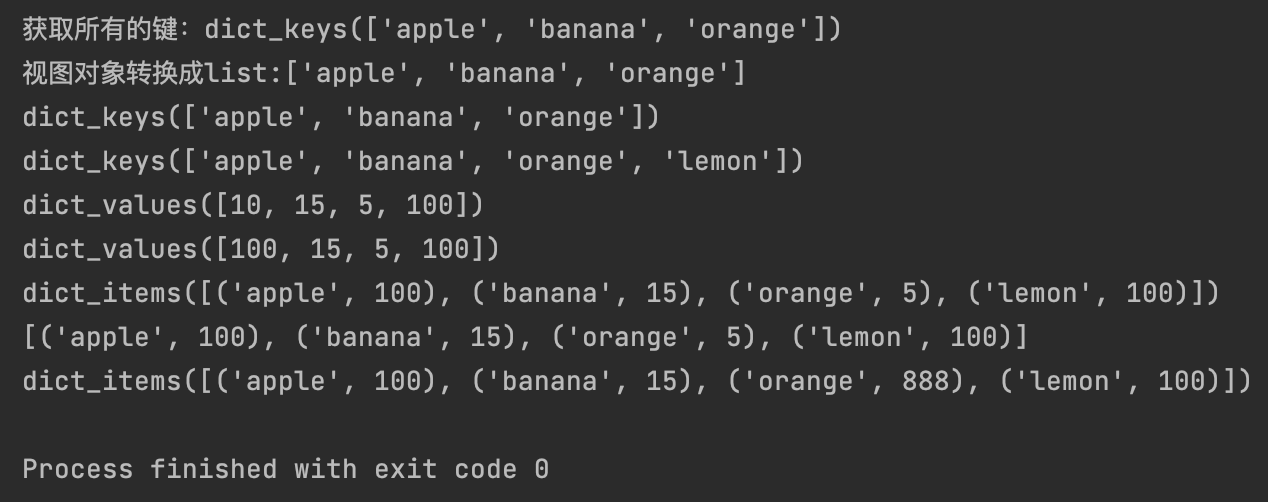
inventory = {"apple": 10, "banana": 15, "orange": 5}
print(f"获取所有的键:{inventory.keys()}") # dict_keys(['apple', 'banana', 'orange'])
print(f"视图对象转换成list:{list(inventory.keys())}") # ['apple', 'banana', 'orange']
# 视图对象是动态的,字典改变,视图也会改变
keys = inventory.keys()
print(keys)
inventory['lemon'] = 100
print(keys)
print(inventory.values())
inventory["apple"] = 100
print(inventory.values())
items = inventory.items()
print(items)
print(list(items))
inventory["orange"] = 888
print(items)
(4)遍历字典
遍历键: 最常见的遍历方式,通过 for 循环直接遍历字典对象,或使用 keys() 方法。
遍历值: 使用 values() 方法。
遍历键值对: 使用 items() 方法,这是最推荐的遍历方式。
字典的遍历操作,无论是遍历键、值还是键值对,其时间复杂度都是 O(n),其中 n 是字典中元素的数量。这是因为无论何种遍历方式,都需要访问字典中的每个存储位置至少一次,以确保所有元素都被处理。在内部,Python 会迭代哈希表中的存储槽,并根据需要提取键、值或键值对。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
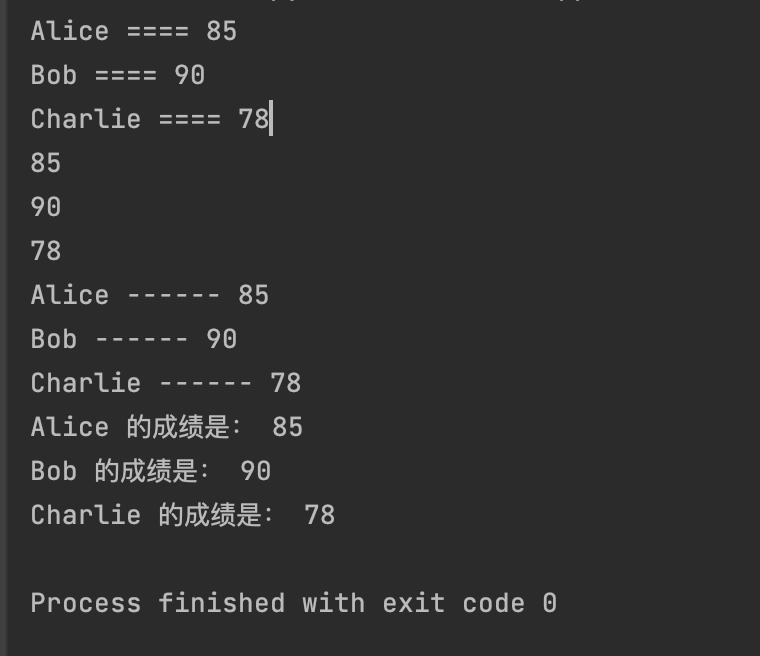
team_scores = {"Alice": 85, "Bob": 90, "Charlie": 78}
for key in team_scores.keys():
print(key, "====", team_scores[key])
for v in team_scores.values():
print(v)
for item in team_scores.items():
print(item[0], "------", item[1])
for name, score in team_scores.items():
print(name, "的成绩是:", score)
5.字典元素的增、删、改操作
(1)增加/修改元素
字典是可变的,可以通过简单的赋值操作来增加新元素或修改已有元素。
- 增加新元素:如果键不存在,则会添加新的键值对。
- 修改已有元素: 如果键已存在,则会更新该键对应的值。
- update() 方法: 使用另一个字典或键值对的迭代器来更新字典。
扩容 (Rehashing): 如果在插入新键值对后,哈希表的负载因子超过阈值(通常是 2/3),为了保持查找效率,字典会自动进行扩容(通常是大小翻倍)。扩容时,所有的现有键的哈希值都需要重新计算,并将它们重新插入到新的、更大的哈希表中。这个过程虽然是 O(n),但由于它不频繁发生,所以平均每次插入仍然是 O(1)。
update() 方法的原理是遍历提供的键值对(无论是来自另一个字典、列表元组对还是关键字参数),然后对每个键值对重复上述的“增加/修改”过程。因此,其整体效率取决于要更新的键值对数量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
student = {"name": "小李", "age": 25}
student["major"] = "网络安全"
print(f"增加新元素:{student['major']}")
student["age"] = 30
print(f"修改已有元素:{student['age']}")
# update方法
student.update({'sex': "男", 'age': 36})
print(f"update方法:{student}")
# update 使用键值对的迭代器 (例如列表的元组对) 更新
student.update([('sno', 220897788), ('height', 181)])
print(f"使用键值对的迭代器 (例如列表的元组对) 更新:{student}")
# 使用关键字参数更新
student.update(address = "上海", birth_date = '2000-09-09')
print(f"使用关键字参数更新:{student}")

(2)删除元素
使用 del 语句: 删除指定键的键值对。如果键不存在,会引发 KeyError。
pop() 方法: 删除指定键的键值对,并返回对应的值。如果键不存在,可以指定一个默认值返回,否则会引发 KeyError。
popitem() 方法: 随机删除并返回字典中的一个键值对(在 Python 3.7+ 中,它会删除并返回最后插入的键值对)。如果字典为空,会引发 KeyError。
找到并删除键值对后,哈希表中对应的槽位通常会被标记为“已删除”(或“虚拟空”),而不是直接清空。这是因为开放寻址法在查找时需要连续探测,如果直接清空,可能会中断探测路径,导致后续的查找失败。被标记为“已删除”的槽位在后续插入时可以被覆盖。
缩容: 类似于扩容,当字典中元素数量较少时,Python 字典可能会进行缩容操作以节省内存,但这种情况不如扩容频繁。
● popitem(): 这个方法通常会从哈希表的内部结构中选择一个键值对进行删除和返回。在 Python 3.7+ 中,由于字典保持插入顺序,popitem() 被优化为删除并返回“最后插入”的键值对。这两种行为都确保了 O(1) 的平均时间复杂度。
例子:
【1】del删除指定的键:
1
2
3
4
5
6
7
8
9
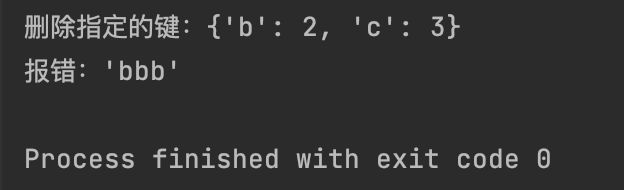
dict1 = {"a": 1, "b": 2, "c": 3}
del dict1["a"]
print(f"删除指定的键:{dict1}")
# 删除不存在的键:
try:
del dict1["bbb"]
except KeyError as e:
print(f"报错:{e}")
【2】pop()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
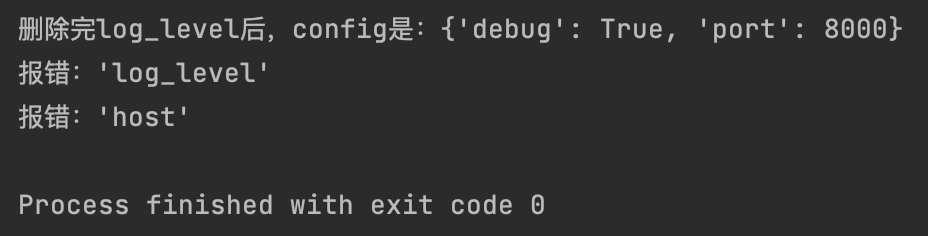
config = {"debug": True, "port": 8000, "log_level": "INFO"}
config.pop("log_level")
try:
print(f"删除完log_level后,config是:{config}")
print(f"删除log_level之后,log_level是:{config['log_level']}" )
except KeyError as e:
print(f"报错:{e}")
# 尝试pop不存在的键
try:
config.pop("host")
except KeyError as e:
print(f"报错:{e}")
【3】这个例子值得学习:popitem()
1
2
3
4
5
6
7
8
9
10
11
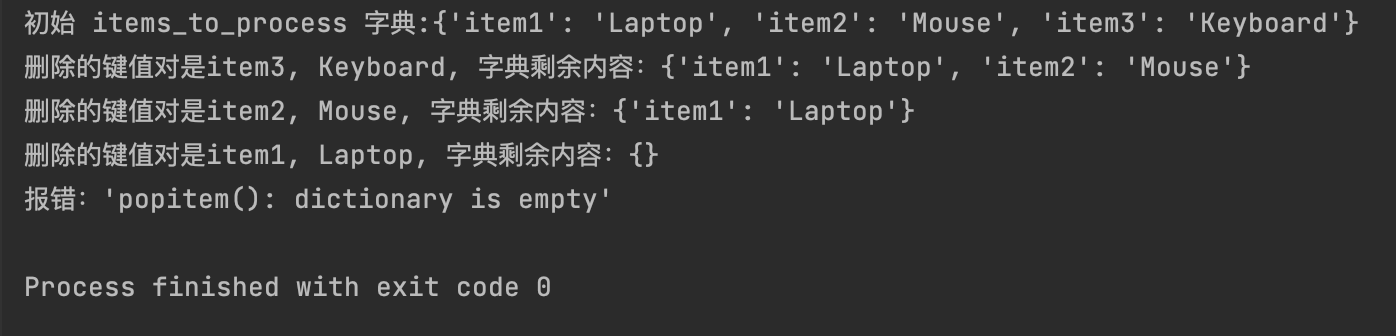
items_to_process = {"item1": "Laptop", "item2": "Mouse", "item3": "Keyboard"}
print(f"初始 items_to_process 字典:{items_to_process}")
# 循环删除所有元素直到字典为空
while items_to_process:
key, value = items_to_process.popitem()
print(f"删除的键值对是{key}, {value}, 字典剩余内容:{items_to_process}")
try:
items_to_process.popitem()
except KeyError as e :
print(f"报错:{e}")
6.字典推导式
字典推导式在内部执行与循环构建字典类似的操作,但它在 C 语言层面进行了优化,通常比手动循环加 dict[key] = value 更高效和简洁。
字典推导式提供了一种简洁的方式来创建字典。它类似于列表推导式,但用于生成字典。
基本语法:
1
{key_expression: value_expression for item in iterable if condition}
● key_expression: 定义每个键的表达式。
● value_expression: 定义每个值的表达式。
● item: 在 iterable 中迭代的元素。
● iterable: 可迭代对象,如列表、元组、字符串等。
● if condition (可选): 一个用于过滤元素的条件。
● 迭代与处理: 推导式会遍历 iterable 中的每个 item。对于每个 item,它会评估 if condition(如果存在)。
● 哈希与插入: 如果条件满足,它会计算
key_expression的哈希值,并将key_expression和value_expression的结果作为键值对插入到正在构建的新字典中。这个插入过程遵循字典的哈希表插入原理,平均时间复杂度是 O(1)。● 效率: 字典推导式的效率得益于其紧凑的语法和 CPython 内部的优化。它避免了显式的 append 或多次函数调用,从而减少了 Python 字节码的执行开销,使得构建字典的过程更加快速。
例子:
【1】从列表创建字典
1
2
3
4
5
6
7
8
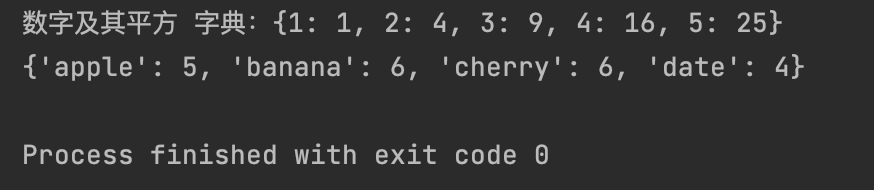
# 将列表中的数字及其平方作为键值对
numbers = [1, 2, 3, 4, 5]
squared_dict = {num: num**2 for num in numbers}
print(f"数字及其平方 字典:{squared_dict}")
# 将字符串列表转换为字典,键为单词,值为其长度
str_list = ["apple", "banana", "cherry", "date"]
fruit_dict = {f: len(f) for f in str_list}
print(fruit_dict)
【2】从两个列表创建字典 (使用 zip)
1
2
3
4
keys = ["name", "age", "city"]
values = ["李四", 28, "上海"]
dict_person = {k: v for (k, v) in zip(keys, values)}
print(dict_person)

【3】过滤和转换
1
2
3
4
5
6
7
8
# 筛选出长度大于 5 的单词,并将其转换为大写
words = ["apple", "banana", "cherry", "date", "grapefruit"]
dict_process = {k: len(k) for k in words if len(k) > 5}
print(dict_process)
# 从现有字典创建新字典,只包含分数大于或等于 60 的学生
student_scores = {"Alice": 85, "Bob": 55, "Charlie": 90, "David": 70}
student_scores_process = {name: score for name, score in student_scores.items() if score >= 60}
print(student_scores_process)
【4】反转字典的键和值,如果值不是唯一的,可能会丢失数据 (最后一个重复的值会覆盖前面的)
1
2
3
original_dict = {"a": 1, "b": 2, "c": 3}
reverse_dict = {v: k for k, v in original_dict.items()}
print(reverse_dict)