上一节已经建立了环境:参考博客链接
先通过一个入门案例感受IOC/DI的使用。很久没有用spring了,这个系列作为复习,再体系化学习下。而且spring6出来也好一阵了,没有研究过。
【Spring 6 IOC 入门与自定义容器模拟实现】
一、入门案例代码
之前已经准备好了环境,下面是pom.xml文件,供项目复现参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kirsten</groupId>
<artifactId>IOCProject01</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>IOCProject01</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>6.2.8</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
目前spring6最新的GA版本是6.2.8。
接下来通过实现一个简单的案例,创建Person类,让Spring帮我们管理对象。
首先在java目录下创建一个pojo/Persion.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
package com.kirsten.pojo;
public class Person {
private int age;
private String name;
private double height;
public Person() {
System.out.println("空参构造方法");
}
public Person(int age, String name, double height) {
System.out.println("全参构造方法");
this.age = age;
this.name = name;
this.height = height;
}
// setter与getter方法
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
", height=" + height +
'}';
}
}
准备配置文件:创建resources目录,位置如下图所示;准备一个xml配置文件。
xml配置文件参考spring官网:https://docs.spring.io/spring-framework/reference/core/beans/basics.html#beans-factory-metadata
提供了一个简单的模版。
在resources目录下,创建applicationContext.xml,这个xml文件的名字可以随便取,推荐用这个名字,约定俗成。
1
2
3
4
5
6
7
8
9
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="p" class="com.kirsten.pojo.Person"></bean>
</beans>
注意到:我只修改了 <bean id="p" class="com.kirsten.pojo.Person"></bean>,表示的就是这个bean对应的全限定名(com.kirsten.pojo.Person),spring将在容器启动时实例化这个类的对象,且没有定义其他属性或者嵌套元素,则会按照默认的构造方法(即无参构造方法)实例化对象,采用默认作用域(singleton),即容器中只创建一个该 bean 的实例。这个bean在spring容器中的标识符(即所说的Map的键)是p。
而其他部分,第一行<?xml version="1.0" encoding="UTF-8"?>是指定文件是一个 XML 文档,使用 XML 1.0 版本,并采用 UTF-8 字符编码。beans标签中定义了命名空间和schema。
现在书写以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package com.kirsten;
import com.kirsten.pojo.Person;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
Person person = (Person)ac.getBean("p");
System.out.println(person);
}
}
运行可以看到:

默认调用的是无参构造方法
如果这么写获得对象也可以:
1
Person person1 = ac.getBean("p", Person.class);
而且,还可以验证这是通过单例获得的对象:
1
2
3
4
5
6
7
8
9
10
public class App
{
public static void main( String[] args )
{
ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
Person person1 = ac.getBean("p", Person.class);
Person person2 = (Person) ac.getBean("p");
System.out.println(person1 == person2);
}
}
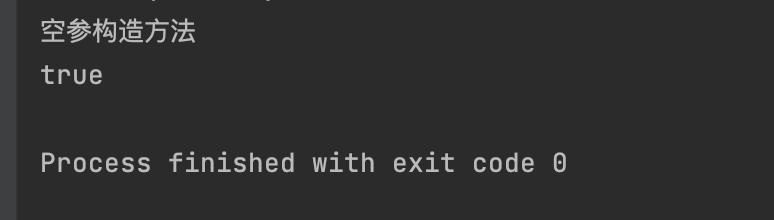
即只是实例化了一次Person类(调用了一次无参构造方法),通过ac.getBean("p", Person.class)和(Person) ac.getBean("p")获得的对象都是同一个。
二、模拟spring容器和bean对象实例化
现在完成一个任务,自己尝试实现IOC/DI的功能,模拟出一个spring容器进行实例化。那么大致的思路就是下面这样:
(1)定义xml文件,里面定义bean标签,因为后续每个bean标签会被解析为一个对象
(2)解析xml文件(dom4j),解析的时候,会解析xml文件中的bean标签,每个bean标签转换为一个bean对象,此对象包含两个属性:id、class,此对象用来存放bean的id和class值。
(3)因为xml文件中bean标签可能是多个,所以定义一个List集合,存储bean对象。
(4)遍历List集合,得到每一个bean对象,通过bean对象的class属性,反射创建对应的对象。
(5)对象创建好以后,将bean对象的id和反射创建的对象,放入map集合中。
(6)定义一个工厂,(2)-(5)步骤放在工厂的构造器中完成
(7)工厂中定义获取对象的方法,通过id从map集合中获取对象。
其中dom4J是常见的用来做xml解析的。
现在新建一个maven项目准备完成上面的任务:
首先引入dom4J和xml的path解析的依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
<!-- dom4j -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<!-- XPath :XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
Jaxen是Java的通用XPath引擎。-->
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.6</version>
</dependency>
准备2个pojo类:Person 和User
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
package com.kirsten.pojo;
public class Person {
private int age;
private String name;
public Person() {
System.out.println("Person 无参构造方法");
}
public Person(int age, String name) {
System.out.println("Person 有参构造方法");
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void eat() {
System.out.println("Person eat方法");
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
package com.kirsten.pojo;
public class User {
private int uid;
private String pwd;
public User() {
System.out.println("User 无参构造方法");
}
public User(int uid, String pwd) {
System.out.println("User 有参构造方法");
this.uid = uid;
this.pwd = pwd;
}
public int getUid() {
return uid;
}
public void setUid(int uid) {
this.uid = uid;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
@Override
public String toString() {
return "User{" +
"uid=" + uid +
", pwd='" + pwd + '\'' +
'}';
}
public void sleep() {
System.out.println("user sleep方法");
}
}
准备一个接口MyFactory,模拟的就是ApplicationContext,再准备一个MyClassPathXmlApplicationContext,去实现MyFactory。
模仿ApplicationContext,刚才写的代码中有getBean方法,传入ID(String类型),返回一个对象,所以在自己定义的MyFactory接口中,也有getBean方法:
1
2
3
4
5
6
7
8
package com.kirsten.mySpringIOC;
/*
相当于Bean的工厂
*/
public interface MyFactory {
public abstract Object getBean(String id);
}
准备类MyClassPathXmlApplicationContext,实现上面的接口。(现在只是简单写个轮廓)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package com.kirsten.mySpringIOC;
public class MyClassPathXmlApplicationContext implements MyFactory{
public MyClassPathXmlApplicationContext(String xmlPath) {
// 解析xml配置文件
parseXml(xmlPath);
// 通过反射构建对象,放入Map集合中
instanceBean();
}
// 通过反射实例化对象
private void instanceBean() {
}
// 将通过xmlPath解析XML文件
private void parseXml(String xmlPath) {
}
// 通过id获取bean对象
@Override
public Object getBean(String id) {
return null;
}
}
准备一个XML配置文件:
1
2
3
4
5
<?xml version="1.0" encoding="utf-8" ?>
<beans>
<bean id="p" class="com.kirsten.pojo.Person"></bean>
<bean id="u" class="com.kirsten.pojo.User"></bean>
</beans>
定义Bean对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
package com.kirsten.mySpringIOC;
public class MyBean {
private String id;
private String clazz;
public MyBean() {
}
public MyBean(String id, String clazz) {
this.id = id;
this.clazz = clazz;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getClazz() {
return clazz;
}
public void setClazz(String clazz) {
this.clazz = clazz;
}
}
解析XML文件
(1)介绍DOM4j
DOM4J是 dom4j.org 出品的一个开源 XML 解析包。DOM4J应用于 Java 平台,采用了 Java 集合框架并完全支持 DOM,SAX 和 JAXP。
DOM4J 使用起来非常简单。只要你了解基本的 XML-DOM 模型,就能使用。
XML-DOM 模型:文档对象模型(DOM)通过将文档的结构(例如表示网页的 HTML)以对象的形式存储在内存中,将网页与脚本或编程语言连接起来。
Dom:把整个文档作为一个对象。
DOM4J 最大的特色是使用大量的接口。它的主要接口都在org.dom4j里面定义:
Attribute 定义了 XML 的属性。 Branch 指能够包含子节点的节点。如XML元素(Element)和文档(Docuemnts)定义了一个公共的行为 CDATA 定义了 XML CDATA 区域 CharacterData 是一个标识接口,标识基于字符的节点。如CDATA,Comment, Text. Comment 定义了 XML 注释的行为 Document 定义了XML 文档 DocumentType 定义 XML DOCTYPE 声明 Element 定义XML 元素 ElementHandler 定义了Element 对象的处理器 ElementPath 被 ElementHandler 使用,用于取得当前正在处理的路径层次信息 Entity 定义 XML entity Node 为dom4j中所有的XML节点定义了多态行为 NodeFilter 定义了在dom4j 节点中产生的一个滤镜或谓词的行为(predicate) ProcessingInstruction 定义 XML 处理指令 Text 定义 XML 文本节点 Visitor 用于实现 Visitor模式 XPath 在分析一个字符串后会提供一个 XPath 表达式 读写XML文档主要依赖于org.dom4j.io包,有DOMReader和SAXReader两种方式。因为利用了相同的接口,它们的调用方式是一样的。
读取指定的xml文件之后返回一个Document对象,这个对象代表了整个XML文档,用于各种Dom运算。
SAX 是一种事件驱动的解析模型,这意味着它会顺序读取 XML 文档,并在遇到不同的 XML 部分时触发事件(比如“元素开始”、“元素结束”、“文本内容”)。Dom4j 库在此基础上构建了一个树状的 Document 对象,使你更容易地导航 XML 内容。
首先,xml配置文件写在classpath路径下,这保证无论应用部署在哪里,只要文件在正确的位置,都能被找到。
我们需要准备一个解析器,用于解析这个xml配置文件,把整个 XML 文件的内容加载到内存中,并将其转换成一个易于操作的树状结构 (Document 对象)。当然也可以指定条件得到相应的标签,在 document 上执行定义的 XPath 表达式,并返回一个 Element 对象列表,其中每个 Element 都代表在 XML 中找到的一个 <bean> 标签。这个XPath表达式就像一个精准的过滤器,可以得到指定的标签。
所以parseXml方法代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private void parseXml(String xmlPath) {
// 创建解析器:
SAXReader saxReader = new SAXReader();
// 得到配置文件的URL对象:
URL url = this.getClass().getClassLoader().getResource(xmlPath);
try {
// 解析器去解析:
Document document = saxReader.read(url);
// 利用xpath或者指定标签下的标签:获得beans下面的bean标签
XPath xPath = document.createXPath("beans/bean");
// 返回标签的对象:
List<Element> list = xPath.selectNodes(document);
// 遍历查看Element
for (Element element : list) {
System.out.println(element + "--------->");
}
} catch (DocumentException e) {
throw new RuntimeException(e);
}
}
在MyClassPathXmlApplicationContext的无参构造方法中调用parseXml方法。现在进行测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package com.kirsten;
import com.kirsten.mySpringIOC.MyClassPathXmlApplicationContext;
import com.kirsten.mySpringIOC.MyFactory;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
// 构建工厂对象:
MyFactory factory = new MyClassPathXmlApplicationContext("applicationContext.xml");
}
}
控制台输出如下内容:
1
2
org.dom4j.tree.DefaultElement@2b80d80f [Element: <bean attributes: [org.dom4j.tree.DefaultAttribute@3ab39c39 [Attribute: name id value "p"], org.dom4j.tree.DefaultAttribute@2eee9593 [Attribute: name class value "com.kirsten.pojo.Person"]]/>]--------->
org.dom4j.tree.DefaultElement@7907ec20 [Element: <bean attributes: [org.dom4j.tree.DefaultAttribute@546a03af [Attribute: name id value "u"], org.dom4j.tree.DefaultAttribute@721e0f4f [Attribute: name class value "com.kirsten.pojo.User"]]/>]--------->
所以继续完善parseXml方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 将通过xmlPath解析XML文件
private void parseXml(String xmlPath) {
// 创建解析器:
SAXReader saxReader = new SAXReader();
// 得到配置文件的URL对象:
URL url = this.getClass().getClassLoader().getResource(xmlPath);
try {
// 解析器去解析:
Document document = saxReader.read(url);
// 利用xpath或者指定标签下的标签:获得beans下面的bean标签
XPath xPath = document.createXPath("beans/bean");
// 返回标签的对象:
List<Element> list = xPath.selectNodes(document);
// 如果list != null 且其中有bean标签
if (list != null && list.size() > 0) {
for (Element element : list) {
// 读取bean标签 id和class属性的属性值
String id = element.attributeValue("id");
String clazz = element.attributeValue("class");
// 封装成MyBean对象
MyBean bean = new MyBean(id, clazz);
// 存储到list中(类的成员变量):List<MyBean> beanList = new ArrayList<>();
beanList.add(bean); // 后续创建对象要用到这个list
}
}
} catch (DocumentException e) {
throw new RuntimeException(e);
}
}
目前这一步骤形成的MyClassPathXmlApplicationContext类,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
package com.kirsten.mySpringIOC;
import org.dom4j.*;
import org.dom4j.io.SAXReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
public class MyClassPathXmlApplicationContext implements MyFactory{
List<MyBean> beanList = new ArrayList<>();
public MyClassPathXmlApplicationContext(String xmlPath) {
// 解析xml配置文件
parseXml(xmlPath);
// 通过反射构建对象,放入Map集合中
instanceBean();
}
// 通过反射实例化对象
private void instanceBean() {
}
// 将通过xmlPath解析XML文件
private void parseXml(String xmlPath) {
// 创建解析器:
SAXReader saxReader = new SAXReader();
// 得到配置文件的URL对象:
URL url = this.getClass().getClassLoader().getResource(xmlPath);
try {
// 解析器去解析:
Document document = saxReader.read(url);
// 利用xpath或者指定标签下的标签:获得beans下面的bean标签
XPath xPath = document.createXPath("beans/bean");
// 返回标签的对象:
List<Element> list = xPath.selectNodes(document);
// 如果list != null 且其中有bean标签
if (list != null && list.size() > 0) {
for (Element element : list) {
// 读取bean标签 id和class属性的属性值
String id = element.attributeValue("id");
String clazz = element.attributeValue("class");
// 封装成MyBean对象
MyBean bean = new MyBean(id, clazz);
// 存储到list中(类的成员变量):List<MyBean> beanList = new ArrayList<>();
beanList.add(bean); // 后续创建对象要用到这个list
}
}
} catch (DocumentException e) {
throw new RuntimeException(e);
}
}
// 通过id获取bean对象
@Override
public Object getBean(String id) {
return null;
}
}
(2)通过反射构建对象
现在完善instanceBean方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 通过反射实例化对象
private void instanceBean() {
if (beanList != null && beanList.size() > 0) {
// 遍历,得到每个bean的clazz属性,用这个属性反射,创建对象,然后存到Map中
for (MyBean bean : beanList) {
try {
Object ob = Class.forName(bean.getClazz()).newInstance();
map.put(bean.getId(), ob);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
}
然后getBean方法也可以完善为:
1
2
3
4
5
// 通过id获取bean对象
@Override
public Object getBean(String id) {
return map.get(id);
}
此时完整的MyClassPathXmlApplicationContext代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
package com.kirsten.mySpringIOC;
import org.dom4j.*;
import org.dom4j.io.SAXReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MyClassPathXmlApplicationContext implements MyFactory{
List<MyBean> beanList = new ArrayList<>();
Map<String, Object> map = new HashMap();
public MyClassPathXmlApplicationContext(String xmlPath) {
// 解析xml配置文件
parseXml(xmlPath);
// 通过反射构建对象,放入Map集合中
instanceBean();
}
// 通过反射实例化对象
private void instanceBean() {
if (beanList != null && beanList.size() > 0) {
// 遍历,得到每个bean的clazz属性,用这个属性反射,创建对象,然后存到Map中
for (MyBean bean : beanList) {
try {
Object ob = Class.forName(bean.getClazz()).newInstance();
map.put(bean.getId(), ob);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
}
// 将通过xmlPath解析XML文件
private void parseXml(String xmlPath) {
// 创建解析器:
SAXReader saxReader = new SAXReader();
// 得到配置文件的URL对象:
URL url = this.getClass().getClassLoader().getResource(xmlPath);
try {
// 解析器去解析:
Document document = saxReader.read(url);
// 利用xpath或者指定标签下的标签:获得beans下面的bean标签
XPath xPath = document.createXPath("beans/bean");
// 返回标签的对象:
List<Element> list = xPath.selectNodes(document);
// 如果list != null 且其中有bean标签
if (list != null && list.size() > 0) {
for (Element element : list) {
// 读取bean标签 id和class属性的属性值
String id = element.attributeValue("id");
String clazz = element.attributeValue("class");
// 封装成MyBean对象
MyBean bean = new MyBean(id, clazz);
// 存储到list中(类的成员变量):List<MyBean> beanList = new ArrayList<>();
beanList.add(bean); // 后续创建对象要用到这个list
}
}
} catch (DocumentException e) {
throw new RuntimeException(e);
}
}
// 通过id获取bean对象
@Override
public Object getBean(String id) {
return map.get(id);
}
}
运行测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package com.kirsten;
import com.kirsten.mySpringIOC.MyClassPathXmlApplicationContext;
import com.kirsten.mySpringIOC.MyFactory;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
// 构建工厂对象:
MyFactory factory = new MyClassPathXmlApplicationContext("applicationContext.xml");
}
}
控制台得到输出:
1
2
Person 无参构造方法
User 无参构造方法
成功通过反射获取到了对象。现在可以得到对象,且调用对象的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package com.kirsten;
import com.kirsten.mySpringIOC.MyClassPathXmlApplicationContext;
import com.kirsten.mySpringIOC.MyFactory;
import com.kirsten.pojo.Person;
import com.kirsten.pojo.User;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
// 构建工厂对象:
MyFactory factory = new MyClassPathXmlApplicationContext("applicationContext.xml");
// 得到对象:
Person person = (Person)factory.getBean("p");
User user = (User)factory.getBean("u");
// 调用对象的方法:
person.eat();
user.sleep();
}
}
测试结果:
