列表存储的是多个对象的引用。
注意:之前了解过,python的一个对象由三部分组成:id,type,value。其中id可以理解为是内存地址。一个标识符其实存储的是对象的id值,通过这个id值可以找到对象的值等信息。
而列表中,存储的就是各个对象的id值(存的是引用,不是值)。
为什么需要列表?
变量可以存储一个元素,而列表是一个“大容器”可以存储N多个元素,程序可以方便地对这些数据进行整体操作
列表相当于其它语言中的数组
内存示意图(简单):
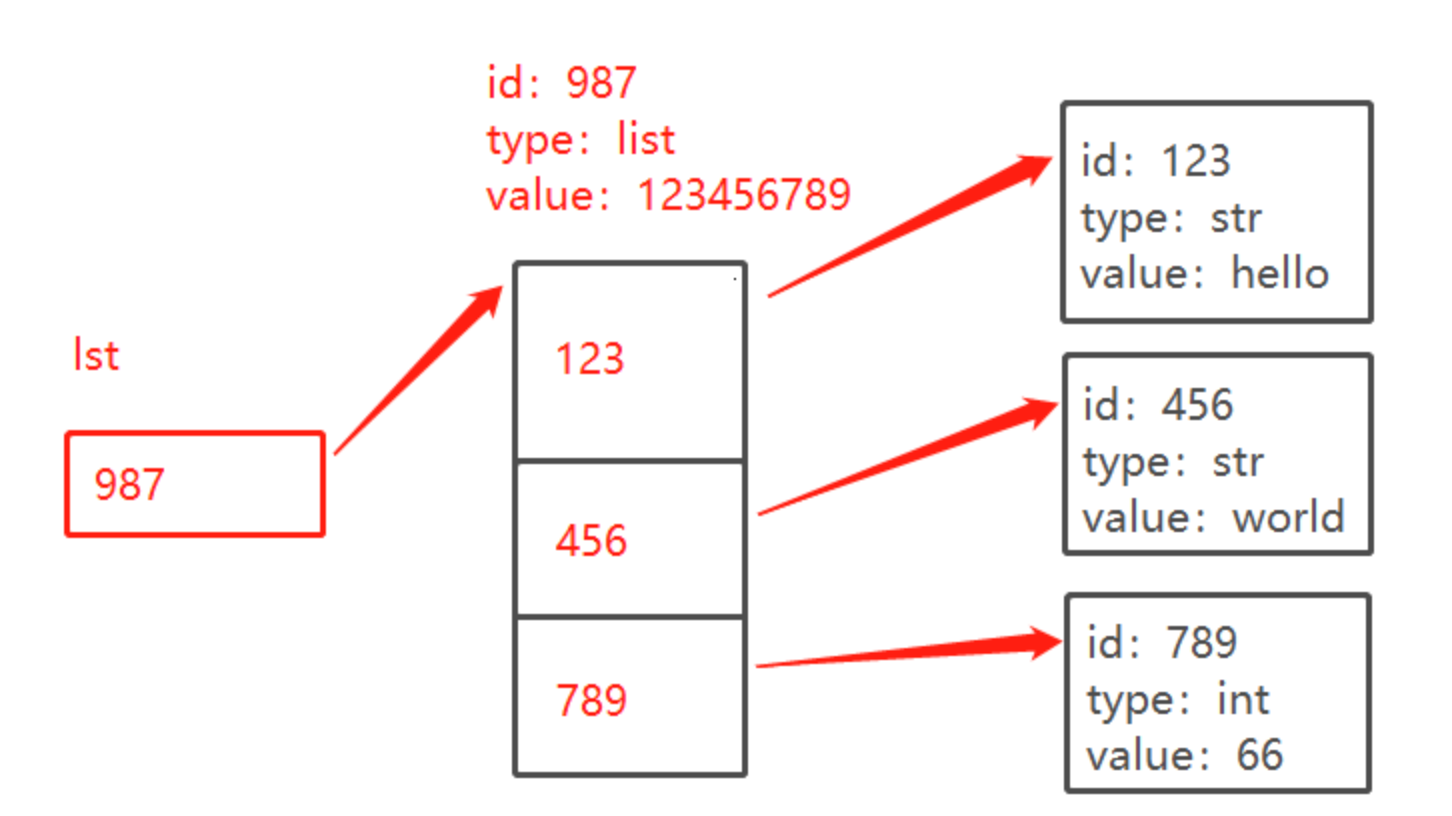
Python中的列表(List)是一种非常灵活的数据结构,它可以存储任意类型的数据(上图中,一个列表存储了2个str类型,1个int类型),并且是可变的(Mutable),这意味着列表创建后可以修改其内容。
1.列表的创建与删除
(1)创建
● 创建空列表: 可以使用一对中括号 [] 或者 list() 构造函数来创建一个空列表。
● 创建含元素的列表: 直接在中括号中放入元素,元素之间用逗号 , 分隔(英文的逗号)。列表可以包含不同数据类型的元素。
● 从其他可迭代对象创建列表: 使用 list() 构造函数可以将字符串、元组等可迭代对象转换为列表。
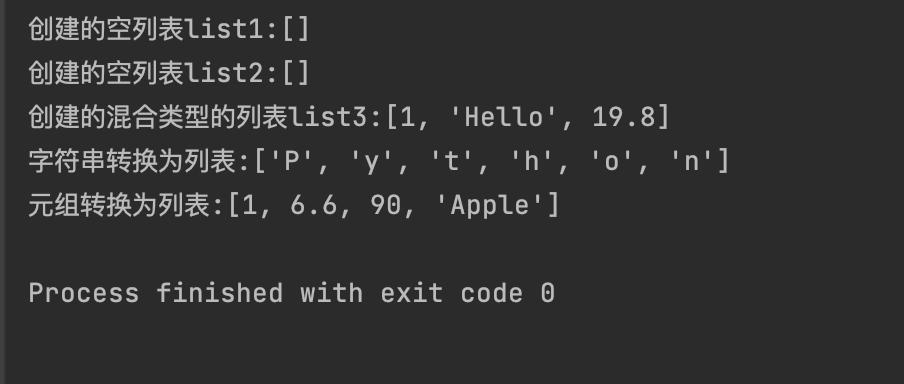
以上3种方式举例如下:
1
2
3
4
5
6
7
8
9
10
11
12
list1 = []
list2 = list()
print(f"创建的空列表list1:{list1}")
print(f"创建的空列表list2:{list2}")
list3 = [1, "Hello", 19.8]
print(f"创建的混合类型的列表list3:{list3}")
list4 = list("Python")
list5 = list((1, 6.6, 90, "Apple"))
print(f"字符串转换为列表:{list4}")
print(f"元组转换为列表:{list5}")
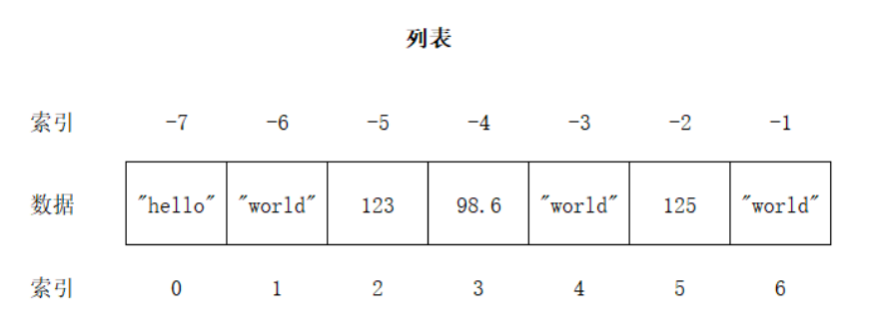
(2)列表的特点
- 列表元素按顺序有序排序
- 索引映射唯一一个数据
- 列表可以存储重复元素(这个就当对于集合来说的)
- 任意数据类型混存
- 根据需要动态分配和回收内存
这里补充一下第二个特征:索引映射唯一一个数据
注意图中的负数的索引。最后一个索引值为-1,以此类推。
(3)删除整个列表、清空列表
● 删除整个列表: 使用 del 语句可以删除列表对象本身,使其不再存在于内存中。
● 清空列表: 使用 clear() 方法可以移除列表中的所有元素,但列表对象本身仍然存在。
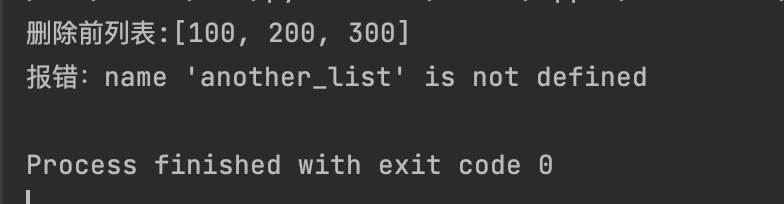
例子:删除整个列表:
1
2
3
4
5
6
7
8
another_list = [100, 200, 300]
print(f"删除前列表:{another_list}")
# 删除整个列表
del another_list
try:
print(another_list)
except NameError as e:
print(f"报错:{e}")
例子:清空列表
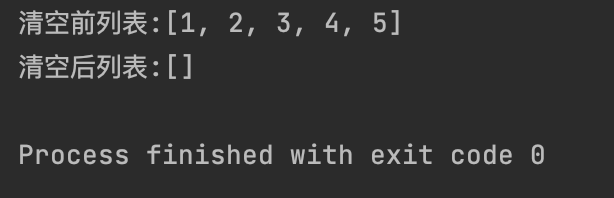
list_to_clear = [1, 2, 3, 4, 5]
print(f"清空前列表:{list_to_clear}")
list_to_clear.clear()
print(f"清空后列表:{list_to_clear}")
2.列表的查询操作
(1)获取列表中指定元素的索引
注意:● index() 和 count() 的时间复杂度: 这两个方法都需要遍历列表来查找或计数元素,因此在最坏情况下,它们的时间复杂度是 O(n),其中 n 是列表的长度。
● list.index(element, start, end) 返回指定元素在列表中第一次出现的索引。如果元素不存在,会引发 ValueError。start 和 end 是可选参数,用于指定搜索范围。
1
2
3
4
5
6
7
8
9
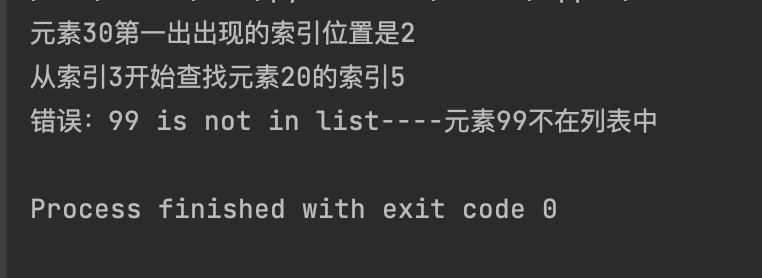
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
print(f"元素30第一出出现的索引位置是{my_numbers.index(30)}")
print(f"从索引3开始查找元素20的索引{my_numbers.index(20, 3)}")
try:
my_numbers.index(99)
except ValueError as e:
print(f"错误:{e}----元素99不在列表中")
补充一个练习题:
1
2
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
print(f"查找最后一个 20 的索引:{my_numbers.index(20, -1)}") # 输出:7
(2)获取列表中的单个元素

● 索引访问: 列表中的每个元素都有一个对应的索引,从 0 开始。可以使用 list[index] 来访问特定位置的元素。
正向索引: 0 代表第一个元素,1 代表第二个,以此类推。
负向索引: -1 代表最后一个元素,-2 代表倒数第二个,以此类推。
1
2
3
4
5
6
7
8
9
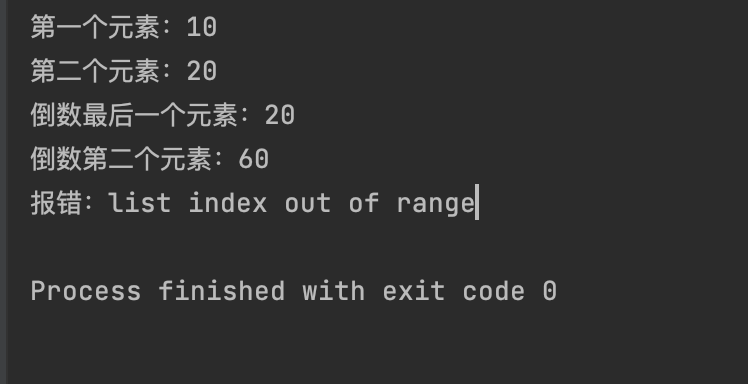
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
print(f"第一个元素:{my_numbers[0]}")
print(f"第二个元素:{my_numbers[1]}")
print(f"倒数最后一个元素:{my_numbers[-1]}")
print(f"倒数第二个元素:{my_numbers[-2]}")
try:
my_numbers[10]
except IndexError as e:
print(f"报错:{e}") # 输出:报错:list index out of range
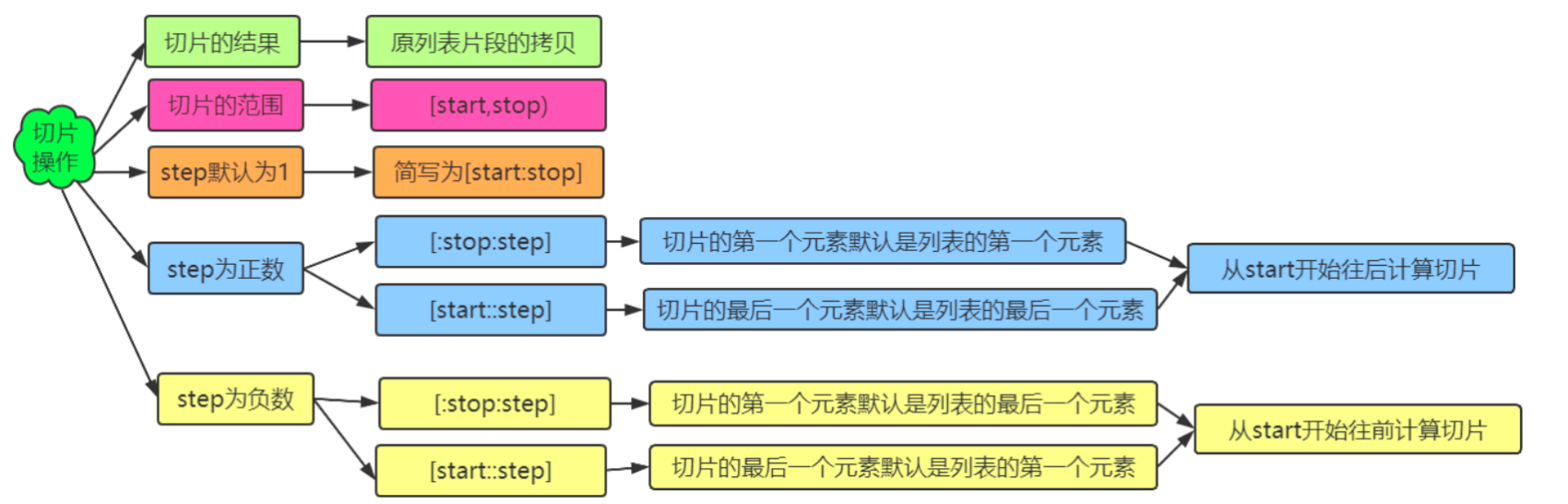
(3)切片:获取列表中的多个元素
特别记住:● 切片操作不会修改原列表,而是创建一个新的列表对象,其中包含切片出来的元素。这是一个浅拷贝。
● 切片(Slicing): 使用 list[start:end:step] 可以获取列表的一个子序列。
start:起始索引(包含),默认为 0。
end:结束索引(不包含),默认为列表的末尾。
step:步长(每隔多少个元素取一个),默认为 1。也可以是负数。
1
2
3
4
5
6
7
8
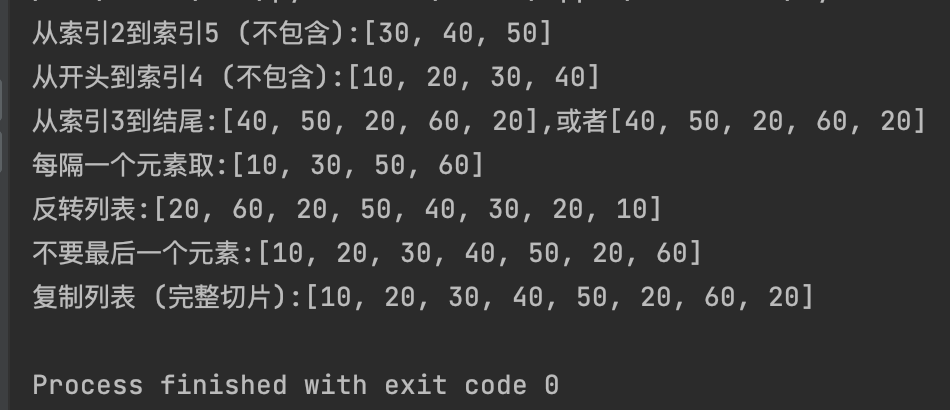
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
print(f"从索引2到索引5 (不包含):{my_numbers[2:5]}")
print(f"从开头到索引4 (不包含):{my_numbers[:4]}")
print(f"从索引3到结尾:{my_numbers[3::]},或者{my_numbers[3:]}")
print(f"每隔一个元素取:{my_numbers[::2]}") #注意:这里一定是2个冒号
print(f"反转列表:{my_numbers[::-1]}") #注意:这里一定是2个冒号
print(f"不要最后一个元素:{my_numbers[:-1]}")
print(f"复制列表 (完整切片):{my_numbers[::]}")
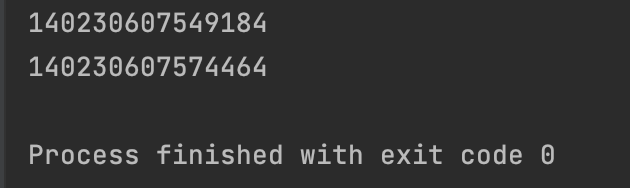
注意:切片虽然是拷贝,但是一个新的对象:
id值不同,所以说切片是新的对象!!
(4)判断指定元素在列表中是否存在
注:● Python 对 in 运算符的实现经过优化,对于列表,它会进行线性搜索,逐个比较元素。

● 成员检查: 使用 in 和 not in 运算符可以检查某个元素是否存在于列表中。
下面的例子输出都是True:
1
2
3
4
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
print(f"30 是否在列表中?{30 in my_numbers}")
print(f"20 是否在列表中?{20 in my_numbers}")
print(f"99 是否不在列表中?{99 not in my_numbers}")
(5)列表元素的遍历

1
2
3
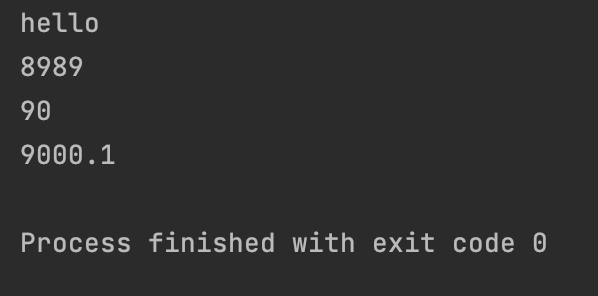
list1 = ["hello", "8989", 90, 9000.1]
for item in list1:
print(item)
(6)指定元素在列表中出现的次数
注:● index() 和 count() 的时间复杂度: 这两个方法都需要遍历列表来查找或计数元素,因此在最坏情况下,它们的时间复杂度是 O(n),其中 n 是列表的长度。
● count() 方法: list.count(element) 返回指定元素在列表中出现的次数。
1
2
3
4
5
my_numbers = [10, 20, 30, 40, 50, 20, 60, 20]
# 没有出现过的元素,count就是0
print(f"元素20在列表中出现的次数:{my_numbers.count(20)}") # 3
print(f"元素100在列表中出现的次数:{my_numbers.count(100)}") # 0
3.列表元素的增、删、改操作
● Python 列表是可变的序列类型。这意味着所有增、删、改操作都会直接在原列表对象上进行修改,而不会创建新的列表对象(除非进行切片赋值替换)。这被称为原地操作(In-place Operation)。
(1)列表元素的增加操作
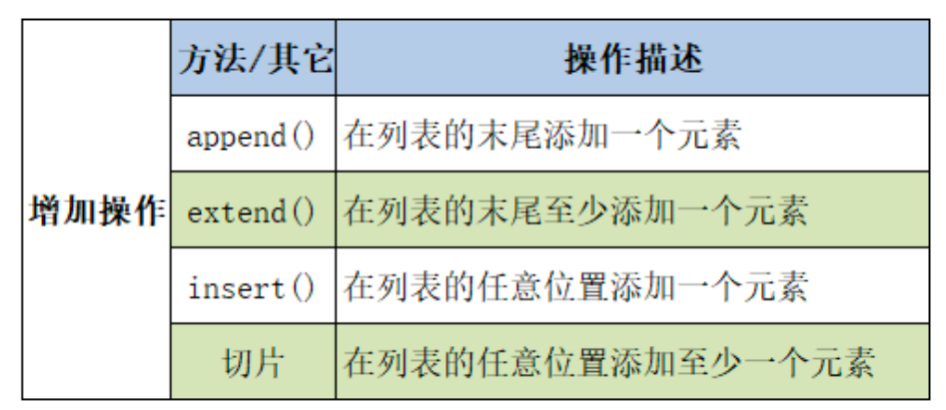
append(element):在列表末尾添加一个元素。
insert(index, element):在指定索引位置插入一个元素,原位置及之后的元素后移。
extend(iterable):将一个可迭代对象(如另一个列表)中的所有元素添加到列表末尾。
注意:append() 将整个参数作为一个元素添加到列表末尾,均摊时间复杂度为 O(1),而 extend() 会迭代其参数,并将参数中的每个元素添加到列表末尾。
insert(index, element): 在指定索引位置插入元素。由于底层是动态数组,要在中间或开头插入元素,需要将从插入点开始的所有后续元素向后移动一位,为新元素腾出空间。因此,这个操作的时间复杂度是 O(n),其中 n 是列表的长度。在列表越长、插入位置越靠前时,性能开销越大。
extend(iterable): 将可迭代对象中的所有元素添加到列表末尾。其时间复杂度取决于可迭代对象的长度 k,为 O(k)(均摊)。与 append() 类似,也可能触发扩容。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
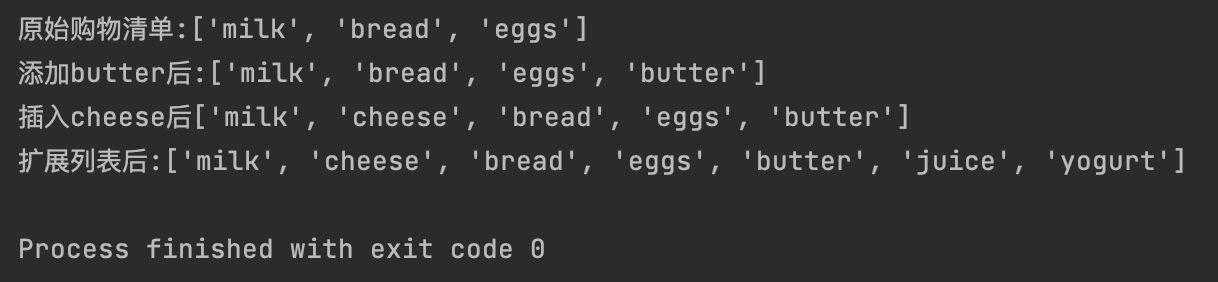
my_shopping_list = ["milk", "bread", "eggs"]
print(f"原始购物清单:{my_shopping_list}")
my_shopping_list.append('butter')
print(f"添加butter后:{my_shopping_list}")
my_shopping_list.insert(1,"cheese") #索引1位置插入
print(f"插入cheese后{my_shopping_list}")
additional_items = ["juice", "yogurt"]
# extend
my_shopping_list.extend(additional_items)
print(f"扩展列表后:{my_shopping_list}")
(2)列表元素的删除操作
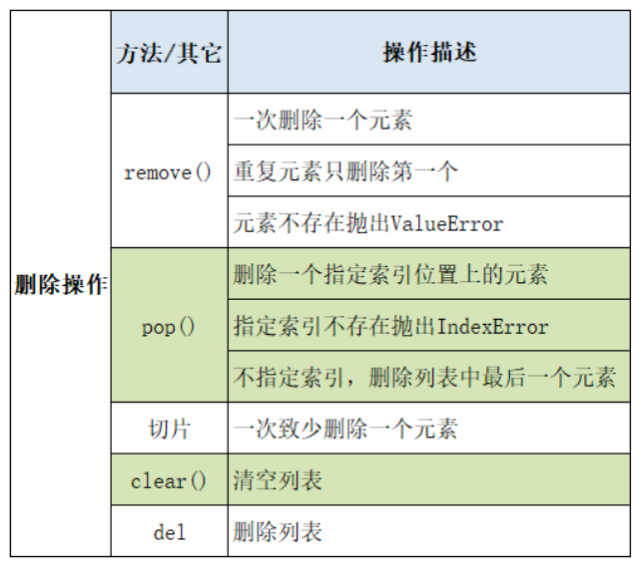
remove(element):删除列表中第一个匹配到的指定元素。如果元素不存在,会引发 ValueError。
pop(index):删除并返回指定索引位置的元素。如果未指定索引,则删除并返回最后一个元素。
del list[index]:通过索引删除指定位置的元素。
del list[start:end]:通过切片删除指定范围的元素。
注意:
- remove() 按值删除。此操作首先需要找到元素(线性扫描,O(n)),然后删除它。删除元素后,该位置之后的所有元素都需要向前移动,以填补空缺,这又是 O(n) 操作。因此,remove() 的时间复杂度是 O(n)。
- pop() 按索引删除并返回被删除的元素,常用于栈(Stack)和队列(Queue)操作。
- 当 index 未指定时(删除最后一个元素),时间复杂度为 O(1),因为不需要移动其他元素。
- 当 index 指定时(删除中间或开头的元素),与 insert() 类似,需要将后续元素向前移动。其时间复杂度是 O(n)。
- del 语句按索引或切片删除,不返回元素。
del list[index]与 pop(index) 类似,也需要移动后续元素,因此时间复杂度是 O(n)。
del list[start:end]需要移动 end 之后的元素来填补 end - start 个空缺。如果删除了 k 个元素,时间复杂度是 O(n)。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
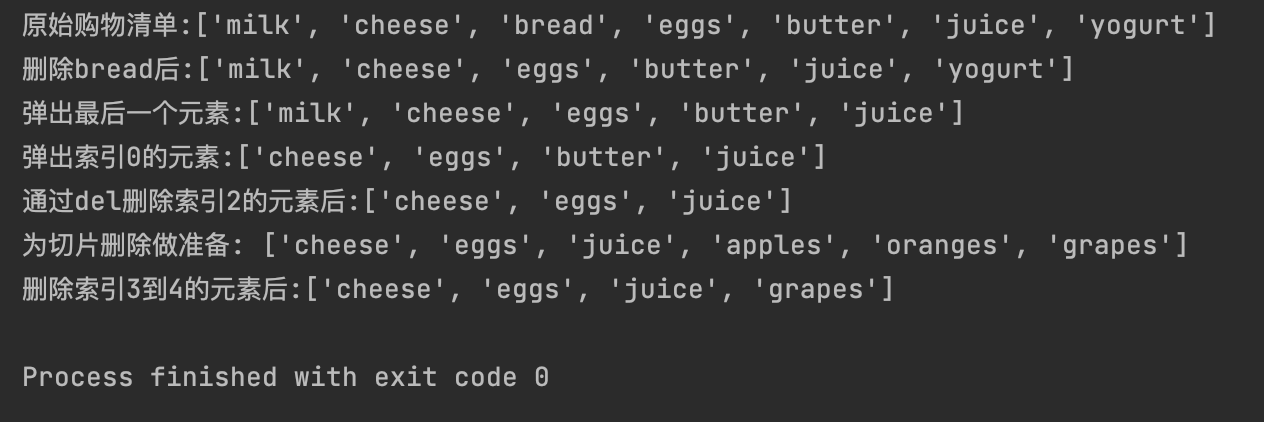
# ['milk', 'cheese', 'bread', 'eggs', 'butter', 'juice', 'yogurt']
print(f"原始购物清单:{my_shopping_list}")
# 删除bread
my_shopping_list.remove("bread")
print(f"删除bread后:{my_shopping_list}")
# 弹出最后一个元素
my_shopping_list.pop()
print(f"弹出最后一个元素:{my_shopping_list}")
# 弹出索引0的元素
my_shopping_list.pop(0)
print(f"弹出索引0的元素:{my_shopping_list}")
# 通过del删除索引2的元素
del my_shopping_list[2]
print(f"通过del删除索引2的元素后:{my_shopping_list}")
my_shopping_list.extend(["apples", "oranges", "grapes"])
print(f"为切片删除做准备: {my_shopping_list}")
# 删除索引3到4的元素
del my_shopping_list[3:5]
print(f"删除索引3到4的元素后:{my_shopping_list}")
(3)列表元素的修改操作
list[index] = new_value:通过索引直接赋值来修改单个元素。
list[start:end] = new_iterable:通过切片赋值来修改一个范围的元素。新的可迭代对象的元素数量可以与被替换的范围不同。
注意:切片赋值
list[start:end] = new_iterable会删除 start 到 end (不包含)之间的元素,然后将new_iterable中的元素插入到该位置。new_iterable的长度可以与被替换的长度不同。
list[index] = new_value:由于索引访问是 O(1),这个操作的时间复杂度也是 O(1)。list[start:end] = new_iterable:这个操作首先删除 start:end 范围内的元素,然后将 new_iterable 中的元素插入到该位置。
- 如果被替换的元素数量与新插入的元素数量相同,这个操作可能很快,但也可能涉及元素的移动。
- 如果新旧元素数量不同,列表需要调整大小,后续元素需要移动。这个操作的时间复杂度通常是 O(n+k),其中 k 是新插入元素的数量,并且可能涉及到底层数组的扩容或缩容。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
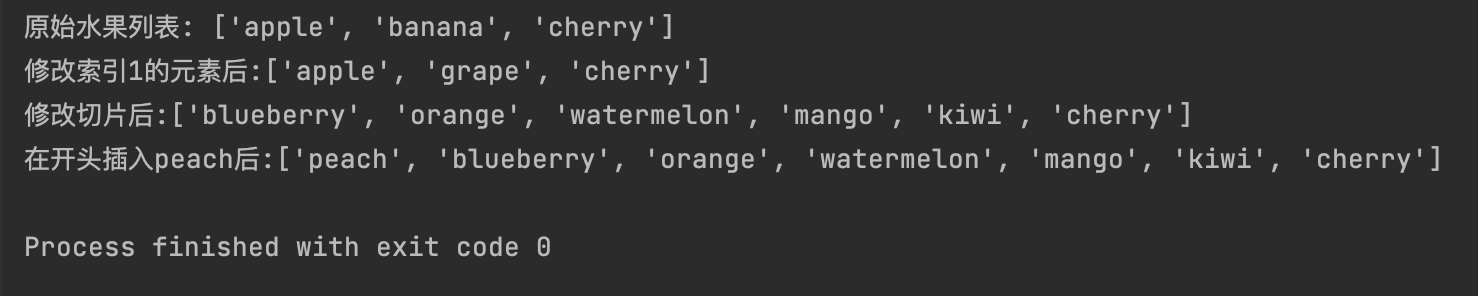
my_fruits = ["apple", "banana", "cherry"]
print(f"原始水果列表: {my_fruits}")
#修改索引1的元素后
my_fruits[1] = "grape"
print(f"修改索引1的元素后:{my_fruits}")
#修改切片后, 注意左闭右开 包含0不包含2
my_fruits[0:2] = ["blueberry", "orange", "watermelon", "mango", "kiwi"]
print(f"修改切片后:{my_fruits}")
# 在开头插入元素
my_fruits[0:0] = ["peach"] # 注意这里"peach"要加[],不然会变成['p', 'e', 'a', 'c', 'h', 'blueberry', 'o...]
print(f"在开头插入peach后:{my_fruits}")
4.列表元素的排序
常见的两种方式:
- 调用
sort()方法,列有中的所有元素默认按照从小到大的顺序进行排序,可以 指定reverse=True,进行降序 排序 - 调用内置函数
sorted(),可以指定reverse=True,进行降序排序,原列表不发生改变
● list.sort() vs sorted() 的选择:
list.sort(): 原地修改列表。优点是内存效率高,不需要创建新列表。缺点是会改变原始列表。适用于不需要保留原始列表顺序的场景。
sorted(): 返回一个新的排序列表,不改变原始可迭代对象。优点是保留了原始数据的完整性。缺点是需要额外的内存空间来存储新列表。适用于需要保留原始列表的场景或对不可变序列(如元组)进行排序。
● list.sort() 方法: 这是列表对象的一个方法,它会原地修改列表,不返回任何值(返回 None)。
● sorted() 内置函数: 这是一个内置函数,它接受一个可迭代对象作为参数,并返回一个新的已排序的列表,而不改变原始的可迭代对象。
两者都接受以下可选参数:
● reverse=True:按降序排序(默认为 False,升序)。
● key=function:指定一个函数,该函数将对列表中的每个元素调用一次,并使用其返回值进行比较排序。例如,key=len 可以按字符串长度排序。
注:
- Python 的 sort() 和 sorted() 函数使用的都是一种名为 Timsort 的混合排序算法。Timsort 结合了归并排序(Merge Sort)和插入排序(Insertion Sort)的优点,在实际数据中表现优秀,对于部分有序的数据尤其高效。Timsort 是一种稳定排序算法。
- key 参数提供了一个函数,用于在比较元素之前对其进行转换。排序算法实际上是比较 key(element) 的返回值,而不是元素本身。例如,key=str.lower 会在比较字符串时先将它们转换为小写,从而实现不区分大小写的排序。lambda 函数在这里非常常用,因为它提供了一种简洁的方式来创建匿名函数作为 key。
list.sort()是原地操作,因此内存开销较小。sorted()函数会创建一个新的列表来存储排序结果,因此需要额外的内存空间。插入排序在小规模数组和部分有序数组上表现出色。
归并排序在处理大规模数据时具有稳定的 O(nlogn) 时间复杂度。
Timsort 的核心思想是:它首先将列表分解成较小的“运行(runs)”(这些运行通常是自然有序的或反序的子序列),然后使用插入排序对这些小运行进行排序(或反转反序运行),最后使用归并排序将这些已排序的运行合并起来。
Timsort 的平均和最坏时间复杂度都是 O(nlogn),其中 n 是列表中的元素数量。这是比较排序算法(Comparison Sorts)的理论最优复杂度。
Timsort 的空间复杂度在最坏情况下是 O(n)(因为归并排序需要额外的临时空间),但在最好情况下(例如列表已经排序)可以达到 O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
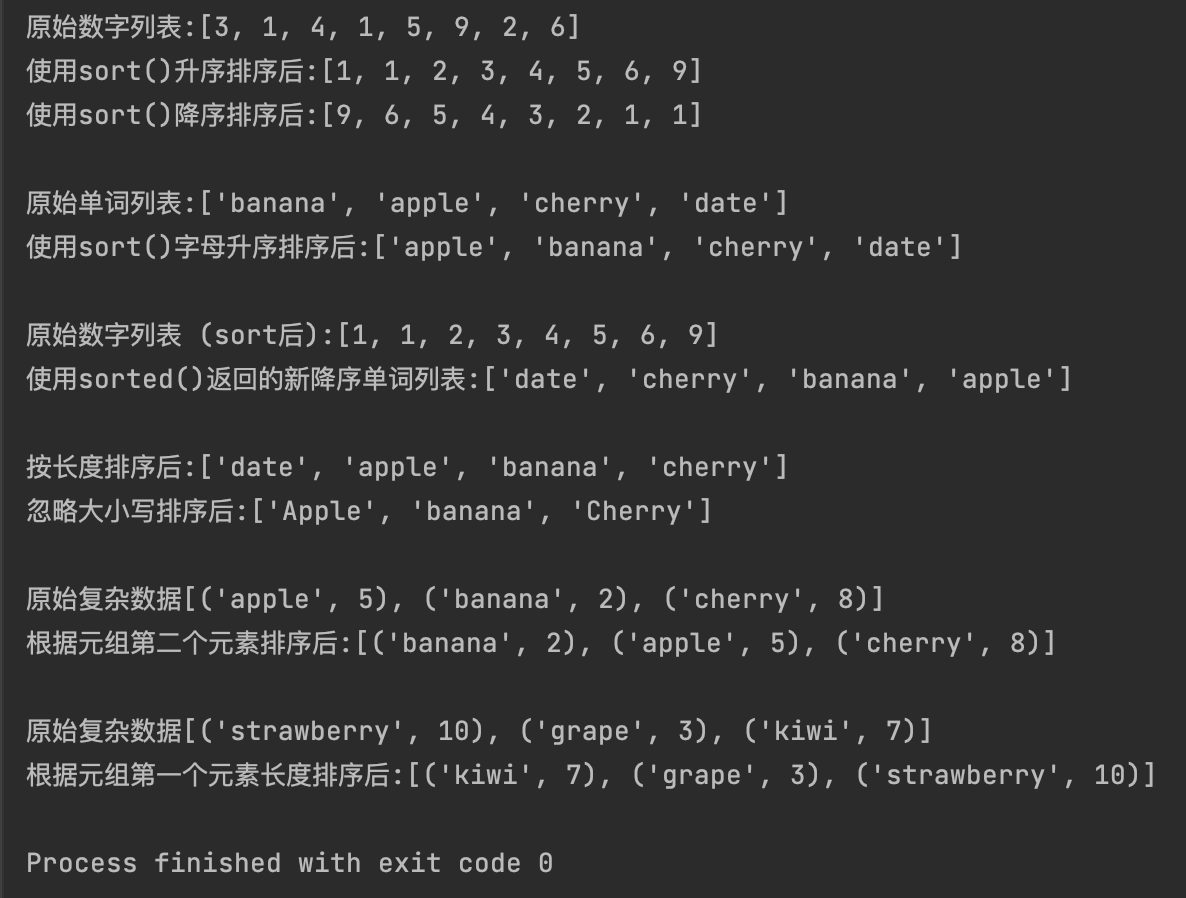
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
words = ["banana", "apple", "cherry", "date"]
mixed_case_words = ["Apple", "banana", "Cherry"]
complex_data = [("apple", 5), ("banana", 2), ("cherry", 8)]
# 原始数字列表:
print(f"原始数字列表:{numbers}")
# 升序排序
numbers.sort()
print(f"使用sort()升序排序后:{numbers}")
# 降序排序
numbers.sort(reverse=True)
print(f"使用sort()降序排序后:{numbers}")
# 原始单词列表:
print(f"\n原始单词列表:{words}")
# 字母顺序排序
words.sort()
print(f"使用sort()字母升序排序后:{words}")
# sorted
sorted_numbers = sorted(numbers)
print(f"\n原始数字列表 (sort后):{sorted_numbers}")
sorted_words = sorted(words, reverse=True)
print(f"使用sorted()返回的新降序单词列表:{sorted_words}")
# 使用key参数
sorted_words_len = sorted(words, key = len)
print(f"\n按长度排序后:{sorted_words_len}")
sorted_words_miss_case = sorted(mixed_case_words, key=str.lower)
print(f"忽略大小写排序后:{sorted_words_miss_case}")
# 对复杂数据类型排序 (例如,根据元组的第二个元素排序)
print(f"\n原始复杂数据{complex_data}")
# 使用lambda函数作为key
complex_data.sort(key=lambda x:x[1])
print(f"根据元组第二个元素排序后:{complex_data}")
complex_data_2 = [("strawberry", 10), ("grape", 3), ("kiwi", 7)]
print(f"\n原始复杂数据{complex_data_2}")
complex_data_2.sort(key=lambda x:len(x[0]))
print(f"根据元组第一个元素长度排序后:{complex_data_2}")
5.列表推导式(List Comprehensions)
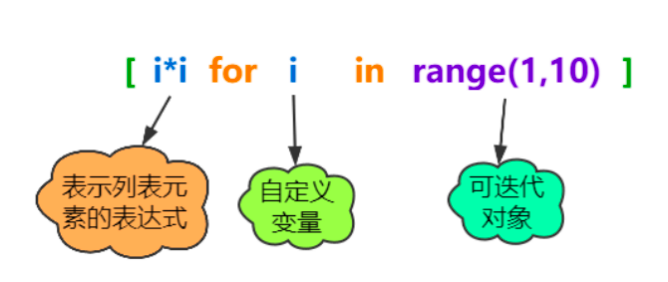
列表推导式(List Comprehensions)提供了一种简洁的语法,用于从现有列表或其他可迭代对象创建新列表。它通常比传统的 for 循环和 append() 方法更具可读性和效率。注意事项:“表示列表元素的表达式”中通常包含自定义变量
基本语法结构:
[expression for item in iterable if condition]
- expression:对 item 进行操作的表达式,其结果将成为新列表的一个元素。
- item:从 iterable 中取出的每个元素。
- iterable:一个可迭代对象(如列表、元组、字符串、range等)。
- if condition (可选):一个条件语句,只有当条件为 True 时,item 才会参与 expression 的计算并被包含在新列表中。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
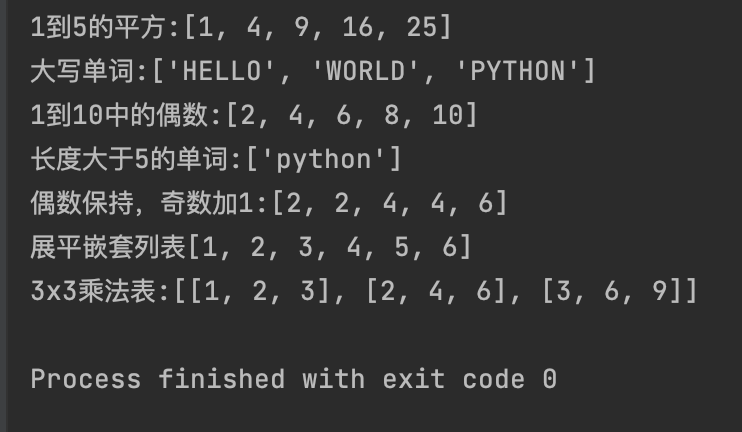
# 创建一个包含 1 到 5 的平方的列表
squares = [x * x for x in range(1, 6)]
print(f"1到5的平方:{squares}")
# 将所有字符串转换为大写
words = ["hello", "world", "python"]
upperCase = [word.upper() for word in words]
print(f"大写单词:{upperCase}")
# 从 1 到 10 中筛选出偶数
even_num = [num for num in range(1, 11) if num % 2 == 0]
print(f"1到10中的偶数:{even_num}")
#筛选出长度大于 5 的单词
word_longer_5 = [word for word in words if len(word) > 5]
print(f"长度大于5的单词:{word_longer_5}")
# 带有if-else的列表推导式
# 如果是偶数,保持原样;如果是奇数,将其加 1
num_process = [i if i % 2 == 0 else i + 1 for i in range(1, 6)]
print(f"偶数保持,奇数加1:{num_process}")
# 嵌套列表推导式
# 展平一个嵌套列表
nested_list = [[1, 2, 3], [4, 5], [6]]
flattened_list = [num for sublist in nested_list for num in sublist]
print(f"展平嵌套列表{flattened_list}")
# 生成一个乘法表 (例如 3x3)
multiplication_table = [[i * j for j in range(1, 4)] for i in range(1, 4)]
print(f"3x3乘法表:{multiplication_table}")
总结:列表推导式是用一行代码创建列表的强大工具,通常比等效的 for 循环更加紧凑和易读。
在许多情况下,列表推导式的执行效率比传统的 for 循环和 append() 组合更高。这是因为列表推导式在底层C语言级别进行了优化,避免了每次 append 时可能发生的函数调用开销和列表内存重新分配。
- 列表推导式体现了一种声明式(Declarative)编程的风格,你声明了你想要什么结果,而不是一步一步地告诉程序如何得到结果。(传统的 for 循环则是命令式编程(Imperative Programming)的典型代表。)
- 对于简单的转换和过滤操作,列表推导式的可读性通常优于传统的循环。然而,对于非常复杂的逻辑,有时传统的 for 循环可能会更清晰。
- 虽然列表推导式会立即创建并填充整个列表,但 Python 中还有生成器表达式(Generator Expressions),它们看起来与列表推导式非常相似,但使用圆括号 () 而不是方括号 [],它们会惰性地生成值,从而节省内存,尤其适用于处理非常大的数据集。