1.二进制与字符编码
很久很久以前,在计算机刚刚诞生的时代,不懂人类的语言,甚至不懂数字,它们只认识一种语言——二进制(0和1)。就像电灯的开(1)和关(0)一样,所有的信息在计算机看来都只是一串串的0和1。
那么问题来了,我们人类要怎么和这些只懂0和1的机器交流呢?比如,我想让计算机显示一个英文字母“A”。
于是,一个伟大的“翻译官”诞生了,它就是 ASCII(美国信息交换标准代码)。ASCII 就像是计算机世界的“小学英语课本”。它规定:某个特定的0和1的组合就代表字母“A”,另一个组合代表“B”,再一个组合代表数字“1”,等等。这样,当计算机收到一串0和1时,它就能对照着ASCII表,把它们“翻译”成我们能看懂的英文字母、数字和一些常用符号。从那以后,计算机终于能够“认识”简单的英文了,这在当时是一个巨大的进步!
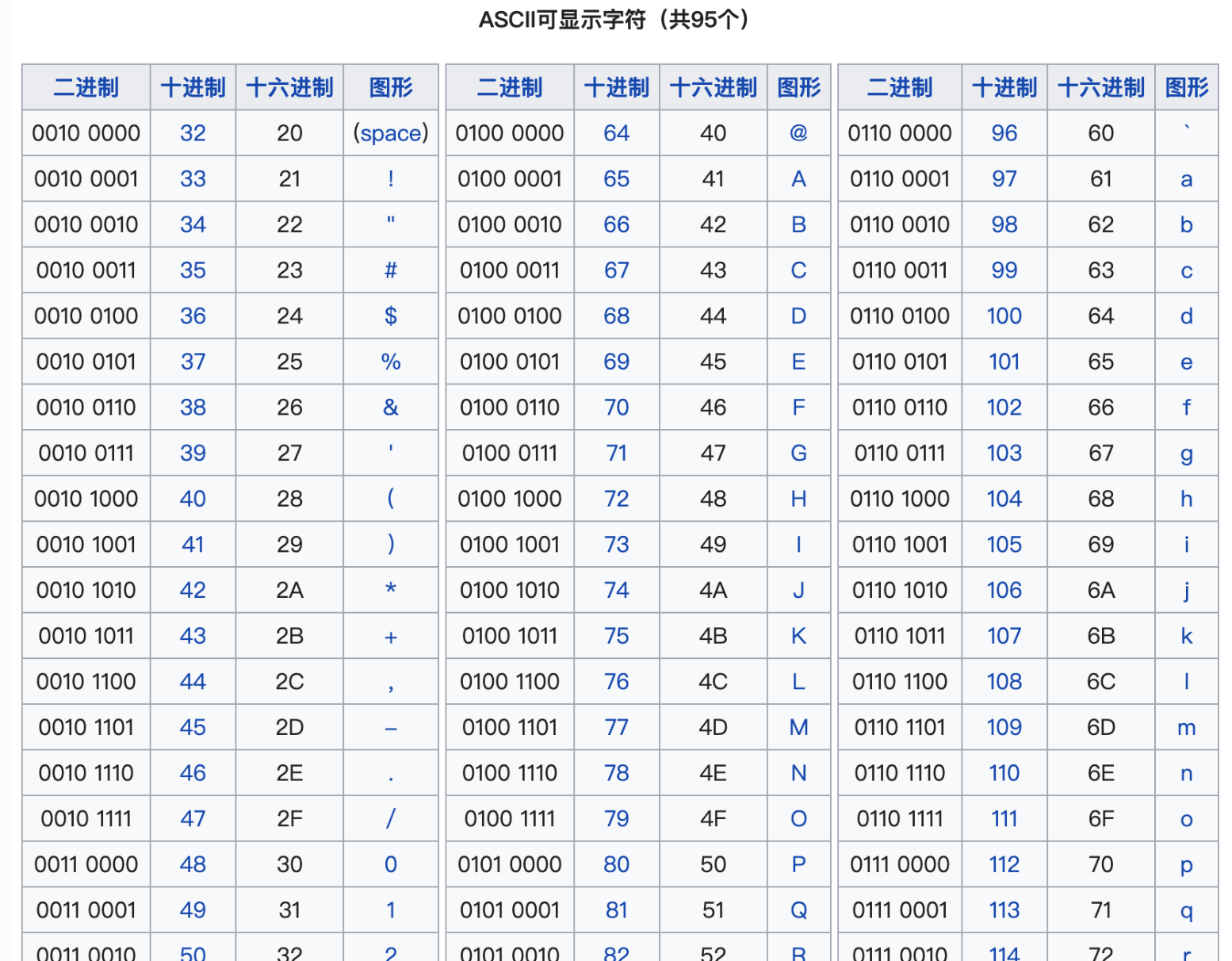
但是,世界是多元的,不仅仅只有英文。随着计算机技术的发展,它走出了美国,走向了世界各地。当计算机来到中国时,问题又来了。ASCII只能表示256个字符(1个字节,即8bits表示),根本不够我们成千上万的汉字使用。
为了解决汉字问题:
- 最早出现的是 GB2312。它就像是专门为汉字设计的“初级词典”,收录了大约7000多个常用汉字,让计算机能够显示和处理大部分简体中文。
- 随着汉字使用的进一步扩展,GB2312 渐渐不够用了。于是,GBK出现了。GBK 在 GB2312 的基础上进行了扩展,收录了更多的汉字和一些繁体字,让计算机对汉字的处理能力更上一层楼。
- 再后来,当计算机需要处理所有能找到的汉字,包括一些非常生僻的字,甚至少数民族文字时,更庞大的 GB18030 应运而生。它几乎囊括了所有汉字和许多其他字符,成为了中国国家标准,确保了任何汉字都能被计算机正确地“识别”和“显示”。
与此同时,世界上的其他国家也遇到了和中国类似的问题。日本有自己的JIS编码,韩国有自己的KSC编码,欧洲各国也有自己的编码……这导致了一个新的混乱:不同国家生产的计算机,使用的“翻译官”不同,计算机之间交流起来就非常困难,一个国家的文字在另一个国家的电脑上可能会变成乱码。
为了解决这个“巴别塔”般的难题,一个宏伟的计划启动了,那就是创造一个能“包罗万象”的翻译官—— Unicode(统一码)。Unicode 的目标是把全世界所有的字符(包括各种语言的文字、符号、甚至表情符号)都收录进去,并给每个字符一个独一无二的“身份证号码”。它就像是计算机世界的“联合国语言”,只要大家遵守Unicode的规定,无论你是哪个国家的计算机,都能正确地显示和处理彼此的文字。图中的“Unicode几乎包含了全世界的字符”正是这个意思。
Unicode 解决了字符的“身份证号码”问题,但还有一个实际问题:如何将这些“身份证号码”高效地存储和传输呢?因为Unicode收录的字符太多,有些字符的“身份证号码”会很长。如果都用同样的长度来存储,会非常浪费空间。
于是, UTF-8 闪亮登场了!UTF-8 是一种变长的编码方式,它是 Unicode 的一种实现方式。它就像一个“聪明的数据压缩员”:对于常用的、身份证号码短的字符(比如英文字母),它用很少的二进制位来表示;对于不常用的、身份证号码长的字符(比如汉字),它才用较多的二进制位来表示。这样既保证了能表示所有Unicode字符,又节省了存储空间和网络传输的带宽。如今,UTF-8 已经成为了互联网上最主流的字符编码方式,因为它既通用又高效。
所以,当你在电脑上看到这些文字,或者在手机上输入表情符号时,正是因为有了这一系列“翻译官”和“编码方式”的辛勤工作,计算机才能够从它最原始的0和1的语言,一步步“认识”并显示出我们人类丰富多彩的文字世界。而这一切的起点,都源于计算机那最基本的、只认识0和1的二进制语言。
说了这么多,通过代码简单理解下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 验证中文编码的简化示例
# 只用“你好”两个字进行演示
chinese_string = "你好"
print(f"--- 原始字符串 ---")
print(f"原始字符串 (Unicode): {chinese_string}")
print(f"字符串类型: {type(chinese_string)}") # Python 3 字符串默认为 Unicode
print(f"字符数量: {len(chinese_string)}")
print("-" * 30)
# --- 1. UTF-8 编码 ---
# UTF-8 是Unicode的一种变长编码方式,汉字通常占用3个字节
try:
utf8_bytes = chinese_string.encode("utf-8")
print(f"--- UTF-8 编码 ---")
print(f"编码后的字节序列: {utf8_bytes}")
print(f"字节长度: {len(utf8_bytes)} 字节 (每个汉字约3字节)") # 你好 -> 2 * 3 = 6 字节
print(f"解码回字符串: {utf8_bytes.decode('utf-8')}")
except UnicodeEncodeError as e:
print(f"UTF-8 编码失败: {e}")
print("-" * 30)
# --- 2. GBK 编码 ---
# GBK 是中国国家标准编码,汉字通常占用2个字节
try:
gbk_bytes = chinese_string.encode("gbk")
print(f"--- GBK 编码 ---")
print(f"编码后的字节序列: {gbk_bytes}")
print(f"字节长度: {len(gbk_bytes)} 字节 (每个汉字约2字节)") # 你好 -> 2 * 2 = 4 字节
print(f"解码回字符串: {gbk_bytes.decode('gbk')}")
except UnicodeEncodeError as e:
print(f"GBK 编码失败: {e}")
print("-" * 30)
# --- 3. ASCII 编码(尝试编码中文,会报错) ---
# ASCII 只能编码英文字符和少数符号,不支持中文
print(f"--- ASCII 编码(预期失败) ---")
try:
ascii_bytes = chinese_string.encode("ascii")
print(f"编码后的字节序列: {ascii_bytes}") # 如果这里没有报错,说明可能设置了replace等错误处理
except UnicodeEncodeError as e:
print(f"ASCII 编码失败: {e} (因为中文无法用ASCII表示)")
print("-" * 30)
# --- 4. Unicode 码点 ---
# 每个字符在Unicode字符集中都有一个唯一的数字ID(码点)
print(f"--- Unicode 码点 ---")
print(f"字符 '你' 的 Unicode 码点 (十进制): {ord('你')}")
print(f"字符 '好' 的 Unicode 码点 (十进制): {ord('好')}")
print("-" * 30)
# --- 5. 错误解码示例(产生乱码) ---
# 如果用错误的编码方式解码,就会出现乱码
print(f"--- 错误解码(乱码演示) ---")
utf8_encoded_bytes = "你好".encode("utf-8") # 先用UTF-8编码得到字节序列
print(f"UTF-8 编码的字节序列: {utf8_encoded_bytes}")
try:
# 尝试用GBK去解码UTF-8的字节,会导致乱码
wrongly_decoded_string = utf8_encoded_bytes.decode("gbk")
print(f"尝试用 GBK 解码: {wrongly_decoded_string}")
except UnicodeDecodeError as e:
print(f"GBK 解码 UTF-8 字节失败: {e} (通常会产生乱码或直接报错)")
print("-" * 30)
控制台输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
--- 原始字符串 ---
原始字符串 (Unicode): 你好
字符串类型: <class 'str'>
字符数量: 2
------------------------------
--- UTF-8 编码 ---
编码后的字节序列: b'\xe4\xbd\xa0\xe5\xa5\xbd'
字节长度: 6 字节 (每个汉字约3字节)
解码回字符串: 你好
------------------------------
--- GBK 编码 ---
编码后的字节序列: b'\xc4\xe3\xba\xc3'
字节长度: 4 字节 (每个汉字约2字节)
解码回字符串: 你好
------------------------------
--- ASCII 编码(预期失败) ---
ASCII 编码失败: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) (因为中文无法用ASCII表示)
------------------------------
--- Unicode 码点 ---
字符 '你' 的 Unicode 码点 (十进制): 20320
字符 '好' 的 Unicode 码点 (十进制): 22909
------------------------------
--- 错误解码(乱码演示) ---
UTF-8 编码的字节序列: b'\xe4\xbd\xa0\xe5\xa5\xbd'
尝试用 GBK 解码: 浣犲ソ
------------------------------
Process finished with exit code 0
2.Python中的标识符与保留字
在 Python 中,保留字 (Keywords) 是指那些在语言内部已经被赋予了特殊含义和功能的单词。它们是 Python 语法结构的一部分,用于定义语言的控制流(如 if, for)、数据结构(如 class, def)、异常处理(如 try, except)等。由于这些词具有特殊意义,它们不能被程序员用作标识符(即变量名、函数名、类名、模块名或其他对象的名称)。如果尝试将保留字用作标识符,Python 解释器将会报错,因为这会造成语法歧义。
在 Python 中,标识符 (Identifiers) 是程序员为程序中各种“实体”(如变量、函数、类、模块、对象等)定义的名称。它们是你在代码中引用这些实体的方式。
标识符的命名规则: 为了确保标识符的合法性和可读性,Python 强制执行一套严格的命名规则:
- 字母、数字、下划线: 标识符可以由字母(
A-Z,a-z)、数字(0-9)和下划线(_)组成。 - 不能以数字开头: 标识符的第一个字符不能是数字。例如,
1name是非法的,而name1是合法的。这是为了避免与数字常量产生混淆。 - 如上所述,任何保留字都不能用作标识符。这是最基本的限制。
- 严格区分大小: Python 是一种大小写敏感的语言。这意味着
myVar、myvar和MyVar在 Python 中被视为三个完全不同的标识符。例如,True是一个布尔值保留字,而true则不是保留字(虽然不推荐这样做,但它是一个合法的普通标识符)。
【总结】:
- 保留字是语言预留的,具有特殊含义,不能被用作自定义名称。
- 标识符是开发者自定义的名称,用于引用程序中的各个部分,它必须遵循特定的命名规则(由字母、数字、下划线组成,不能以数字开头,不能是保留字,且大小写敏感)。
通过代码查看python中哪些是保留字:
1
2
import keyword
print(keyword.kwlist)
程序输出:
1
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
上面就列举出了python中的全部保留字。
3.Python中的变量与数据类型
(1)变量的定义和使用
变量是内存中一个带标签的盒子,变量由三部分组成
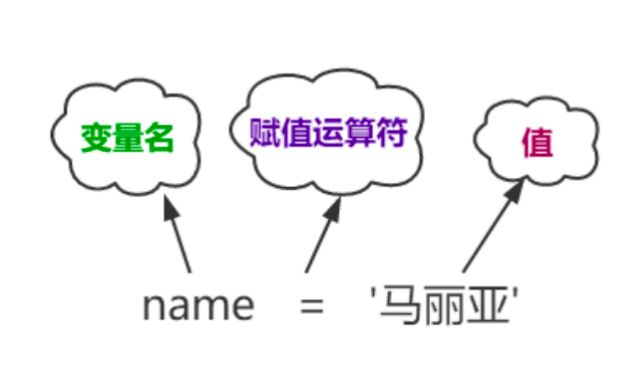
- 标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
- 类型 :表示的是对象的数据类型,使用内置函数type(obj)来获取
- 值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出

1
2
3
4
name = "玛丽亚"
print(id(name)) # 输出:140347147273776
print(type(name)) # 输出:<class 'str'>
print(name) # 输出:玛丽亚
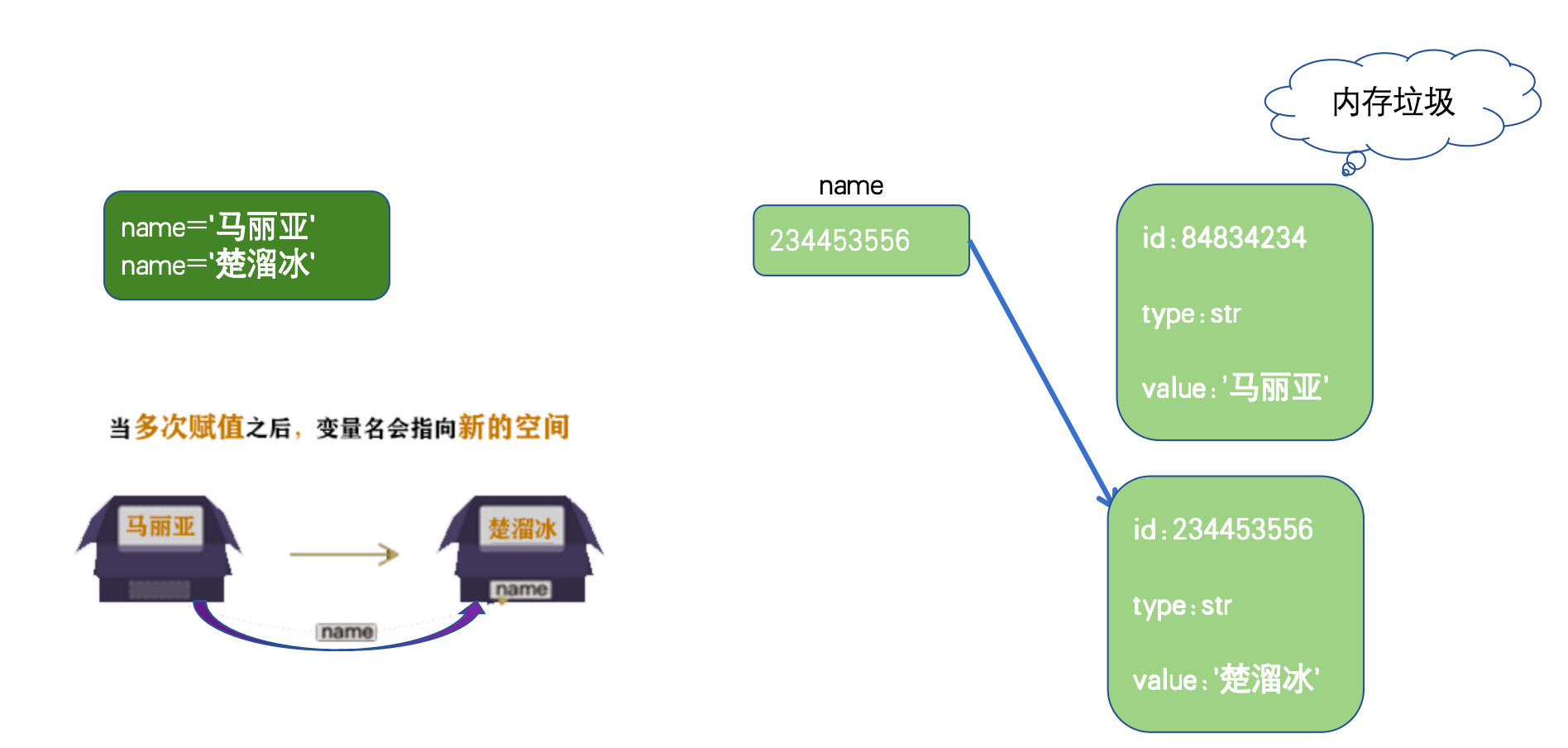
(2)变量的多次赋值
当多次赋值之后,变量名会指向新的空间
1
2
3
4
5
6
7
8
9
name = "玛丽亚"
print(id(name)) # 输出:140263856784944
print(type(name)) # 输出:<class 'str'>
print(name) # 输出:玛丽亚
name = "雷军"
print(id(name)) # 输出:140263911560848
print(type(name)) # 输出:<class 'str'>
print(name) # 输出:雷军
可以发现,重新赋值之后,id也发生了变化。
需要特别注意:
- Python 中的变量是标签(引用),而不是容器。
- 字符串是不可变(immutable)对象。
当执行第二行 name = "雷军" 时,并没有修改之前 "玛丽亚" 那个字符串对象。由于字符串是不可变的,Python 做了以下操作:
- Python 在内存中新创建了一个字符串对象,它存储了
"雷军"这个值。 - 这个新的字符串对象在内存中有一个全新的、不同的地址。
- 然后,
name这个变量(标签)不再指向"玛丽亚"那个旧的字符串对象了,它转而指向了新创建的"雷军"这个字符串对象。
所以,当你再次调用 print(id(name)) 时,它输出的是新的 "雷军" 字符串对象的【内存地址】,这个地址自然与之前 "玛丽亚" 对象的地址不同,因此 id 值发生了变化。
因此,第二个 id 会发生变化,是因为 name = "雷军" 创建了一个全新的字符串对象,并让 name 这个变量指向了它,而不是修改了原来的对象。
当 name 这个变量从指向 "玛丽亚" 的对象转而指向 "雷军" 的新对象之后,如果没有其他任何变量再引用(指向)原来那个 "玛丽亚" 的字符串对象,那么它就变成了一个不可达的对象。
这种不可达的对象在 Python 中通常被称为“垃圾”(虽然这个词听起来不太好听,但在计算机术语中是标准的说法),它们所占用的内存空间就成为了“内存垃圾”。
Python 拥有一个自动内存管理机制,其中一个重要的组成部分就是垃圾回收器 (Garbage Collector, GC)。
垃圾回收器的主要任务就是周期性地(或在内存不足时)检查内存中是否存在不再被任何变量引用的对象。一旦发现这样的对象,它就会将这些对象所占用的内存空间标记为可用,或者直接释放掉这些内存,使其可以被程序中其他部分重新使用。
所以,对于例子中的
"玛丽亚"字符串对象:
- 当
name = "玛丽亚"时,"玛丽亚"对象被创建,并被name引用。- 当
name = "雷军"时,name变量的引用断开,不再指向"玛丽亚"。- 如果此时没有其他变量(例如
old_name = name这种操作)引用"玛丽亚",那么"玛丽亚"对象就变得不可达。- Python 的垃圾回收器会在适当的时候(Python 的 GC 有多种触发机制,例如引用计数归零、分代回收等)识别到
"玛丽亚"是一个不可达对象,并回收它所占用的内存空间。
(3)python中常见的数据类型
【常用的数据类型】
- 整数类型 int
- 浮点数类型float
- 布尔类型 bool —- True ,False
- 字符串类型str
【整数类型】英文为integer,简写为int,可以表示正数、负数和零
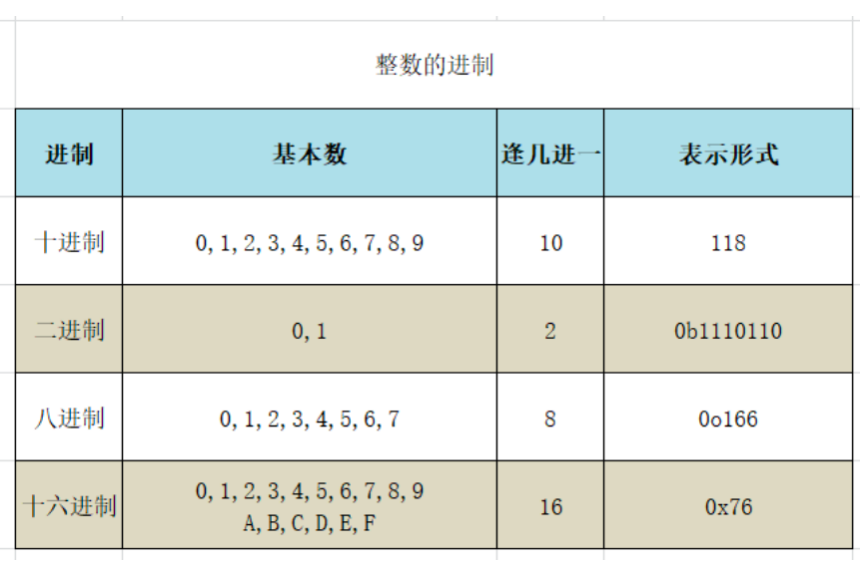
整数的不同进制表示方式
- 十进制:默认的进制
- 二进制:以0b开头
- 八进制:以0o开头
- 十六进制:0x开头
【浮点类型】
浮点数整数部分和小数部分组成
浮点数存储不精确性
使用浮点数进行计算时,可能会出现小数位数不确定的情况
例如:
1
print(1.1 + 2.2) # 输出: 3.3000000000000003
解决方案:导入模块decimal
1
2
3
from decimal import Decimal
# 注意下面的引号不能省略
print(Decimal("1.1") + Decimal("2.2")) # 3.3
为什么print(1.1 + 2.2)
输出3.3000000000000003,而不是精确的3.3?这是一个非常经典且重要的计算机科学问题,它涉及到浮点数(Floating-Point Numbers)在计算机中的表示方式。
计算机使用二进制(0和1)来表示所有数据,而许多十进制小数,例如
0.1、0.2、0.3等,在二进制浮点表示中是无法被精确表示的,它们是无限循环小数。以
0.1为例: 在十进制中0.1是一个有限小数。 但如果尝试用二进制表示0.1,你会发现它是一个无限循环小数: $0.1_{10}=0.00011001100110011…_2$ (这是 1/16+1/32+1/256+1/512+…)同样地,
0.2和0.3在二进制中也是无限循环小数。所以:
1.1在计算机内存中存储的实际上是比1.1略大或略小的一个近似值。2.2在计算机内存中存储的实际上也是比2.2略大或略小的一个近似值。当你将这两个近似值相加时,结果也是另一个近似值。
【布尔类型】用来表示真或假的值
True表示真,False表示假
布尔值可以转化为整数
True:1 False:0
1
2
print(True + 1) # 2
print(False + 1) # 1
【字符串类型】字符串又被称为不可变的字符序列
可以使用单引号’’ 双引号”” 三引号’’’ ’’’ 或””” ”””来定义,单引号和双引号定义的字符串必须在一行,三引号定义的字符串可以分布在连续的多行
(4)数据类型的转换
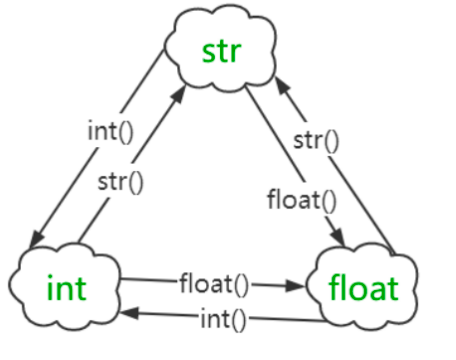
为什么需要数据类型转换?将不同数据类型的数据拼接在一起
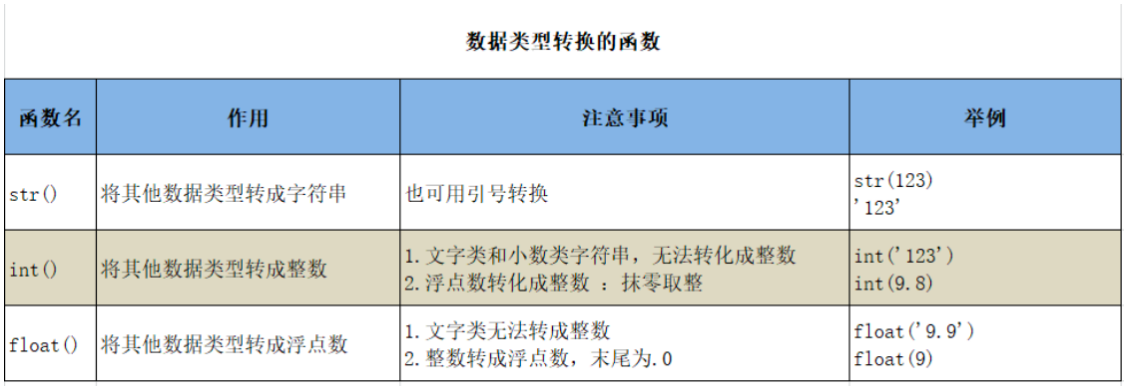
总结几个易错点:
int()截断而非四舍五入 是最常见的错误。- 字符串转换的限制: 只有纯数字组成的字符串(不含小数)才能被
int()转换,含有非数字或小数点的字符串会报错。float()也要求字符串是有效的数字表示。 - 类型匹配: 进行转换时,要清楚目标类型能否容纳源类型的数据,例如,无法将一个非数字字符串转换为数字。
1
2
3
4
5
print(int(9.8)) # 输出9
print(int("9.8")) # 报错
print(float("9.9")) # 输出9.9
print(float(9.9)) # 输出9.9
除了 str(), int(), float()这三个最常用的类型转换函数之外,Python 中还有许多其他的类型转换方式:
bool():转换为布尔值
- 作用: 将任何数据类型转换为布尔值 (
True或False)。 - 规则:
- 数字类型:
0、0.0被视为False,其他任何非零数字(包括负数)都被视为True。 - 字符串:空字符串
''被视为False,任何非空字符串都被视为True。 - 列表、元组、字典、集合:空的序列/集合 (
[],(),{},set()) 被视为False,任何非空的序列/集合都被视为True。 None被视为False。
- 数字类型:
序列类型转换:list(), tuple(), set()
-
作用: 这些函数可以将可迭代对象(如字符串、列表、元组、集合、范围对象等)转换为对应的序列或集合类型。
-
list():将可迭代对象转换为列表。
- 示例:
list("hello")->['h', 'e', 'l', 'l', 'o'] - 示例:
list((1, 2, 3))->[1, 2, 3]
- 示例:
-
tuple():将可迭代对象转换为元组。
- 示例:
tuple([1, 2, 3])->(1, 2, 3) - 示例:
tuple("abc")->('a', 'b', 'c')
- 示例:
-
set():将可迭代对象转换为集合(无序,元素唯一)。
- 易错点: 集合会自动去重,且元素无序。
- 示例:
set([1, 2, 2, 3])->{1, 2, 3} - 示例:
set("hello")->{'h', 'e', 'l', 'o'}(字符顺序不确定)
dict():转换为字典
- 作用: 用于创建字典。最常见的是从键值对的序列(如元组列表)或关键字参数创建字典。
- 示例:
dict([('a', 1), ('b', 2)])->{'a': 1, 'b': 2} - 示例:
dict(a=1, b=2)->{'a': 1, 'b': 2} - 易错点: 传入的序列必须是包含两个元素的子序列(键值对)。
4.Python中的注释
在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性,注释的内容会被Python解释器忽略
通常包括三种类型的注释
单行注释 :以”#”开头,直到换行结束
多行注释 :并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释
中文编码声明注释:在文件开头加上中文声明注释,用以指定源码文件的编码格,例如:# coding:gbk